本文主要是介绍论文阅读:Scalable Diffusion Models with Transformers,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Scalable Diffusion Models with Transformers
论文链接
介绍
传统的扩散模型基于一个U-Net骨架,这篇文章提出了一种新的扩散模型结构,将U-Net替换为一个transformer,并将这种结构称为Diffusion Transformers (DiTs)。他们还发现,transformer的规模越大(通过Gflops衡量),生成的图片的质量越好(FID越低)。
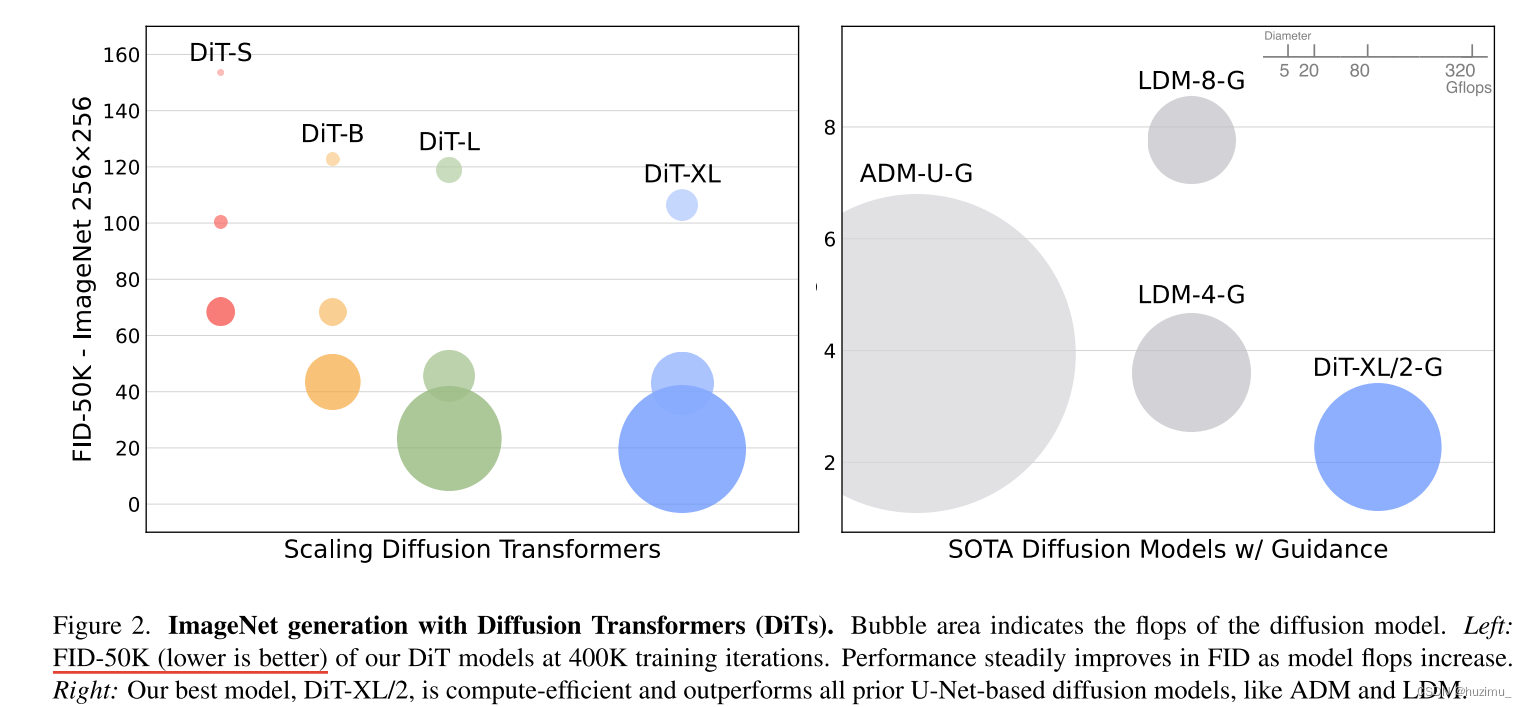
如图2所示,DiT的规模越大,图片生成的质量越好(左图),和当前流行的扩散模型相比,DiT的计算效率也表现优异。
相关工作
- Transformers:这篇文章研究了transformer作为扩散模型的骨架时,其规模的性质。
- Denoising diffusion probabilistic models (DDPMs):传统的扩散模型都使用U-Net作为骨架,本文尝试使用纯transformer作为骨架。
- Architecture complexity:在结构设计领域,Gflops是常见的衡量结构复杂度的指标。
方法(Diffusion Transformers)
预备知识
- Diffusion formulation:扩散模型Diffusion Model(DM)在训练过程中,首先向图片中添加噪声,然后预测噪声来从图片中将噪声去除。这样,在推理过程中,首先初始化一个高斯噪声图片,然后去除预测的噪声,即可得到生成的图片。
- Classifier-free guidance:条件扩散模型引入了额外信息 c c c(比如,类别)作为输入。而classifier-free guidance可以引导生成的图片 x x x是类别 c c c的概率 l o g ( c ∣ x ) log(c|x) log(c∣x)最大。
