本文主要是介绍15、Scalable Diffusion Models with Transformers,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
官网

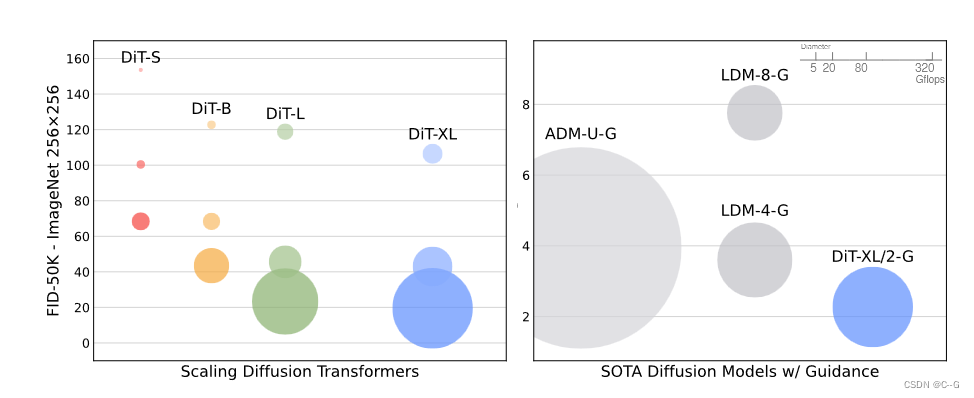
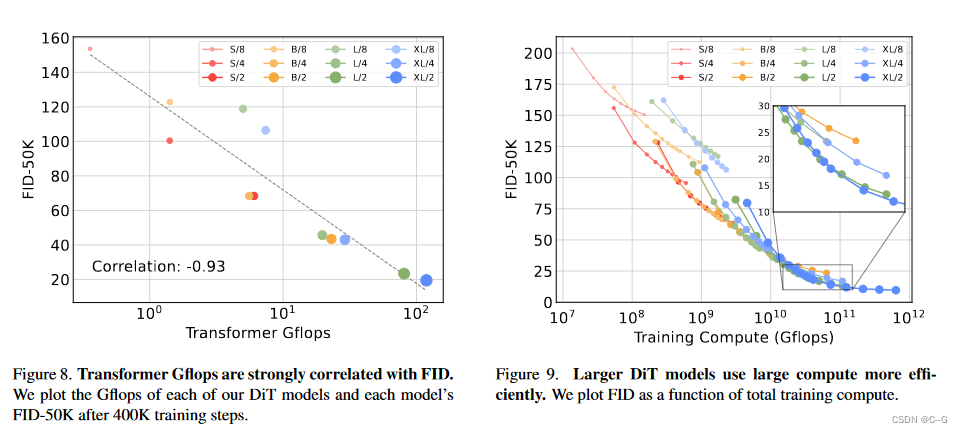
DiT(Diffusuion Transformer)将扩散模型的 UNet backbone 换成 Transformer,并且发现通过增加 Transformer 的深度/宽度或增加输入令牌数量,具有较高 Gflops 的 DiT 始终具有较低的 FID(~2.27),这样说明 DiT 是可扩展的(Scalable),网络复杂度(以 Gflops 度量)与样本质量(以 FID 度量)之间存在强相关性。
实现流程
Patchify
对于 256 × 256 × 3 256 \times256\times3 256×256×3 的图片, 中间特征 z 的维度是 32 × 32 × 4 32\times32\times4 32×32×4。DiT 的第1步和 ViT 一样,都是把图片 Patchify,并经过 Linear Embedding,最终变为 T 个 d 维的 tokens。在 Patchify 之后,将标准的基于 ViT 频率的位置编码 (sine-cosine 版本) 应用到所有的输入 tokens 上面。token T 的数量由 Patch 的大小 p 决定。Patch 的大小 p 和 token 的数量 T 之间满足 T = ( I / p ) 2 T=(I/p)^2 T=(I/p)2 的关系。当 Patch 的大小 p 越小时,token 的数量 T 越大。减半 p 将会使 T 变为4倍,使得计算量也变为4倍。尽管 p 对 GFLOPs 有显著的影响,但参数量没有很实质的影响。
