本文主要是介绍Accelerating Performance of GPU-based Workloads Using CXL——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FlexScience 2023 Paper CXL论文阅读笔记整理
问题
跨多GPU系统运行的高性能计算(HPC)工作负载,如科学模拟和深度学习,是内存和数据密集型的,依赖于主机内存来补充其有限的板载高带宽内存(HBM)。为了促进在慢速设备到主机PCIe互连之间更快的数据传输,这些工作负载通常将内存固定在主机系统上,但对同一节点的对等GPU上运行的工作负载的主机内存造成内存容量限制。(预留部分内存用于加快传输速度,但限制了内存可用容量)
计算快速链路(CXL)是一种新兴技术,它以缓存一致的方式以低延迟和高吞吐量透明地扩展可用的系统内存容量。虽然跨多GPU节点运行的工作负载可以利用这一点来分配和固定更多的内存,但由于CXL内存上的争用,使用传统的内存分配方案可能会对数据吞吐量产生不利影响。
本文方法
本文针对支持CXL的多GPU系统上,与作业调度和内存分配相关的挑战。提出了调度感知的内存分配方法,结合了多GPU系统的每个插槽上的内存需求,并提供了有效的内存布局图来缓解内存争用,最大限度地提高吞吐量并减少总体数据传输时间。
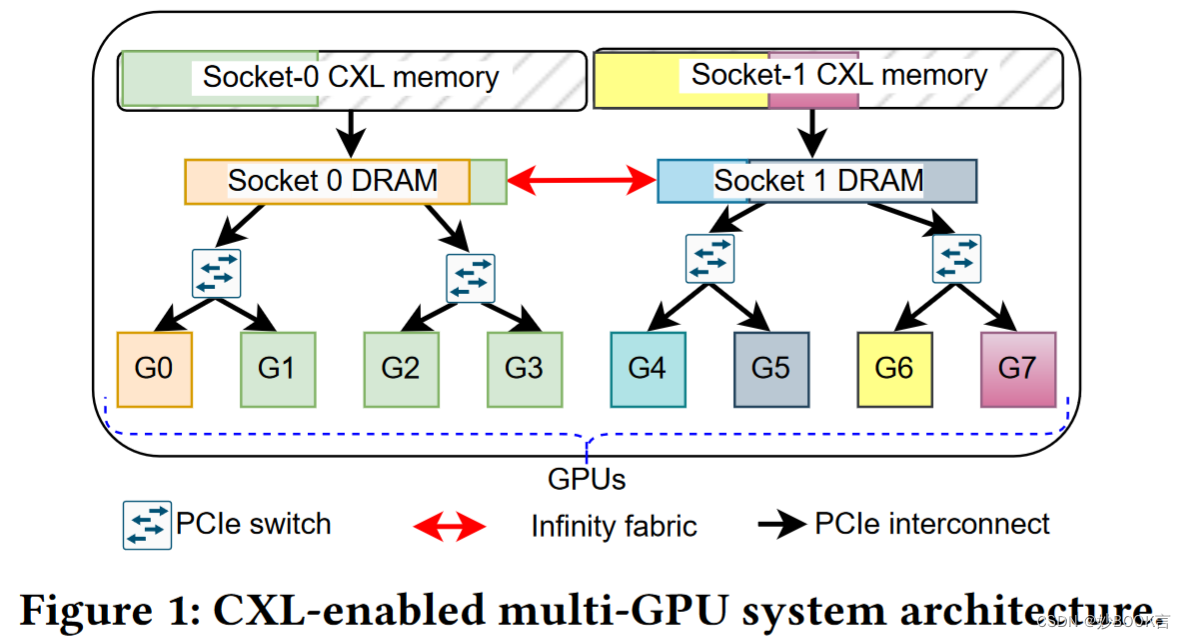
基于对各种作业配置文件和系统配置的模拟,我们对所提出的内存分配方法进行了初步评估,结果表明,与现有内存分配方法相比,数据传输开销降低了65%。
实验
实验环境:在Ubuntu 22.04 LTS服务器操作系统上进行的,该操作系统使用两个2.40 GHz Intel Xeon Gold 6240R处理器,主内存为192 GB。每个作业消耗1到8个GPU,并在单个套接字或两个套接字上运行,这取决于请求的GPU,这些GPU在套接字之间均匀分配。
模拟器:从英伟达DGX-A100机器的默认配置开始更改测试台的配置文件,考虑每个插槽64 GB的可用内存。根据图1所示的拓扑结构,使用PCIe Gen 4.0将多个GPU连接到主机系统。观察到的空闲存储器访问延迟约为130𝑛s。
实验对比:数据传输时间
实验参数:DRAM内存、PCIe带宽、CXL惩罚
总结
针对基于GPU的HPC工作负载,其通常受到板载系统存储器的数量以及共享存储器资源(例如主存储器)和互连(例如PCIe)的争用的限制。本文提出了一种高效的内存分配方法,结合了多GPU系统的每个插槽上的内存需求进行内存分配。
局限性:整体来看方法比较简单,就是根据各种资源剩余数量和需求量进行分配。实验也是基于模拟,在访问过程增加CXL惩罚,实验不太准。
这篇关于Accelerating Performance of GPU-based Workloads Using CXL——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)