- Latent diffusion models:扩散模型在像素空间上训练和推理的计算开销过大,Latent Diffusion Model(LDM)将像素空间替换为VAE编码得到的潜在空间 z = E ( x ) z=E(x) z=E(x),可以提高计算效率。本文提出的DiT沿用了LDM中的潜在空间,但是在预测潜在空间特征的模型上,将LDM中的U-Net替换为了纯Transformer骨架。
Diffusion Transformer Design Space
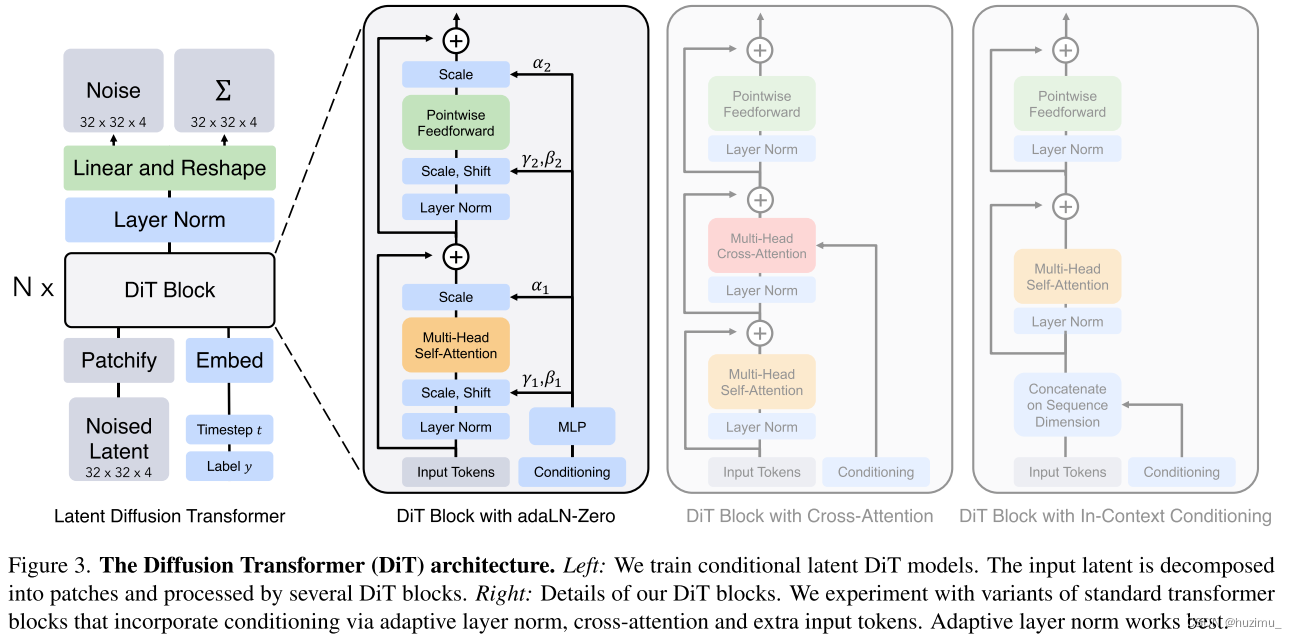
Diffusion Transformers (DiTs)是基于Vision Transformer (ViT)的模型,它的大体结构如图3所示,从左图可以看到,输入的噪音特征被分解为不同批,然后被若干个DiT块处理;右边的三张图展示了DiT块的详细结构,分别是三种不同的变体。
下面对DiT的各层进行分析:
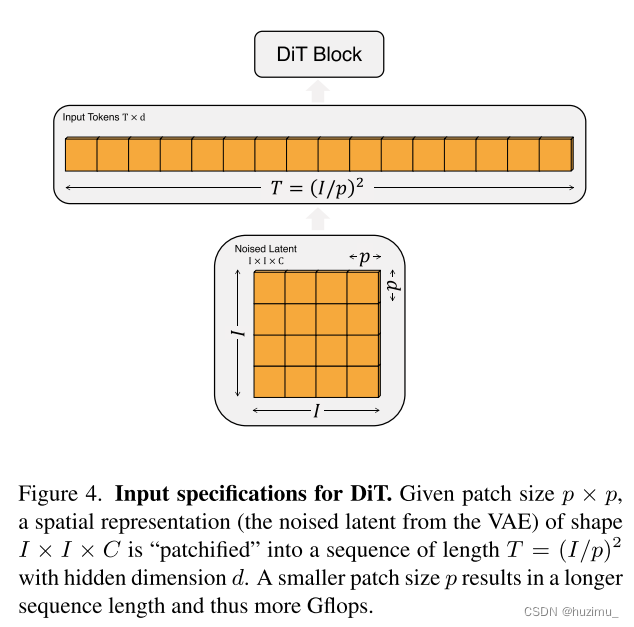
Patchify. 从图3中可以看到,DiT的第一个层是Patchify,其将输入转化为 T T T个token序列。在这之后,作者使用标准ViT中基于频率的位置嵌入处理前面的token序列。而token序列的数量是由一个超参数 p p p决定的, p p p减半导致 T T T翻四倍,并且导致整个transformer的GFlops至少翻四倍,如图4所示。
DiT block design. 在patchfiy层之后,几个transformer块处理输入token以及一些额外的条件信息,比如,类标签 c c c和时间步数 t t t。作者尝试了4种不同的ViT变体:
- In-context conditioning:这种变体直接将时间步数 t t t和类标签 c c c作为额外的token添加到输入token序列后面,类似于ViT的cls tokens,因此也可以直接使用标准的ViT块。这种方式引入的Gflops可以忽略不计。
