foundation专题
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模
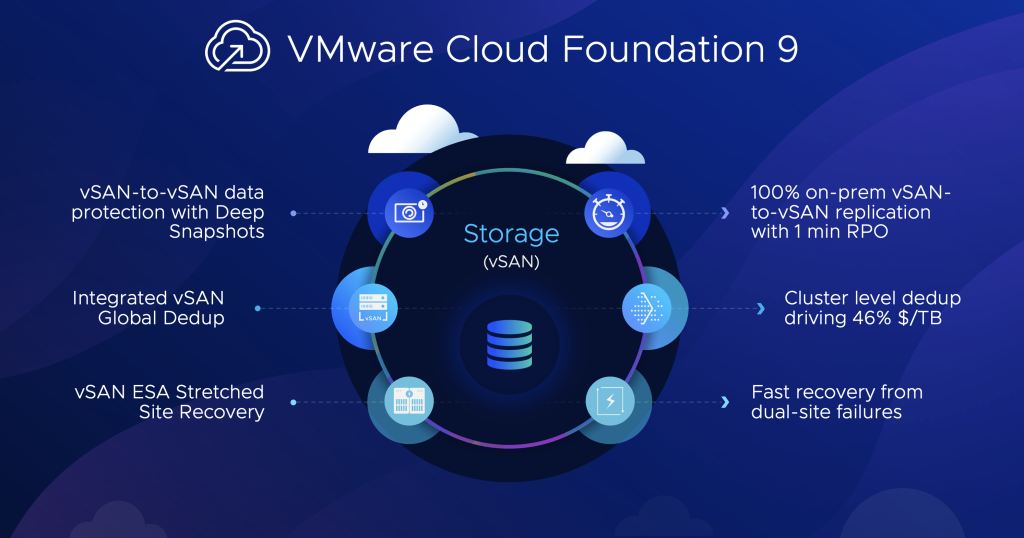
VMware Cloud Foundation 9 发布 - 领先的多云平台
VMware Cloud Foundation 9 发布 - 领先的多云平台 高效管理虚拟机 (VM) 和容器工作负载,为本地部署的全栈超融合基础架构 (HCI) 提供云的优势。 请访问原文链接:https://sysin.org/blog/vmware-cloud-foundation-9/,查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org VMware Clou


Code Llama: Open Foundation Models for Code论文阅读
整体介绍 Code Llama 发布了3款模型,包括基础模型、Python 专有模型和指令跟随模型,参数量分别为 7B、13B、34B 和 70B。这些模型在长达 16k tokens 的序列上训练。都是基于 Llama 2。 作者针对infilling (FIM) 、长上下文、指令专门做了微调 long-context fine-tuning (LCFT). codellama细节 C
【Foundation-10-2】#import Foundation/NSArray.h
@interface NSArray (NSArrayCreation) 类方法 + (instancetype)array; + (instancetype)arrayWithObject:(id)anObject; + (instancetype)arrayWithObjects:(const id [])objects count:(NSUInteger)
【Foundation-10-1】#import Foundation/NSArray.h
@interface NSArray : NSObject <NSCopying, NSMutableCopying, NSSecureCoding, NSFastEnumeration> @property (readonly) NSUInteger count; // 数组数量 - (id)objectAtIndex:(NSUInteger)index; // 数组某

