model专题

Pydantic中model_validator的实现
《Pydantic中model_validator的实现》本文主要介绍了Pydantic中model_validator的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价... 目录引言基础知识创建 Pydantic 模型使用 model_validator 装饰器高级用法mo

GORM中Model和Table的区别及使用
《GORM中Model和Table的区别及使用》Model和Table是两种与数据库表交互的核心方法,但它们的用途和行为存在著差异,本文主要介绍了GORM中Model和Table的区别及使用,具有一... 目录1. Model 的作用与特点1.1 核心用途1.2 行为特点1.3 示例China编程代码2. Tab
MVC(Model-View-Controller)和MVVM(Model-View-ViewModel)
1、MVC MVC(Model-View-Controller) 是一种常用的架构模式,用于分离应用程序的逻辑、数据和展示。它通过三个核心组件(模型、视图和控制器)将应用程序的业务逻辑与用户界面隔离,促进代码的可维护性、可扩展性和模块化。在 MVC 模式中,各组件可以与多种设计模式结合使用,以增强灵活性和可维护性。以下是 MVC 各组件与常见设计模式的关系和作用: 1. Model(模型)

diffusion model 合集
diffusion model 整理 DDPM: 前向一步到位,从数据集里的图片加噪声,根据随机到的 t t t 决定混合的比例,反向要慢慢迭代,DDPM是用了1000步迭代。模型的输入是带噪声图和 t,t 先生成embedding后,用通道和的方式加到每一层中间去: 训练过程是对每个样本分配一个随机的t,采样一个高斯噪声 ϵ \epsilon ϵ,然后根据 t 对图片和噪声进行混合,将加噪

Segment Anything Model(SAM)中的Adapter是什么?
在META团队发布的Segment Anything Model (SAM) 中,Adapter 是一种用于提升模型在特定任务或领域上的性能的机制。具体来说,SAM 是一个通用的分割模型,能够处理多种不同类型的图像分割任务,而 Adapter 的引入是为了更好地让模型适应不同的任务需求。 Adapter 的主要功能是: 模块化设计:Adapter 是一种小规模的、可插拔的网络模块,可以在不改

Vue学习:v-model绑定文本框、单选按钮、下拉菜单、复选框等
v-model指令可以在组件上使用以实现双向绑定,之前学习过v-model绑定文本框和下拉菜单,今天把表单的几个控件单选按钮radio、复选框checkbox、多行文本框textarea都试着绑定了一下。 一、单行文本框和多行文本框 <p>1.单行文本框</p>用户名:<input type="text" v-model="inputMessage"><p>您的用户名是:{{inputMe
Java memory model(JMM)的理解
总结:JMM 是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性、有序性。 总结的很精辟! 感谢Hollis总结

使用RMMapper将.plist文件转成model模型
在项目开发中, 有时我们会用到.plist, 这个时候可能会使用这个plist,拿出来用model去绑定它来对应项目MVC, 我们可以引入RMMapper,废话不多说,看代码先。 在git clone RMMapper,操作不多说了哈, 不会的可以私信我,会详细给你支招。 一、创建一个类TaskPlist基于NSObject, 代码如下: .h #import <Foundation
在Yolov8中model.export后self.export=false问题(记录)
遇到一个问题是自己创建了新的Detect检测头,但是在导出模型时,想要修改输出格式,在yolo中可以通过if self.export:来修改网络的返回值格式 当使用model.export()导出时,理论上会自动将export设置为True 但是在实际中发现export=false,于是通过调试发现在ultralytics/engine/exporter.py中 for m in model
class 5: vue.js 3 v-model和表单输入
v-model是Vue.js 3中用于实现双向绑定的重要指令,双向绑定就是对于数据的修改会映射回UI组件上,同时对于UI组件上数据的变更也会映射回底层数据当中,v-model会根据控件的类型自动选取正确的方法来更新元素v-model底层实现的原理实际上是v-bind和v-on的结合,首先使用v-bind为value属性绑定变量;然后使用v-on绑定input事件,并在事件回调中重新为value属性
强化学习实践(一):Model Based 环境准备
强化学习实践(一):Model Based 环境准备 代码项目地址 代码 这里是Model Based的环境构建,原型是赵老师课上的Grid World import numpy as npfrom typing import Tuplefrom environment.utils import Utilsfrom environment.enums import Rewa

SAM 2: The next generation of Meta Segment Anything Model for videos and images
https://ai.meta.com/blog/segment-anything-2/ https://github.com/facebookresearch/segment-anything-2 https://zhuanlan.zhihu.com/p/712068482