- Cross-attention block:这种变体将条件信息拼接为一个长度为2的序列,独立于图片输入序列。然后,在transformer块的self-attention层后添加了一个cross-attention层,类似于LDM,在cross-attention层将条件信息加入图片特征中。cross-attention方案增加的Gflops最多,大概15%。
- Adaptive layer norm (adaLN) block:这种变体将transformer块中标准的layer norm layers替换为adaptive layer
norm (adaLN),这一技术在GAN相关的模型中被广泛采用。不同于直接学习维度放缩和偏移因子 γ \gamma γ和 β \beta β,该方案回归 t t t和 c c c的嵌入的和得到这两个参数。在目前的三种方案中,该变体额外增加的Gflops最少。 - adaLN-Zero block:先前的工作说明,ResNet中的恒等映射是有益处的。Diffusion U-Net在残差之前,零初始化了每个块中最后一个卷积层。作者采用了和Diffusion U-Net相同的方案。此外,除了回归 γ \gamma γ和 β \beta β,该方案还对DiT块中残差连接上的放缩因此 α \alpha α进行了回归。对于所有的 α \alpha α,作者初始化MLP以输出零向量,这使得DiT块为一个恒等函数。和adaLN方案一样,ada-Zero方案引入的Gflops也可以忽略不计。
Model Size. 作者设置了四种规模的DiT:DiT-S, DiT-B, DiT-L and DiT-XL,结构复杂度依次增大。
Transformer decoder. 在经过最后的DiT块之后,使用tranformer decoder将输入tokens转化为和输入同等性状的噪音预测。
