gpu专题

AI Toolkit + H100 GPU,一小时内微调最新热门文生图模型 FLUX
上个月,FLUX 席卷了互联网,这并非没有原因。他们声称优于 DALLE 3、Ideogram 和 Stable Diffusion 3 等模型,而这一点已被证明是有依据的。随着越来越多的流行图像生成工具(如 Stable Diffusion Web UI Forge 和 ComyUI)开始支持这些模型,FLUX 在 Stable Diffusion 领域的扩展将会持续下去。 自 FLU

如何用GPU算力卡P100玩黑神话悟空?
精力有限,只记录关键信息,希望未来能够有助于其他人。 文章目录 综述背景评估游戏性能需求显卡需求CPU和内存系统需求主机需求显式需求 实操硬件安装安装操作系统Win11安装驱动修改注册表选择程序使用什么GPU 安装黑神话悟空其他 综述 用P100 + PCIe Gen3.0 + Dell720服务器(32C64G),运行黑神话悟空画质中等流畅运行。 背景 假设有一张P100-

GPU 计算 CMPS224 2021 学习笔记 02
并行类型 (1)任务并行 (2)数据并行 CPU & GPU CPU和GPU拥有相互独立的内存空间,需要在两者之间相互传输数据。 (1)分配GPU内存 (2)将CPU上的数据复制到GPU上 (3)在GPU上对数据进行计算操作 (4)将计算结果从GPU复制到CPU上 (5)释放GPU内存 CUDA内存管理API (1)分配内存 cudaErro

PyInstaller问题解决 onnxruntime-gpu 使用GPU和CUDA加速模型推理
前言 在模型推理时,需要使用GPU加速,相关的CUDA和CUDNN安装好后,通过onnxruntime-gpu实现。 直接运行python程序是正常使用GPU的,如果使用PyInstaller将.py文件打包为.exe,发现只能使用CPU推理了。 本文分析这个问题和提供解决方案,供大家参考。 问题分析——找不到ONNX Runtime GPU 动态库 首先直接运行python程序

麒麟系统安装GPU驱动
1.nvidia 1.1显卡驱动 本机显卡型号:nvidia rtx 3090 1.1.1下载驱动 打开 https://www.nvidia.cn/geforce/drivers/ 也可以直接使用下面这个地址下载 https://www.nvidia.com/download/driverResults.aspx/205464/en-us/ 1.1.3安装驱动 右击,

Kubernetes的alpha.kubernetes.io/nvidia-gpu无法限制GPU个数
问题描述: Pod.yaml文件中关于GPU资源的设置如下: 然而在docker中运行GPU程序时,发现宿主机上的两块GPU都在跑。甚至在yaml文件中删除关于GPU的请求,在docker中都可以运行GPU。 原因: 上例说明alpha.kubernetes.io/nvidia-gpu无效。查看yaml文件,发现该docker开启了特权模式(privileged:ture): 而

GPU池化赋能智能制造
2023年3月10日,“第六届智能工厂高峰论坛”在杭州隆重揭幕。本次会议由e-works数字化企业网、浙江制信科技有限公司主办,中国人工智能学会智能制造专业委员会、长三角新能源汽车产业链联盟、长三角(杭州)制造业数字化能力中心、浙江省智能工厂操作系统技术创新中心协办。趋动科技作为钻石合作伙伴出席了本次峰会,与制造业精英企业以及行业专业人士共同分享制造业在智能工厂推进过程中的成功经验,探讨工厂改进中

【linux 常用命令】查看gpu、显卡常用命令
1.查看显卡基本信息 lspci | grep -i nvidia 2.查看显卡驱动版本 nvidia-smi -a 3.查看gpu使用情况 nvidia-smi (spam) [dongli@dt-gpu-1 train]$ nvidia-smi Fri Sep 27 16:42:33 2019 +----------------------------------------
图形API学习工程(12):讨论当前工程里同步CPU与GPU的方式
工程GIT地址:https://gitee.com/yaksue/yaksue-graphics 简单讨论CPU和GPU间的交互 《DX12龙书》在【4.2 CPU与GPU间的交互】章节中讨论了这个问题,简单来说: 为了最佳性能,CPU和GPU这两种处理器应该尽量同时工作,少“同步”。因为“同步”意味着一种处理器以空闲状态等待另一种处理器,即它破坏了“并行”。 但有时,又不得不进行二者的同步

