本文主要是介绍littlefs系列:metadata pairs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
metadata pairs是littlefs的基石。metadata pairs是两个可以原子更新的block log。
为什么要使用两个block呢?
原因如下:1,log的工作原理是所有的entry否存储在一个环形buffer中。由于flash的擦写特性,需要用两个block来互相备份。2,也可以使用更多的block,但是需要额外的数据结构来跟踪所有的block,代价较高。
1 metadata pairs中如何确定哪个metadata block是最新的呢?
使用revision count
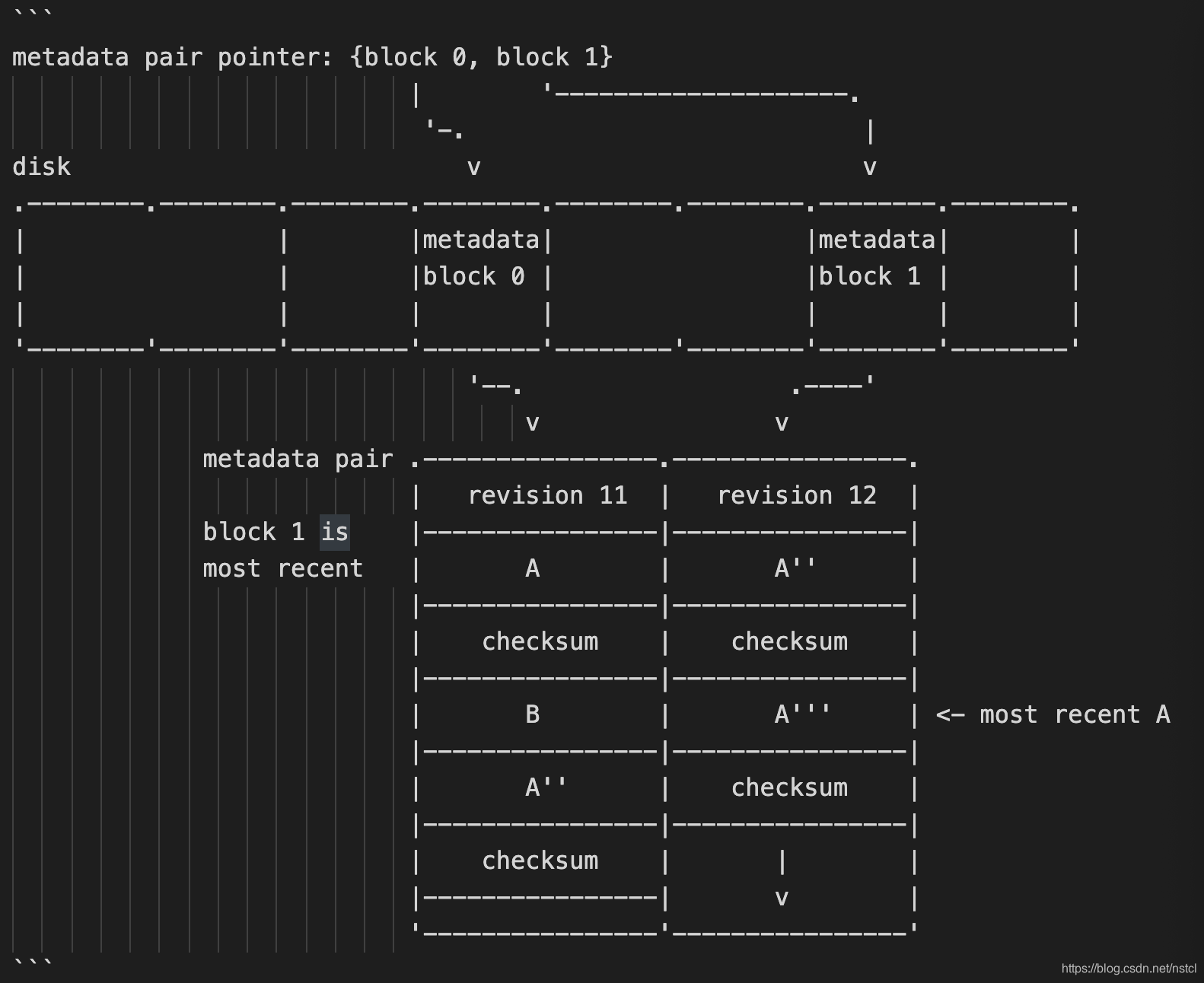
从上图中可以看出,block1对应的metadata是最新的。
2 metadata pair的更新