【Foundation-86-3】#import Foundation/NSValue.h 初始化
@interface NSNumber : NSValue - (instancetype)initWithCoder:(NSCoder *)aDecoder NS_DESIGNATED_INITIALIZER; //实例方法 初始化 - (NSNumber *)initWithChar:(char)value NS_DESIGNATED_INITIALIZE
【Foundation-86-2】#import Foundation/NSValue.h
@interface NSValue (NSValueExtensionMethods) // 封装 弱引用的类(不知道用那里)0.0 + (NSValue *)valueWithNonretainedObject:(id)anObject; @property (nonatomic, readonly) id nonretainedObjectValue;
【Foundation-86-1】#import Foundation/NSValue.h基础创建
"一个NSValue对象是用来存储一个C或者Objective-C数据的简单容器。它可以保存任意类型的数据,比如int,float,char,当然也可以是指pointers, structures, and object ids。NSValue类的目标就是允许以上数据类型的数据结构能够被添加到集合里,例如那些需要其元素是对象的数据结构,如NSArray或者NSSet的实例。需要注意的是NSV
【Foundation-62-1】#import Foundation/NSRange.h范围
// NSRange 的结构体 typedef struct _NSRange { NSUInteger location; NSUInteger length; } NSRange; NSRange theRange = NSMakeRange(2, 4);NSUInteger loc = theRange.location; // 起始位置
【Foundation-37-2】#import Foundation/NSIndexSet.h可变索引集合
@interface NSMutableIndexSet : NSIndexSet { @protected void *_reserved; } - (void)addIndexes:(NSIndexSet *)indexSet; // 添加集合 - (void)removeIndexes:(NSIndexSet *)indexSet; //
【Foundation-37-1】#import Foundation/NSIndexSet.h不可索引集合
NSIndexSet 用来让你从某个 data structure 里面提取一部分东西出来成为一个新的东西。 比如你有一个 NSArray, 里面是 (one, two, three, four, five) 然后你造了个 indexSet 的内容是 0,1,2,4 然后你把它套到那个 array 上,就是 (one, two,three,five) @int
【Foundation-36-1】#import Foundation/NSIndexPath.h树结构
NSIndexPath 让你精确指定一个树结构 data structure 里面的某个节点的数据 比如你有一个 NSArray, 里面很多节点,每个节点又是一个 NSArray,每个节点的这个里面又是一个NSArray,然后下面又是一个 NSArray 这样简单说起来,你有一个四层的 NSarray ,每层下面都有好多个 NSArray。 然后你造一个 NSIndexPath

【从Qwen2,Apple Intelligence Foundation,Gemma 2,Llama 3.1看大模型的性能提升之路】
从早期的 GPT 模型到如今复杂的开放式 LLM,大型语言模型 (LLM) 的发展已经取得了长足的进步。最初,LLM 训练过程仅侧重于预训练,但后来扩展到包括预训练和后训练。后训练通常包括监督指令微调和校准,这是由 ChatGPT 推广的。 自 ChatGPT 首次发布以来,训练方法已不断发展。在本文中,我回顾了训练前和训练后方法的最新进展,特别是最近几个月取得的进展。 概述 LLM 开发和培
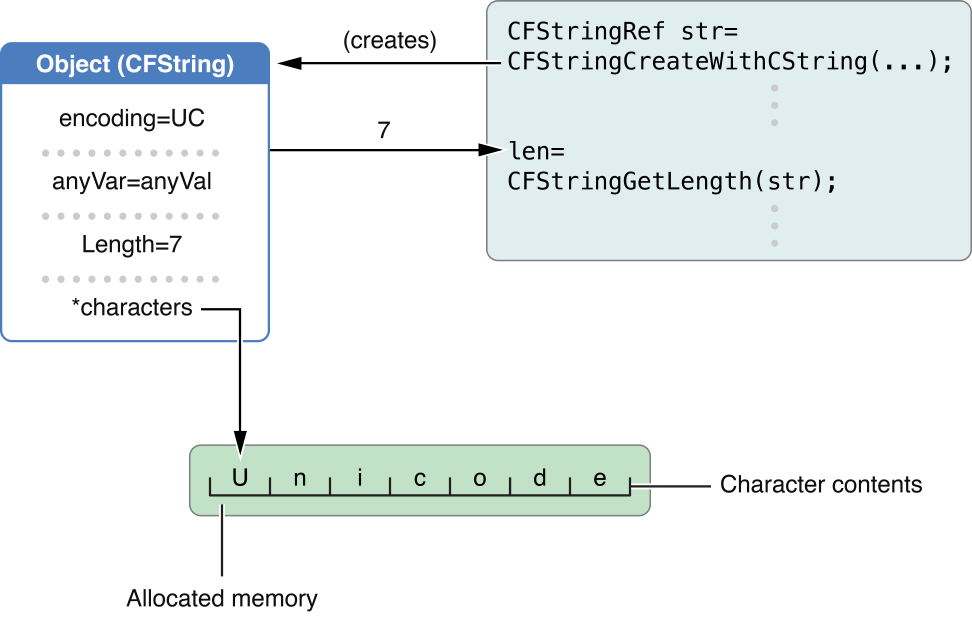
Apple - Core Foundation Design Concepts
本文翻译整理自:Core Foundation Design Concepts(更新日期:2013-12-16 https://developer.apple.com/library/archive/documentation/CoreFoundation/Conceptual/CFDesignConcepts/CFDesignConcepts.html#//apple_ref/doc/uid/1