综上,作者探索了DiT设计空间中的patch_size、transformer架构(4种,in-context,cross-attention, adaptive layer
norm and adaLN-Zero blocks)和model size(4种,DiT-S, DiT-B, DiT-L and DiT-XL)。
实验
实验设置
- 训练:在256 × 256和512 × 512 图片分辨率的ImageNet数据集上训练。超参数设置几乎和ADM一致。
- Diffusion:和Stable DIffusion一样使用VAE编码图片和解码特征。
- 评估指标:主要使用Fr´echet Inception Distance (FID),还使用了Inception Score [51], sFID [34] and Precision/Recall [32]
- 计算平台:在JAX [1]这个深度学习框架上实现了DiT,在TPU上训练模型。
实验结果
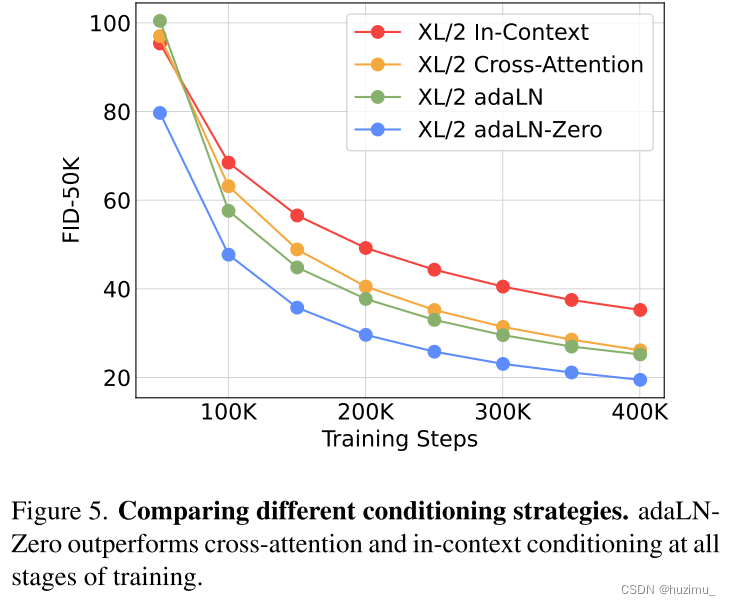
DiT block design. 四个不同的DiT块:in-context (119.4 Gflops), cross-attention (137.6 Gflops),
adaptive layer norm (adaLN, 118.6 Gflops) or adaLN-zero (118.6 Gflops)中, adaLN-zero (118.6 Gflops) 取得最低的FID。其中,adaLN-zero相较于adaptive layer norm的提升,说明了恒等映射的好处。(后续的实验除非特别说明都是在adaLN-zero上做的)
Scaling model size and patch size. 模型size增大和patch zise减小,均会提高Gflops,降低FID。我们注意到,DiT-L 和DiT-XL的FID很接近,因为它们的Gflops也相对更接近。