pytorch gpu国内镜像下载,目前最快下载
前言 pytorch的cpu的包可以在国内镜像上下载,但是gpu版的包只能通过国外镜像下载,网上查了很多教程,基本都是手动从先将gpu版whl包下载下来,然后再手动安装,如何最快的通过pip的命令安装呢?下面我细细讲下。 解决办法 目前国内有pytorch的gpu版的whl包只有阿里云上的:https://mirrors.aliyun.com/pytorch-w

国产GPU公司:传原地解散
经“芯视点”从多方获悉,国产GPU公司象帝先在今天宣布解散。 据资料显示,象帝先计算技术(重庆)有限公司成立于2020年9月,是一家高性能通用/专用处理器芯片设计企业。公司总部注册在重庆,已在北京、上海、重庆、成都、苏州等地设立了研发中心。象帝先公司由国内计算机及高端芯片领域的顶尖科学家领军,集中了一批平均从业经验超过15年的资深专家。 其中,公司创始人唐志敏是国内计算机系统与处理器芯

xAI巨无霸超级计算机上线:10万张H100 GPU,计划翻倍至20万张
在短短四个多月的时间里,埃隆·马斯克的X公司(前身为Twitter)推出了世界上最强劲的人工智能训练系统。名为Colossus的超级计算机使用了多达10万张NVIDIA H100 GPU进行训练,并计划在未来几个月内再增加5万张H100和H200 GPU。 “本周末,xAI团队启动了我们的Colossus 10万张H100训练集群,”埃隆·马斯克在X平台上写道,“从头到尾只用了122天。Co

【论文分享】GPU Memory Exploitation for Fun and Profit 24‘USENIX
目录 AbstractIntroductionResponsible disclosure BackgroundGPU BasicsGPU architectureGPU virtual memory management GPU Programming and ExecutionGPU programming modelGPU kernelDevice function NVIDIA

GPU算力租用平台推荐
国内知名云计算平台14: 阿里云:国内领先的云计算服务提供商,GPU 算力租用服务通过 ECS(Elastic Compute Service)实例提供。提供多种 GPU 实例类型,如 NVIDIA Tesla V100、P100 等,适用于 AI 训练、视频编解码等应用。优势在于中国市场领先,在中国本地有广泛的用户基础和完善的服务支持;拥有强大的数据处理能力,提供 MaxCompute、Data
windows 机器学习 tensorflow-gpu +keras gpu环境的 相关驱动安装-CUDA,cuDNN。
本人真实实现的情况是: windows 10 tensorboard 1.8.0 tensorflow-gpu 1.8.0 pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ tensorflow-gpu==1.8.0 Keras 2.2.4 pip
【深度学习 卷积】利用ResNet-50模型实现高效GPU图片预测
本文介绍了如何使用训练好的ResNet-50模型进行图片预测。通过详细阐述模型原理、训练过程及预测步骤,帮助读者掌握基于深度学习的图片识别技术。 一、引言 近年来,深度学习技术在计算机视觉领域取得了显著成果,特别是卷积神经网络(CNN)在图像识别、分类等方面表现出色。ResNet-50作为一种经典的CNN模型,以其强大的特征提取能力和较高的预测准确率,在众多领域得到了广泛应用。本文将介绍如何使

