metadata专题

Python安装llama库出错“metadata-generation-failed”
Python安装llama库出错“metadata-generation-failed” 1. 安装llama库时出错2. 定位问题1. 去官网下载llama包 2.修改配置文件2.1 解压文件2.2 修改配置文件 3. 本地安装文件 1. 安装llama库时出错 2. 定位问题 根据查到的资料,发现时llama包中的execfile函数已经被下线了,需要我们手动修改代码后

dbms_metadata.get_ddl的用法(DDL)
dbms_metadata.get_ddl的用法(DDL) dbms_metadata包中的get_ddl函数 --GET_DDL: Return the metadata for a single object as DDL. -- This interface is meant for casual browsing (e.g., from SQLPlus) -- vs. th

深入了解 MySQL 中的 Metadata Lock(MDL)
深入了解 MySQL 中的 Metadata Lock(MDL) 在 MySQL 数据库中,Metadata Lock(MDL)是确保数据库表结构一致性的关键机制。MDL 的主要作用是在进行表结构更改时防止其他操作同时访问或修改表结构,以避免数据不一致和其他潜在的冲突。本文将详细介绍 MDL 的概念、工作机制、常见问题及其解决方案,并提供具体的示例。 1. 什么是 Metadata Lock(

Cognos Error: Store Procedure Metadata Mismatch
遇到以下错误: 解决方法: 发现错误源是一个Store procedure, 初步判断是由于更新了字段导致的元数据不匹配。 在FM里对该SP进行了Tools——Update Object之后,问题依旧。 最后确认到问题根源是由于字段的顺序发生了变更。在修改回去以后问题解决。 存储过程的返回结果,不论是列的数量、字段长度、精度或者是顺序,都必须与该查询第一次创建的时候保持一
Openstack--虚拟机获取metadata
1、169.254.169.254 在实例中有一个魔法IP 169.254.169.254,通过访问这个ip,能获得许多与这个实例相关的信息,这些信息被称为metadata,我们在实例上发送:curl http://169.254.169.254/latest/meta-data/。 2、请求流程 1)instance 通过预定义的 169.254.169.254 请求 metadata;
Kylin报错 FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException...
Kylin接入Hive数据时,报错如下: FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaSt
Table Metadata
Table Metadata 表元数据存储为JSON。每个表元数据更改都会创建一个由原子操作提交的新表元数据文件。此操作用于确保表元数据的新版本替换它所基于的版本。这将生成表版本的线性历史记录,并确保并发写操作不会丢失。 用于提交元数据的原子操作取决于如何跟踪表,该规范没有对其进行标准化。 Table Metadata Fields 表元数据由以下字段组成: v1v2字段描述requir

Android camera: Metadata\Image从HAL到framework
RequestThread Thread for managing capture request submission to HAL device 1. waiting next batch of requests: CaptureRequest: From App to frameworkcemara3_capture_request: camera service
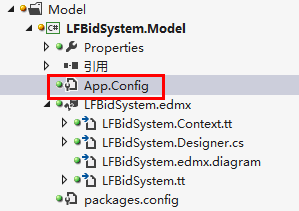
无法加载指定的元数据System.Data.Metadata.Exception
产生背景 删除了旧的EF实体模型,重新建的新的EF实体模型和之前建立的实体模型名称不一样。 如:BidSystem.edmx(旧),LFBidSystem.edmx(新)。 产生原因 WCF服务层的配置文件web.config及单元测试项目中的配置文件app.config中的配置节和Model层的配置文件不一致,如图所示: 解决方法 复

No suitable constructor found for type [simple type, class com.bonc.vbap.dataservice.core.metadata.i
这是在使用Jackson对接口或者抽象类进行反序列化的时候出现的问题,从问题中可以看出是构造器的问题,找不到默认的构造器,为什么会找不到默认的构造器呢,因为在创建类的时候JDK自动创建一个默认的无参构造方法,但是我们自己添加了一些构造方法,这样的话就把默认的构造方法改了,也就找不到了。 解决办法是只需要在接口的实现类或者抽象类的子类中添加一个无参构造方法即可。 例如: package b
Cannot read lifecycle mapping metadata for artifact org.apache.maven.plugins:maven-site-plugin:maven
Maven 环境出错 Cannot read lifecycle mapping metadata for artifact org.apache.maven.plugins:maven-site-plugin:maven-plugin:3.0:runtime Cause: error in opening zip filepom.xml Maven Project Build Lifecy