SharePoint 创建列表并使用Windows Presentation Foundation应用程序管理列表
SharePoint创建列表并使用程序管理列表 列表是SharePoint开发人员输入数据的方式之一。使用Web界面创建一个列表并添加一些数据,步骤如下: 1. 打开站点。 2. 点击所有网站内容。 3. 点击创建。 4. 选择自定义列表,命名Customers,并输入描述。选中在快速启动导航显示,点击创建。 这将创建一个自定义列表。接下来我们添加三个栏:Regio
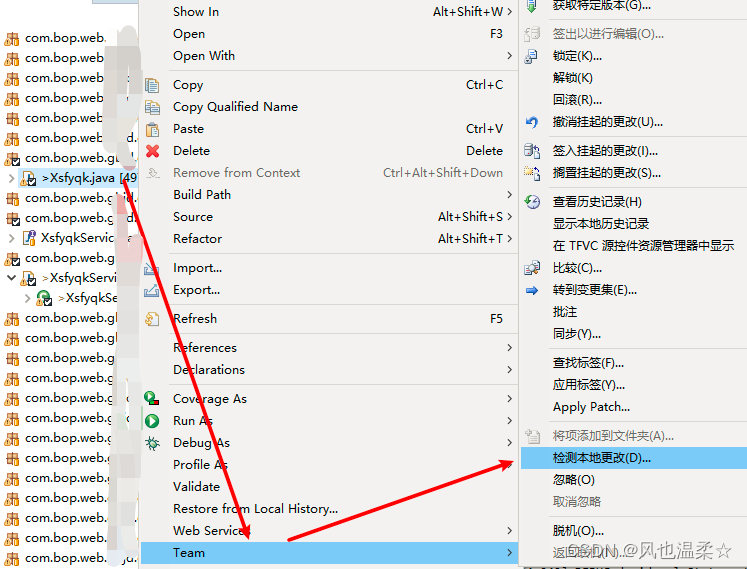
Eclipse使用TFS(Team Foundation Server) 超详细
Eclipse使用TFS 1、什么是TFS2、TFS和Git的区别3、签出代码4、签入代码4.1、签出以进行编辑4.2、修改本地代码4.3、签入挂起的更改4.4、签入 如果不能 签入挂起的更改,则先 签出以进行编辑如果 签入挂起的更改不可选中,则 如下操作 1、什么是TFS Team Foundation Server集中式版本控制系统TFS是一种为Microsoft产品提供源代

《A DECODER-ONLY FOUNDATION MODEL FOR TIME-SERIES FORECASTING》阅读总结
介绍了一个名为TimeFM的新型时间序列预测基础模型,该模型受启发于自然语言处理领域的大语言模型,通过再大规模真实世界和合成时间序列数据集上的预训练,能够在多种不同的公共数据集上实现接近最先进监督模型的零样本预测性能。 该模型使用真实世界和合成数据集构建的大型时间序列语料库进行预训练,并展示了在不同领域、预测范围和时间粒度的未见数据集上的准确零样本预测能力。 1、引言 时间序列在零售、金融、

ViNT: A Foundation Model for Visual Navigation
介绍 现存的问题:预训练的方式在很多领域取得了成功,但是由于环境、平台和应用程序的绝对多样性,因此很难应用在机器人领域。 那么想要做移动机器人的基础模型需要什么? 本文定义了一个机器人领域的基础模型,可以实现(1)在新的、有用的环境里进行零样本学习;(2)适应所选择的下游任务。 在视觉导航中,机器人必须完全使用以自我为中心的视觉观察来导航环境。一个通用的预先训练的机器人导航模型应该能够实现

