本文主要是介绍ViNT: A Foundation Model for Visual Navigation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
现存的问题:预训练的方式在很多领域取得了成功,但是由于环境、平台和应用程序的绝对多样性,因此很难应用在机器人领域。
那么想要做移动机器人的基础模型需要什么?
本文定义了一个机器人领域的基础模型,可以实现(1)在新的、有用的环境里进行零样本学习;(2)适应所选择的下游任务。
在视觉导航中,机器人必须完全使用以自我为中心的视觉观察来导航环境。一个通用的预先训练的机器人导航模型应该能够实现广泛的导航应用,容易地对下游任务进行微调,并推广到广泛的环境和机器人平台。
解决方案:本文提出ViNT(visual navigation transformer):一个跨具身的视觉导航基础模型,有很强的泛化能力。(1)训练了一个目标导航智能体,提供了一个能够适应在任意智能体数据集的预训练目标;(2)使用diffusion模型去搜索短视的目标,并且可以在新的环境下进行导航;(3)执行室内的mapping,可以在无干预的情况下在千米范围的室外环境中进行导航;(4)在少量数据集上微调,然后迁移到新的任务中,并且实现很高的性能;(5)定性分许了ViNT的一些突发行为,如隐含偏好和围绕动态行人的导航。

相关工作
在现有的工作中,相似机器人之间的数据共享可以为更通用的模型提供更大的训练集;但是对于不相似的机器人,只能从单个针对的小的真实数据集或者虚拟环境中进行训练。本文从收集的多个数据集上训练导航智能体,专注于训练一个基础模型,可以适应于零样本或者少量数据的各种下游任务。
我们使用组合的拓扑图来表示维护环境的空间表示,并且对low-level控制学习策略。但是与以往工作不同,我们的目标时训练一个单个的通用模型,并不针对具体的问题进行解决,而是让单一的模型适应于不同的任务。
与ViNT相关的工作有RT-1、I2O和GNM。RT-1在遵循不同指令方面表现出令人印象深刻的性能,但我们的重点是通过使用少量数据进行微调,使单一模型在许多机器人上适应不同的任务。I2O显示了从模拟到真实世界环境的令人印象深刻的转变,但我们强调,我们的目标与具体的算法选择是正交的:我们专注于学习能够有效适应于解决不同下游任务的有能力的导航策略。GNM演示了从异类RGB数据集进行策略学习,但重点关注在零镜头设置中实现图像目标的单一任务。相反,ViNT训练了一个通用模型,重点是适应下游应用中的新的任务。
ViNT模型
我们的模型针对图像的目标导航进行训练。在图像目标导航中,机器人的任务是导航到图像所表示的目标位置。可以利用包含视频和动作的任何数据,不需要ground-truth定位、语义标签或者其他元数据,以最小的假设训练模型用于图像目标导航。这使得在来自许多不同机器人的大型且多样化的数据集上进行训练是可行的,从而促进了广泛的泛化。
模型输入:当前和过去的视觉观测,目标图像
。
模型预测:(1)到达目标所需的时间步数(动态距离);(2)到达目标的长度为H的动作序列。
我们的模型建立在Transformer架构上,有31M的参数,可以实现:(1)对资源受限的机器人进行快速高效的推理;(2)针对下游任务进行提示和微调的能力。
我们从头开始训练网络,并且根据Eqn 1中的训练目标对它们进行端到端的训练。
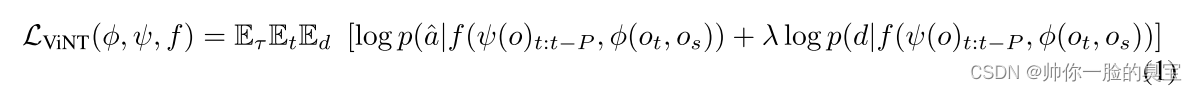
图2为模型框架图