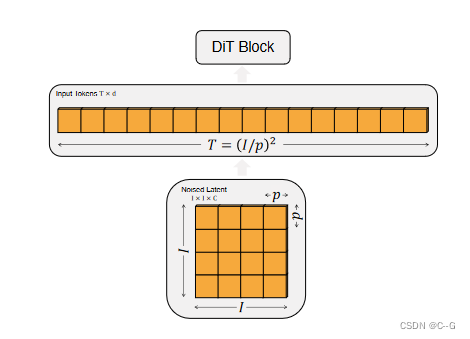
在 DiT design space 里面使用 p = 2 , 4 , 8 p=2,4,8 p=2,4,8
DiT block design
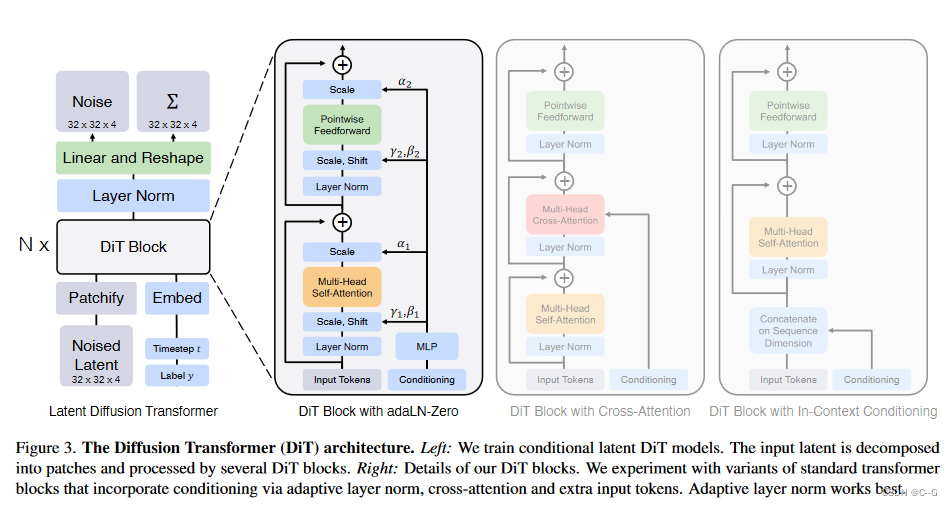
在patchify之后,输入令牌由一系列转换器块处理。除了带噪声的图像输入,扩散模型有时还处理附加的条件信息,如噪声时间步长 t、类标签 c、自然语言等。
作者探索了4种不同类型的 Transformer Block,以不同的方式处理条件输入。这些设计都对标准 ViT Block 进行了微小的修改。
In-context conditioning
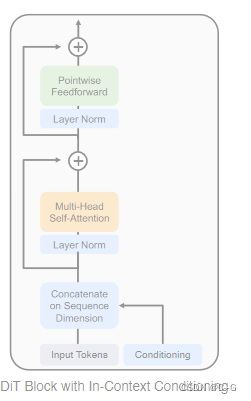
像这样的带条件输入的情况,In-context conditioning 的做法只需要将时间步长 t , 类标签 c 作为2个额外的 token 附加到输入的序列中。作者将它们视为与图像的 token 没有任何区别。这就有点类似于 ViT 的 [CLS] token。这就允许 DiT 使用标准的 ViT Block 而不用任何修改。经过了最后一个 Block 之后,删除条件 token 就行。这种方式带来的额外 GFLOPs 微不足道。
Cross-attention block
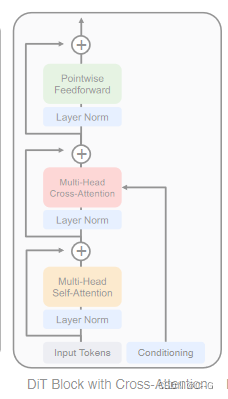
Cross-attention block 的做法是将 t和 c 的 Embedding 连接成一个长度为2的 Sequence,且与 image token 序列分开。这种方法给 Transformer Block 添加一个 Cross-Attention 块。这个操作带来的额外 GFLOPs 开销是大约 15%。
Adaptive layer norm (adaLN) block.