How to leverage pre-trained multimodal model?
However, embodied experience is limited inreal world and robot. How to leverage pre-trained multimodal model? https://come-robot.github.io/
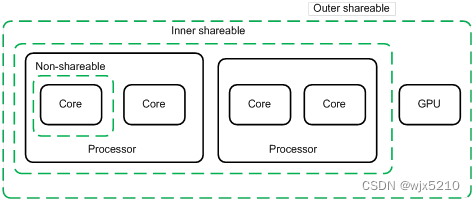
armv8 memory model概述
概述 在armv8 架构中,它引入了更多的维度来描述内存模型,从而在此基础上进行硬件优化(但其中一些并未被主流的软件所接受),在此做一些简单的整理,更多信息请参考 Arm spec 以及 AMBA 协议。下文主要是对Memory 和 Device 两大类的模型进行解释,个人言论难免有误,如有谬误请不吝指正。 首先将物理地址空间映射分成两大类: Memory, Device。 两者最大的区别在于
深度学习-TensorFlow2 :构建DNN神经网络模型【构建方式:自定义函数、keras.Sequential、CompileFit、自定义Layer、自定义Model】
1、手工创建参数、函数–>利用tf.GradientTape()进行梯度优化(手写数字识别) import osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'import tensorflow as tffrom tensorflow.keras import datasets# 一、获取手写数字辨识训练数据集(X_train, Y_train), (X_
自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词
NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】
NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】
one model / ensemble method /meta-algorithm 迁移学习算不算ensemble method
鉴于object detection COCO数据集的论文经常出现 single-model 也就是说,这是一个对网络的分类,呢它是什么意思,有什么特点。相对应的另一类是什么。就是下面介绍的ensemble learning。 不过比如说网络初值是用别人的网络训练好的数值,一定意义来讲是在优化空间找到一个初值,对于自己网络的结果的影响究竟有多大,也就是说,用随机初始网络得到的结果是否有不同,有多
Error when checking model target: expected activation_2 to have shape (None, 10) but got array with
我遇到了这个问题,因为我在用reshape层后,忘了改我的GT label的尺寸。 reshape最终的输出是10长度的,但是标签用的还是1长度的 就是(0,0,1,0,0,0,0,...)与3的不匹配
Keras 添加model.add(LSTM(......))等待时间过长,以及占用CPU空间的问题
原因: tensorflow版本过低,一般tensorflow在1.3.0以下(包括1.3.0)会出现这种问题 解决方法: 升级tensorflow pip install tensorflow --upgrade 再次运行会提示 ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9’ not found 参考博客: https:

深度学习01:pytorch中model eval和torch no_grad()的区别
公众号:数据挖掘与机器学习笔记 主要区别如下: model.eval()会通知所有的网络层目前处于评估模式(eval mode),因此,batchnorm或者dropout会以评估模式工作而不是训练模式。 在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p); batchnorm层会继续计算数据的mean和var等参数并更新。 在val模式下,dro
深度学习_数据读取到model模型存储
概要 应用场景:用户流失 本文将介绍模型调用预测的步骤,这里深度学习模型使用的是自定义的deepfm,并用机器学习lgb做比较 代码 导包 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom collections import defaultdic

vue学习十二( v-model用于自定义组件、父子组件通信、组件绑定原生事件、具名插槽、插槽作用域、动态组件is和keep-alive)
文章目录 自定义组件的 v-model子组件跟父组件通信将原生事件绑定到组件单个插槽插槽内容具名插槽作用域插槽is 特性实现动态组件动态组件使用 keep-alive 自定义组件的 v-model 一个组件上的 v-model 默认会利用名为 value 的 prop 和名为 input 的事件,但是像单选框、复选框等类型的输入控件可能会将 value 特性用于不同的目的。m

vue学习十(prop传参、v-bind传参、$emit向父级发送消息、input组件上使用 v-model、事件抛值)
文章目录 基本示例组件的复用通过 Prop 向子组件传递数据v-bind 来动态传递 prop通过 $emit 事件向父级组件发送消息使用事件抛出一个值在组件上使用 v-model 基本示例 组件是可复用的 Vue 实例,且带有一个名字:在这个例子中是 。我们可以在一个通过 new Vue 创建的 Vue 根实例中,把这个组件作为自定义元素来使用 <div id="com

vue学习九(表单输入绑定v-model)
文章目录 v-model 表单基础用法文本多行文本复选框多个复选框单选按钮选择框多选择框v-for 渲染的动态选项lazynumbertrim v-model 表单基础用法 你可以用 v-model 指令在表单 、 及 元素上创建双向数据绑定,v-model 本质上不过是语法糖。它负责监听用户的输入事件以更新数据,并对一些极端场景进行一些特殊处理。 文本 <div i
python model字段类型 速查表
V=models.CharField(max_length=None[, **options]) #varchar V=models.EmailField([max_length=75, **options]) #varchar V=models.URLField([verify_exists=True, max_length=200, **options]) #va