Tokenization
观测图像:5个过去观测+1个当前观测,p*3*85*64
目标图像:目标图像+当前观测,6*85*64
EfficientNet-B0卷积编码器:18层,从头开始初始化,将观测的图像和目标图像都token化为512维。VINT通过用EfficientNet-B0[34]模型对当前和P=5个过去的视觉观测进行编码来独立地对它们进行标记化,该模型将85×64×3图像作为输入,并从最终卷积层输出拉平的特征向量。
拼接后的维度是(P+2,512)

Goal Fusion
仅用编码器提取目标图像的特征,会导致性能较差,通常会完全的忽略目标。
我们假设,基于图像的目标导航任务的有效特征通常是相对的,编码当前观察和目标之间的差异,而不是目标本身的绝对表征。因此,我们使用单独的目标融合编码器来联合编码当前观测和目标观测。我们沿着通道维度堆叠两个图像,将它们通过第二个EfficientNet-B0编码器,然后展开以获得目标token。

late fusion:独立的抽取观测特征和目标特征,并将它们融合在多头注意力层中。为了达到这种效果,我们在将观察图像和目标图像输入到模型中之前,避免了它们之间的任何通道级联。
early fusion:联合提取每一步的观测特征和目标特征,并在token之前对观测和目标特征进行融合。我们通过将目标图像与沿通道维度的每个观测图像连接来实现这一点。我们在此设置中删除了目标token,因为有关目标的信息已经存在于每个观察token中。
film(RT-1):先分别对每个观测图像进行编码。为了以视觉目标为条件,我们用EfficientNet编码器取代了“通用句子编码器”。我们在此设置中删除了目标token,因为有关目标的信息已经存在于每个观察token中。