Adaptive Layer Norm (adaLN) Block 遵循 GAN[15]中的自适应归一化层,希望探索这个东西在扩散模型里面好不好用。没有直接学习缩放和移位参数 γ \gamma γ 和 β \beta β ,而是改用噪声时间步长 t 和类标签 c 得到。adaLN 带来的额外的 GFLOPs 是最少的,因此计算效率最高。它也是唯一一种限制于将相同函数应用于所有令牌的条件调节机制
这里补充一些知识,归一化的一般公式是: z ˉ = z − μ σ 2 + ϵ ⊙ γ + β \bar{z} = \frac{z-\mu}{\sqrt{\sigma^2+\epsilon} }\odot \gamma + \beta zˉ=σ2+ϵz−μ⊙γ+β ,其中 z 是激活值, μ , σ 2 \mu,\sigma^2 μ,σ2 是根据激活值按照某个规则(如 BatchNorm、LayerNorm、GroupNorm等)计算出来的均值和方差。 γ , β \gamma,\beta γ,β 是两个可学习的参数。
主要是由于自适应归一化层(adaptive normalization layers)在 GAN 和 UNet backbone 中的广泛使用(归一化的参数(如均值和方差)是根据当前批次的数据或特定层的激活值计算得出的。而在自适应归一化层中,这些参数可能会根据另一组数据(如风格图像)进行调整,以实现特定的效果),考虑将 Transformer 块中的 standard layer norm layers 替换成 adaptive layer norm (adaLN)。不同的是,对于其中的 scale and shift parameters 即 γ , β \gamma,\beta γ,β ,并不是直接学习它们,而是从
t 和 c 的 embedding vector 的和去回归这两个参数。
adaLN-Zero block
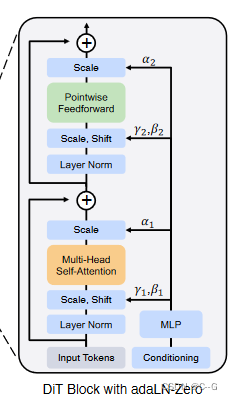
在有监督学习中,对每个 Block 的第一个 Batch Norm 操作的缩放因子进行 Zero-Initialization 可以加速其大规模训练。基于 U-Net 的扩散模型使用类似的初始化策略,对每个 Block 的第一个卷积进行 Zero-Initialization。本文作者作了一些改进:除了回归计算缩放和移位参数 γ \gamma γ 和 β \beta β 之外,还回归缩放系数 α \alpha α 。
作者初始化 MLP 使其输出的缩放系数 α \alpha α 全部为0,这样一来,DiT Block 就初始化为了 Identity Function。adaLN-Zero Block 带来的额外的 GFLOPs 可以忽略不计。
Transformer Decoder
在最后一个 DiT Block 之后,需要将 image tokens 的序列解码为输出噪声以及对角的协方差矩阵的预测结果。
而且,这两个输出的形状都与原始的空间输入一致。作者在这个环节使用标准的线性解码器,将每个 token 线性解码为 P × P × 2 C P\times P \times 2C P×P×2C 的张量,其中 C 是空间输入中到 DiT 的通道数。最后将解码的 tokens 重新排列到其原始空间布局中,得到预测的噪声和协方差。
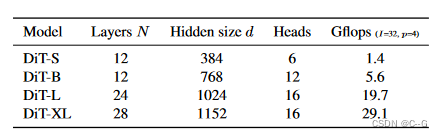
模型尺寸
遵循 ViT 的做法,作者在缩放 DiT 时也是从下面几个维度进行考虑:深度 N ,hidden dimension d,head 数量。作者设计出4种不同尺寸的 DiT 模型 DiT-S, DiT-B, DiT-L 和 DiT-XL,从 0.3 到 118.6 GFLOPs,详细信息如下图所示。
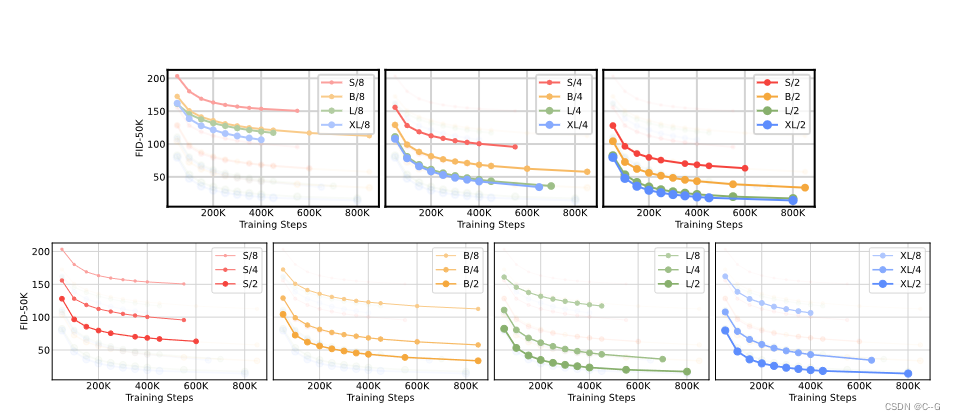
实验
这篇关于15、Scalable Diffusion Models with Transformers的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