用webui.sh安装报错No module named ‘importlib.metadata‘
安装sdweb报错,出现No module named 'importlib.metadata: glibc version is 2.35Cannot locate TCMalloc. Do you have tcmalloc or google-perftool installed on your system? (improves CPU memory usage)Traceback
Kubernetes中metadata解析
在 Kubernetes 的上下文中,metadata 是资源配置文件中的一个重要部分,用于描述资源实例的元数据信息。这些信息不直接影响资源的功能,但对资源的管理和运维至关重要。metadata 包含了资源的身份标识、标签、注解以及其他有助于组织、筛选、监控资源的属性。 1、基本结构 一个典型的 metadata 部分看起来如下: apiVersion: apps/v1kind: Depl
salesforce vscode 获取profile metadata所有配置内容
1.更新cli:sfdx update 2.安装read插件:sfdx plugins:install sfdx-plugin-source-read 3.通过vscode☁️(org browser)或者package.xml拉取profile,此时获取的简档没有所有配置内容 <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
Hive mapreduce报错:java.io.IOException: Split metadata size exceeded 10000000
mapreduce报错:java.io.IOException: Split metadata size exceeded 10000000 一、问题现象 客户在用hive sql做几张表的组合分析,使用mr引擎。 因为其中有一张表超过5万个分区,数据总量超过8千亿条,因此运行过程中出现失败,报错如下所示: org.apache.hadoop.mapreduce.v2.app.job.imp
元数据(MetaData)的简单理解
元数据是用来描述数据的数据(Data that describes other data)。单单这样说,不太好理解,我来举个例子。 下面是契诃夫的小说《套中人》中的一段,描写一个叫做瓦莲卡的女子: (她)年纪已经不轻,三十岁上下,个子高挑,身材匀称,黑黑的眉毛,红红的脸蛋--一句话,不是姑娘,而是果冻,她那样活跃,吵吵嚷嚷,不停地哼着小俄罗斯的抒情歌曲,高声大笑,动不动就发出一连串响亮的笑声
Failed to read candidate component class: file [F:\eclipse neon\.metadata\.plugins\org.eclipse.wst.s
一、今天在写项目中遇到一个问题,异常如标题 二、这个项目是以前运行过的,并没有修改代码 ,但是却出现了错误。 org.springframework.beans.factory.BeanDefinitionStoreException: Failed to read candidate component class: file [F:\eclipse neon\.metadata\.plug

android studio 编译一直显示Download maven-metadata.xml
今天打开之前的项目的时候遇到这个问题:android studio 编译一直显示Download maven-metadata.xml, AI 查询 报错问题:"android studio 编译一直显示Download maven-metadata.xml" 解释: 这个错误通常表示Android Studio在尝试从Maven仓库下载maven-metadata.xml文件时遇到了问题

OpenHarmony多媒体-metadata-extractor
简介 metadata-extractor是用于从图像、视频和音频文件中提取 Exif、IPTC、XMP、ICC 和其他元数据的组件。 下载安装 ohpm install @ohos/metadata-extractor OpenHarmony ohpm环境配置等更多内容,请参考 如何安装OpenHarmony ohpm包 。 使用说明 引入文件及代码依赖 impo
Linode Metadata服务已正式上线!
相信很多人在Linode平台配置系统时都遇到过这样的情况:部署完云计算实例后,几乎总是需要执行额外的配置,然后服务器才能开始真正工作。 这些配置可能包括创建新用户、添加SSH密钥、安装软件......也可能包括更复杂的任务,如配置网络服务器或在实例上运行的其他软件。手动执行这些任务容易出错、速度慢,而且不具备可扩展性。 为了使这一过程自动化,Linode提供了两种配置自动化工具:Metadat
Tagging: People-powered Metadata for the Social Web
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Tagging is fast becoming one of the primary ways people organize and manage digital information. Tagging
Metadata file 'xxx.dll' could not be found错误的解决方案
在网上搜索了很多该问题的解决方案,可均未能实现,原来原因在于多个project项目在编译时候首先要保证本身无错,如果本身有错,可先注释,然后确保无错后编译,该错误自动会消失。 可参考:https://stackoverflow.com/questions/44251030/vs-2017-metadata-file-dll-could-not-be-found

OPENSTACK中的METADATA SERVER
OPENSTACK中的METADATA SERVER 虚拟机启动时候需要注入hostname、password、public-key、network-info之类的信息,以便虚拟机能够被租户管理。对于这些信息的注入openstack提供了两种方式, guestfs-inject以及metadata-server。 guestfs-inject的使用很受限制尤其是并不是所有镜像都能够支持
Dynamic Metadata Management for Petabyte-scale File Systems——论文阅读
SC 2004 Paper 分布式元数据论文阅读笔记整理 问题 在读写与元数据操作解耦的PB级分布式文件系统中,尽管元数据的大小相对较小,但元数据操作可能占所有文件系统操作的50%以上[19],这使得MDS集群的性能对整个系统性能和可扩展性至关重要。 挑战 系统中的元数据服务器集群应该有效地维护各种工作负载的文件系统目录和权限语义,包括科学计算应用程序和通用计算。这样的文件系统可能涉及从几
spring-configuration-metadata
在写公共库的时候, 遇到一个场景, 需要在公共库中代码对配置进行解析, 但是在业务项目中写配置文件时会出现, Cannot resolve configuration property 'xxx'. 一开始在公共库添加了"additional-spring-configuration-metadata.json", 但该json是针对当前项目的. 在业务项目中仍然出现"Cannot resolv

littlefs系列:metadata pairs
metadata pairs是littlefs的基石。metadata pairs是两个可以原子更新的block log。 为什么要使用两个block呢? 原因如下:1,log的工作原理是所有的entry否存储在一个环形buffer中。由于flash的擦写特性,需要用两个block来互相备份。2,也可以使用更多的block,但是需要额外的数据结构来跟踪所有的block,代价较高。 1 met