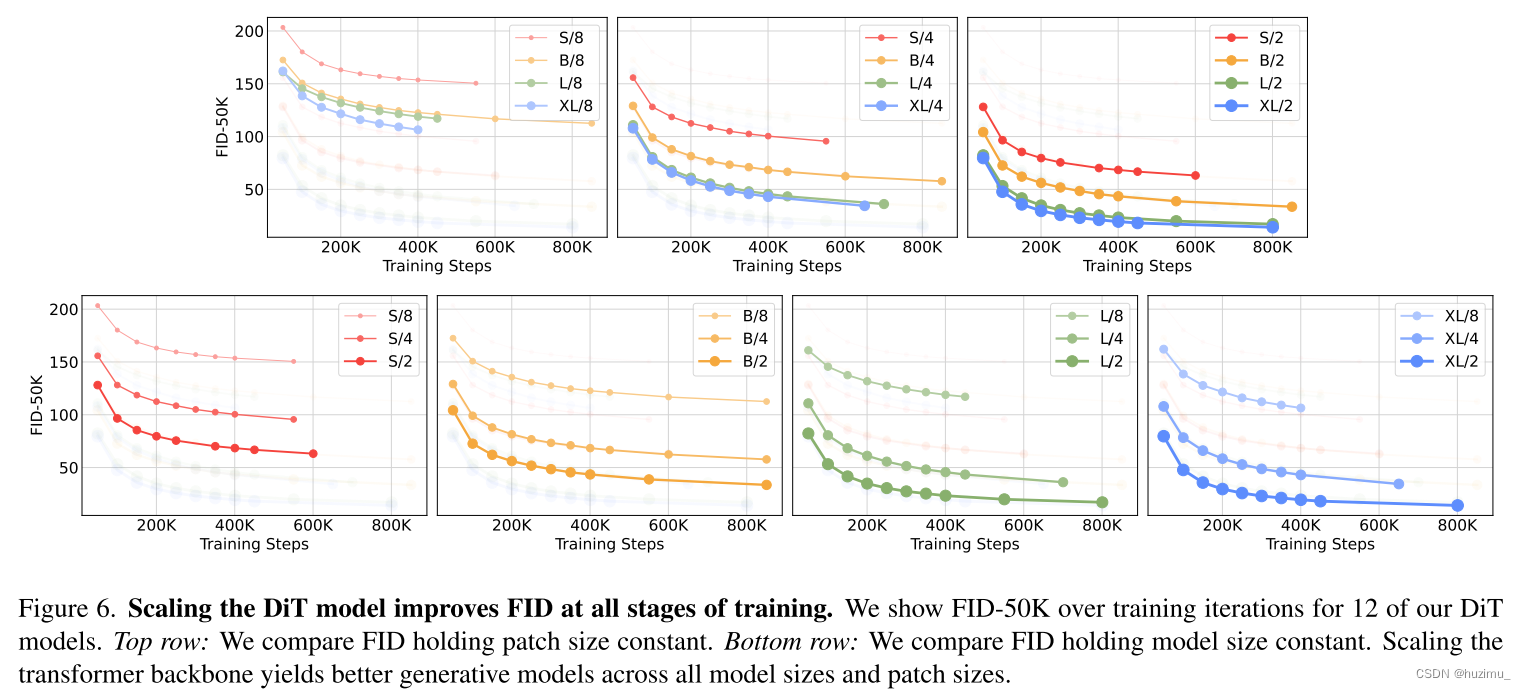
DiT Gflops are critical to improving performance. 上面的图6再次说明了模型参数量的增大并不等同于DiT模型的图片质量提高,真正的关键是提高Gflops。比如,DiT S/2的表现和DiT B/4接近,因为小的batch size会增大Gflops,二者的Gflops接近,所以FID也接近。
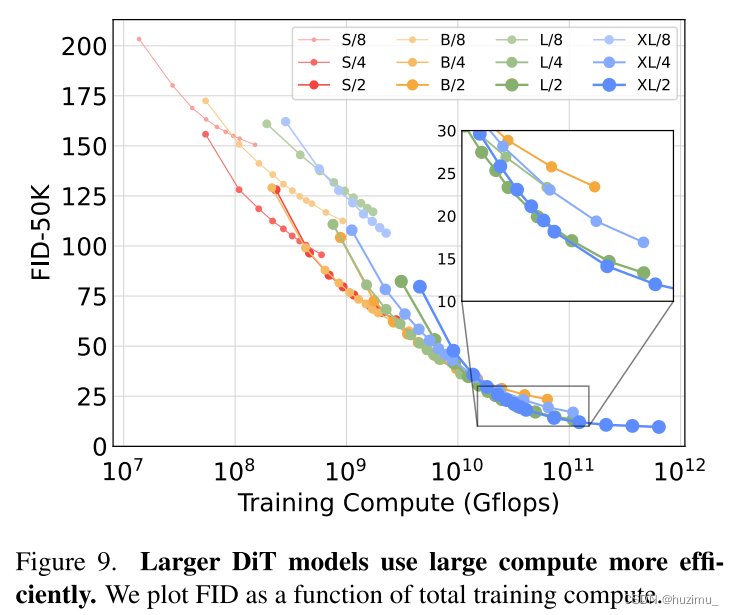
Larger DiT models are more compute-efficient
小的DiT模型即便训练时间更长,相对于训练时间更短的大的DiT模型,其计算效率也是更差的。
这里,作者估计训练计算量的方式为model Gflops · batch size · training steps · 3。
State-of-the-Art Diffusion Models
和主流的扩散模型相比,DiT-XL/2 (即参数量最大,patch size最小的DiT)的表现最优。
Scaling Model vs. Sampling Compute
扩散模型有一个比较特殊的点,在生成图片时,它可以通过增加调整采样步数,引入额外的增加的计算量,但是,这并不能弥补训练时模型计算量的差距,即大GFlops的DiT在采样步数少的情况下,仍然能比小GFlops的DiT在采样步数多的情况下,取得更低的FID。
结论
Diffusion Transformers (DiTs)作为一种新的扩散模型,比基于U-Net的扩散模型表现更加优异。并且,其在模型复杂度提高的时候,能够有明显的性能提高,因此,使用更大规模的DiT有助于提高模型性能。此外,DiT也可以用于文生图生成任务。
这篇关于论文阅读:Scalable Diffusion Models with Transformers的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