early fusion:适合核心的导航任务,但是不支持下游适应。
late fusion:适合适应,但是在我们的任务表现不好
表5总结了我们的观察结果。虽然film对语言很有效,但我们发现,对于基于图像的导航任务,训练是不稳定的。相反,我们直接独立地对每个观察结果进行编码,并将它们传递给Transformer。理想情况下,目标将被单独编码,然后与Transformer层中的观察结果相结合,从而允许稍后将整个目标编码器替换为不同的目标模式。不幸的是,我们发现这种方法(即late fusion,因为目标和观测直到编码后才被融合)表现不佳:在基于图像的导航中,重要的是观测图像和目标图像之间的相对特征,而不是绝对目标特征。“early fusion” 结构将目标图像与所有过去和当前的观测图像立即融合,这允许学习目标图像和当前状态之间的联合特征。然而,这种体系结构是不灵活的,因为在适应新的目标模式时,观察编码器必须完全从头开始学习。ViNT通过使用两种不同类型的编码器来避免这个问题:仅用于标记每个观测图像的观测编码器,以及应该提取相对目标特征的联合观测/目标编码器。这样的设计可以替换后一种编码器,以允许在下游任务中使用替代目标规格。具体地说,我们通过学习以新任务目标信息为条件的最终token来适应新任务,而不是联合观测/目标编码器。
Transformer
transformer的输入:[(P+2),512]的token,位置编码
这里的transformer仅仅使用transformer的解码器部分,多头注意力块为4个头,2048个隐藏单元。
Training objective
在训练过程中,从数据集中采样一小部分轨迹。然后选择P个连续的观测形成时间上下文
,并且随机的选择一个未来的观测
,其中d为从
均匀采样得到的,作为最后的目标。
对应未来的H个动作:和距离d用作标签,并用最大似然目标进行训练:
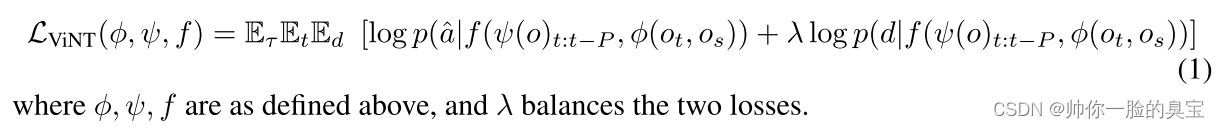
Embodiment-agnostic action space
为了有效地在不同大小、速度和动力学的机器人之间训练单一模型,我们遵循了Shah等人的做法[19]并为Vint选择一个与具体情况无关的动作空间。为了抽象出底层控制,VINT使用相对路点作为其动作空间aˆ;为了解决机器人速度和大小的巨大差异,我们根据机器人的最高速度对这些路点进行归一化。在部署过程中,机器人专用控制器被用来通过低级控制对这些路点进行非标准化和跟踪。
Training data
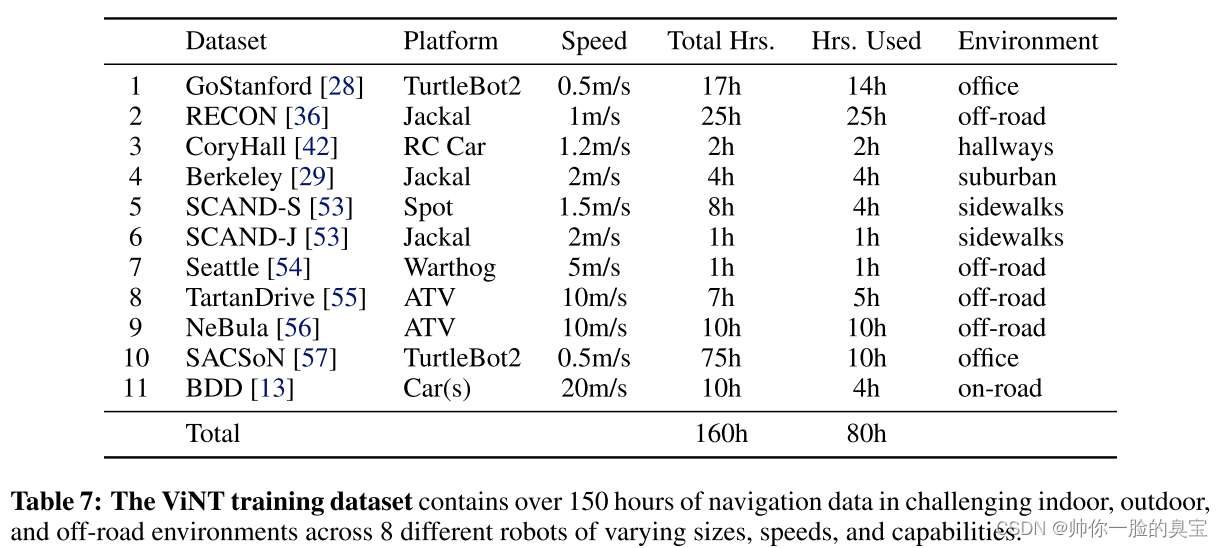
我们使用来自不同环境和机器人平台的不同导航轨迹的大规模数据集来训练Vint,这些环境和机器人平台具有不同的动力学、相机参数和行为。训练数据集包含100多个小时的真实世界轨迹,完全来自现有的数据集,跨越8个不同的机器人平台,具有不同的速度和动力学。
Deployment
ViNT可以在任何配备了机载摄像头和低速跟踪控制器的机器人上运行。在给定时间t的子目标图像S的情况下,我们以4 Hz的频率运行模型,并使用PD控制器以滚动的方式跟踪预测的路点ˆa。
ViNT的长视导航
很多的实际任务本身并不是由目标图像定义的,或者需要比Vint直接支持的范围长得多的视野。我们将VINT与由拓扑图形成的情节记忆相结合,将ViNT应用于几个下游应用,该记忆为到达遥远位置提供了短期子目标。
在以前未见过的环境中,我们可以用探索性的子目标proposal进一步增强这个基于图的规划器,这可以驱动ViNT探索新的环境并发现一条通向目标的道路。我们考虑了多个proposal机制,并发现图像扩散模型可以获得最大性能,该模型以当前观测为条件对不同的未来子目标候选进行采样。
这些子目标使用目标导向的启发式方法进行评分,以确定哪个子目标能够最有效地向最终目标前进。这一过程类似于物理上的A*搜索算法。(子目标评分)
环境中的历史观察和未探索的前沿被存储为拓扑图中的节点,这些节点的连接性由ViNT预测的距离决定。在探索过程中,当机器人探索环境时,我们实时构建这个拓扑图。(动态构建拓扑图)
在后续的部署中,我们使用构建好的拓扑图来发现环境中的捷径,从而提高导航效率。(后续优化)