metadata pair要求更新时时原子操作。即要求metadata pair的更新操作具备冗余性和错误检测。
错误检测通过32-bit的crc实现。而冗余性则稍微复杂一点:
1) 当前的block有足够的剩余空间,则直接写入

注意:在littlefs中的metadata中,不是每个entry都有一个crc,littlefs会对存储在同一个block上的多个entry打包提供一个crc。
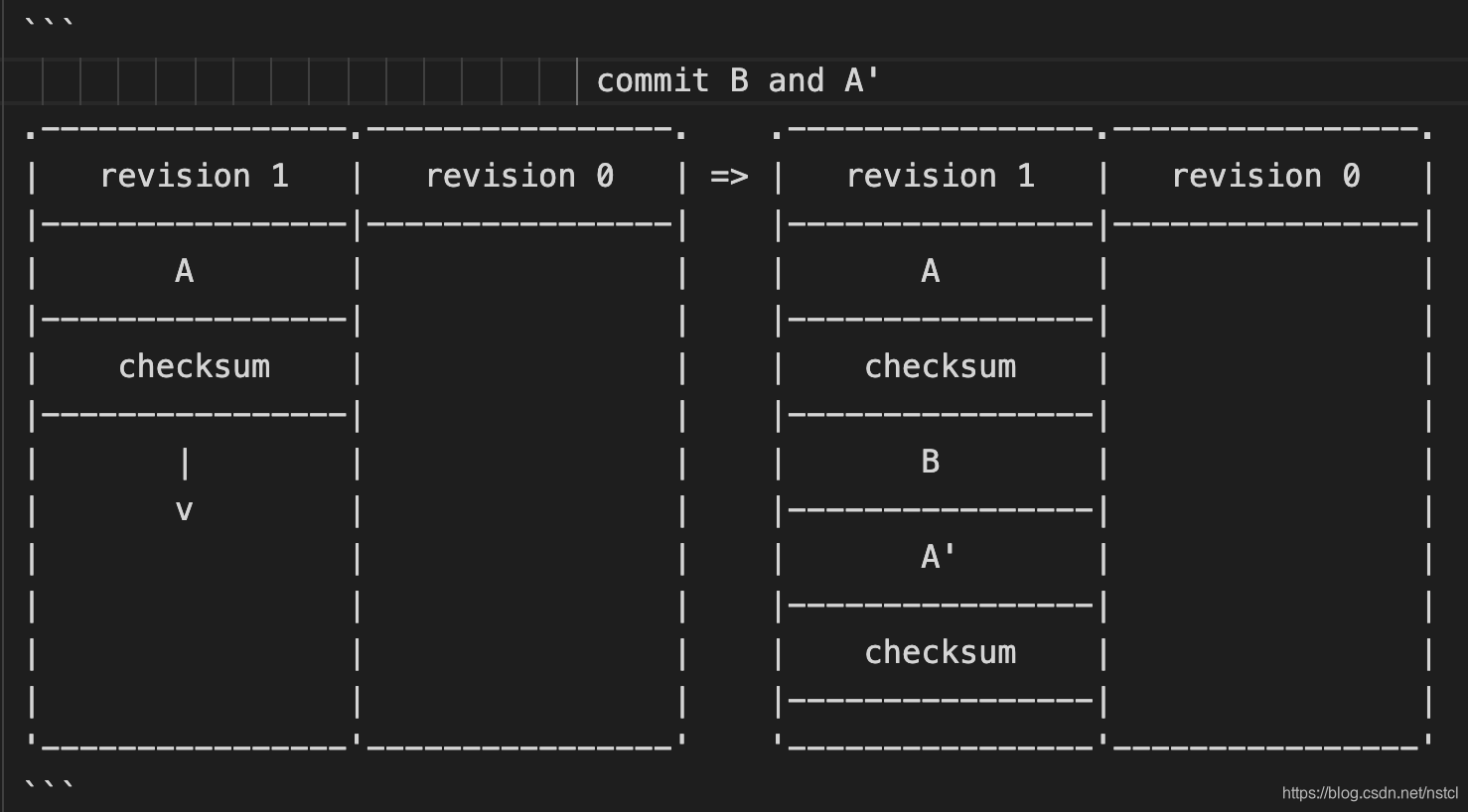
在上图中entry B和A'共享一个checksum。
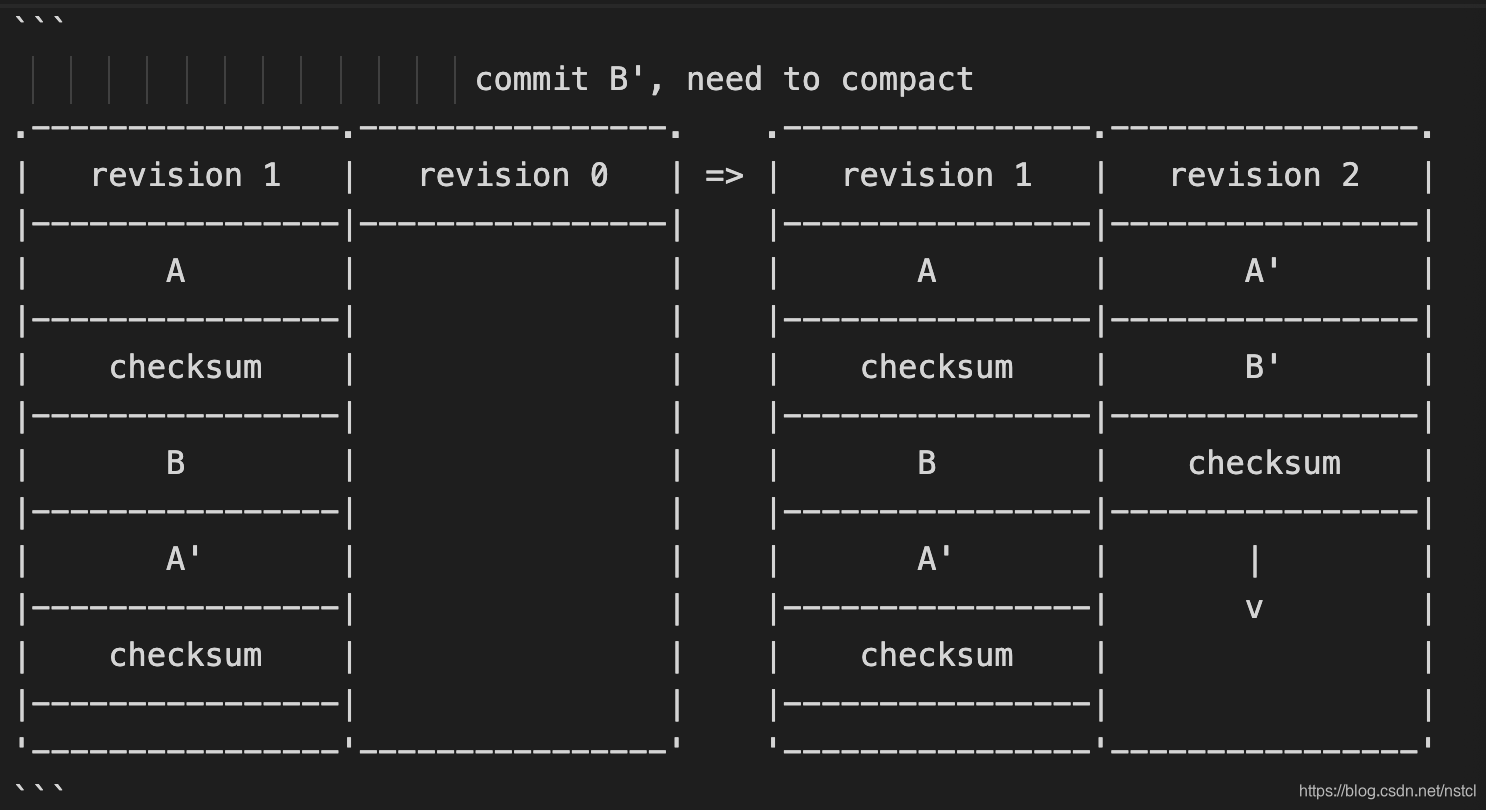
2)当前的block没有足够的空间,启动entry compaction。在entry compaction时,对于每个entry查看是否有更新的entry,每次都是把所有最新的entry写入到新的block中,这也说明了为什么metadata pair使用两个block的好处。在entry compaction中,新的metadata block的revision count会增加,同时也会对多个entry打包写入。
3)metadata block完全写满且没有待回收的garbage entry。把原始的metadata pair分成两个metadata pairs,占用4个block。每个metadata pairs中包含一般的entry,通过指针链接

在上图中可以看出,原本的metadata pair分成了两组metadata pairs。为了提高metadata pair的更新效率,littlefs在实现时,只要metadata pair使用了超过50%的容量就会分成两个metadata pairs。
https://blog.csdn.net/nstcl/article/details/108051141
这篇关于littlefs系列:metadata pairs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