《Foundation 文本》
《Foundation 文本》 引言 《Foundation 文本》是一个虚构的概念,它可能指的是与《Foundation》系列相关的文学作品、文本分析或者某种特定的文本集合。在这里,我们将探讨这个概念可能涉及的不同方面,包括它与著名科幻作家艾萨克·阿西莫夫(Isaac Asimov)的《Foundation》系列小说的关系,以及它在文学分析和文本研究中的潜在应用。 《Foundation》
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读 导读:本文提出了一种名为TimesFM的时序基础模型,用于零样本学习模式下的时序预测任务。 背景痛点:近年来,深度学习模型在有充足训练数据的情况下已成为时序预测的主流方法,但这些方法通常需要独立在每个数据集上训练。同时,自然语言处理领域的大规模预训练
Foundation Model 通用大模型的评测体系
随着大模型评测需求逐渐增加,相关研究也进一步深入。大模型相比传统模 型,泛化能力更强、灵活性更高、适应性更广,多任务、多场景,评测维度、评测指标和数 据集更复杂,面向大模型的评估方法、评测基准、测试集成为新的研究课题。 大模型评测对于推动人工智能技术的发展具有重要的意义。一方面,通过对大模型性能 的评测,可以为模型优化和改进提供有力依据,从而提高其应用效果和商业价值。另一方面, 大模型评测可
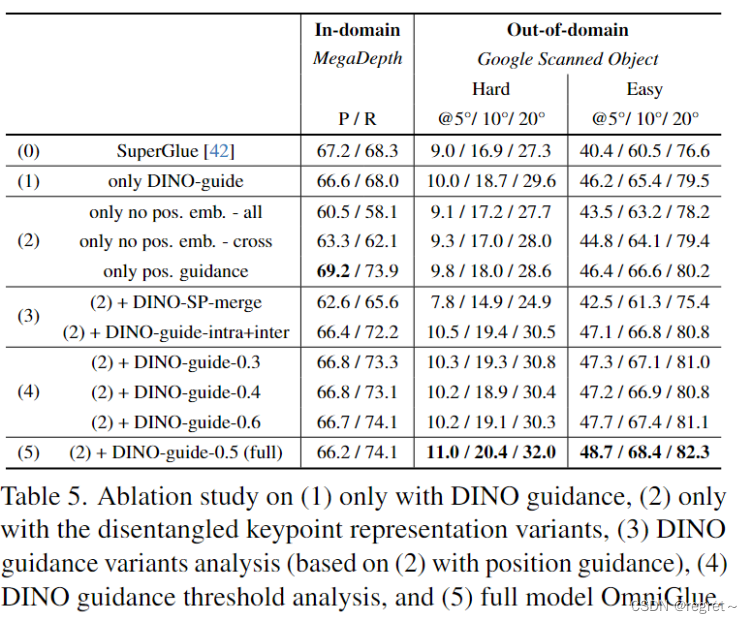
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
【引用格式】:Jiang H, Karpur A, Cao B, et al. OmniGlue: Generalizable Feature Matching with Foundation Model Guidance[J]. arXiv preprint arXiv:2405.12979, 2024. 【网址】:https://arxiv.org/pdf/2405.12979 【开源代码
《Foundation CSS 参考手册》
《Foundation CSS 参考手册》 引言 Foundation 是一个强大的前端框架,它为开发者提供了一系列的CSS工具和组件,以便快速构建响应式、移动优先的网站。本参考手册旨在为那些希望深入了解和使用Foundation CSS的开发者提供一个全面的指南。 基础知识 1. 安装 Foundation 可以通过多种方式安装,包括npm、Bower或直接下载。对于大多数项目,推荐使

计算机视觉与深度学习 | TensorMask: A Foundation for Dense Object Segmentation(何凯明团队新作)近5年目标检测综述
博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 =================================================== https://github.com/MichaelBeechan/tf-faster-rcnn TensorMask:
Front end foundation course 2(html2)
HTML tags part 2 imgsrcaltheightwidthformactionmethodfieldsetlegendbuttonlabelinputcheckboxradiotextbuttonresetdate, url, color, email ... e.t.c [HTML5]textareaselectoptiontabletheadtbodytfoottrthtdc