ground的含义:将探索目标与物理空间位置对齐或者关联,确保模型生成的目标不仅在概念上有意义,而且在实际操作中也能够被执行,即,确保机器人能够将生成的探索目标转换为实际的运动路径和位置。
High-level planning and exploration
这部分描述了如何在未知环境中使用拓扑图和启发式搜索策略来进行导航。
子目标候选集
首先假设有一组子目标候选集可供 ViNT 进行规划。通过这些子目标候选集,将它们整合到一个探索框架中,用于在新环境中的目标导向探索。用户提供一个高层次的目标G,该目标可以距离很远。
拓扑图构建
拓扑图M在线构建,作为情景记忆,每个节点代表一个独立的子目标观测,边代表两个子目标之间的路径。边的添加发生在机器人执行路径时,或者模型预测一个子目标可以从另一个节点到达。
搜索框架
将目标导向的探索框架转化为搜索问题,其中机器人在搜索目标的同时逐步构建拓扑图M。
启发式搜索

部署过程


Subgoal generation with diffusion
这一部分描述了如何使用扩散模型生成多样化的子目标候选,然后利用 ViNT 模型对这些子目标进行空间锚定,以便在物理搜索算法中应用。

diffusion的细节
在5-20个时间步之间选择子目标图像
通过使用图像到图像的扩散模型,可以有效生成多样化且可到达的子目标候选图像。结合连续时间扩散公式和 classifier-free guidance 技术,生成的子目标在视觉保真度上得到了显著提升。这些生成的子目标为进一步的导航和探索提供了多样化的候选,有助于提高物理搜索算法的整体性能。
ViNT:一个面向下游任务的基础模型
这一部分详细描述了如何对 ViNT 模型进行全模型微调和适应新模态,以增强其在不同任务和环境中的应用能力。
full model fine-tuning
使用相同的目标,但基于任务数据进行微调。这使得 ViNT 能够快速学习新技能,形成一个不断改进的模型。
Adapting to new modalities
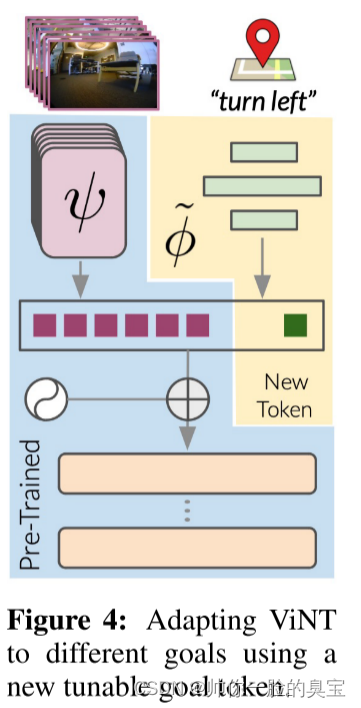
修改目标部分的token类型
Real-world Evaluation
Q1:ViNT 能否有效探索之前未见过的环境并整合启发式方法?


Q2:ViNT 能否泛化到新的机器人、环境和障碍?
Q3:ViNT 能否通过微调来改善在分布外环境中的性能?
Q4:ViNT 策略能否适应新的任务规范和模态?



这篇关于ViNT: A Foundation Model for Visual Navigation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[VC] Visual Studio中读写权限冲突](/front/images/it_default2.jpg)