LLaMA-Factory仓基础功能架构及NPU/GPU环境实战演练
LLaMA-Factory 基础篇 LLaMA-Factory简介 LLaMA-Factory是一个开源的大规模语言模型微调框架,设计用于简化大模型的训练过程。它提供了一个统一的平台,支持多种大模型的微调,包括LLaMA、BLOOM、Mistral等,旨在帮助用户快速适应和调整这些模型以适应特定的应用场景。LLaMA-Factory通过提供一套完整的工具和接口,使用户能够轻松地对预训练的
查询GPU版本以及PyTorch中使用单GPU和多GPU
文章目录 多GPU介绍GPU可用性及版本检查使用单个GPU使用多个GPU 多GPU介绍 多GPU是指使用多个显卡来同时进行计算,以加速深度学习模型的训练和推断。每个GPU都有自己的内存和计算能力,通过同时利用多个GPU可以并行地执行模型的计算,从而提高整体的计算效率。 GPU可用性及版本检查 import torchif torch.cuda.is_available(
PyTorch Demo-5 : 多GPU训练踩坑
当数据量或者模型很大的时候往往单GPU已经无法满足我们的需求了,为了能够跑更大型的数据,多GPU训练是必要的。 PyTorch多卡训练的文章已经有很多,也写的很详细,比如: https://zhuanlan.zhihu.com/p/98535650 https://zhuanlan.zhihu.com/p/74792767 不过写法各异,整合到自己的祖传代码里又有一些问题,在此记录一下踩
为什么深度学习用GPU而不是CPU
首先,我们深度理解一下中央处理器(Central Processing Unit,CPU)的核心。 CPU的每个核心都拥有高时钟频率的运行能力,和高达数MB的三级缓存(L3Cache)。 它们非常适合执行各种指令,具有分支预测器、深层流水线和其他使CPU能够运行各种程序的功能。 然而,这种明显的优势也是它的致命弱点:通用核心的制造成本非常高。 它们需要大量的芯片面积、复杂的支持结构(内存接口、内核

GPU版pytorch安装(win/linux)
参考: Pytorch环境配置——cuda、、cudnn、torch、torchvision对应版本(最全)及安装方法-CSDN博客 Previous PyTorch Versions | PyTorch 法1:命令安装 如: conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda
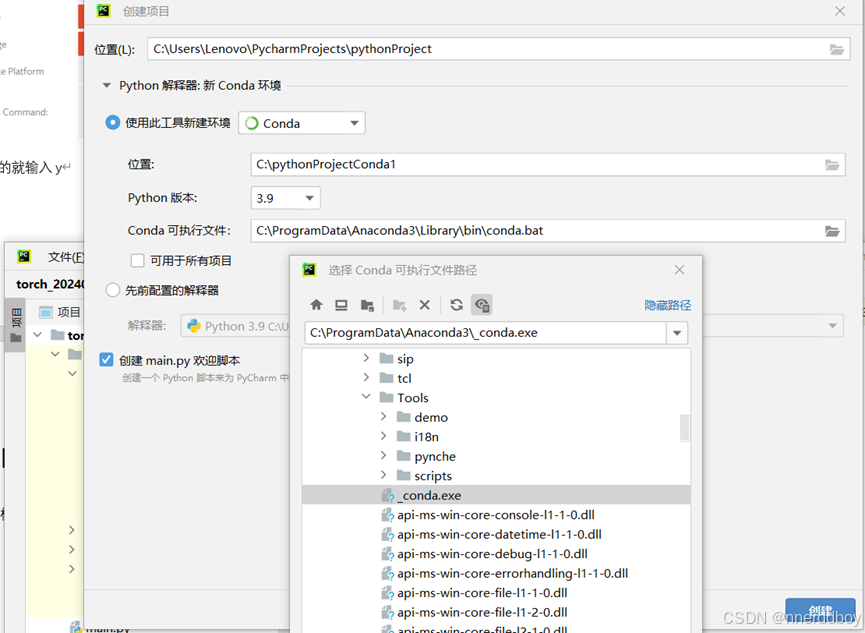
GPU环境配置:1.CUDA、Anaconda、Pytorch
一、查看显卡适配CUDA型号 查看自己电脑的显卡版本: 在 Windows 设置中查看显卡型号:使用 Windows + I 快捷键打开「设置」,依次点击「系统」-「屏幕」和「高级显示器设置」,在「显示器 1」旁边就可以看到显卡名称。 右键点菜单图标,选择系统,查看自己的Windows版本 右键菜单,设备管理器,点开“显示
GPU云服务器平台对比!哪家最值得推荐?
我的知乎文章:GPU云服务器平台对比!哪家最值得推荐? - 知乎 (zhihu.com) 对象是做人工智能NLP的,让我也有一些兴趣想学一下,做个简单的小应用玩玩,但是macbook显然不适合跑模型,没有一块好的GPU真是没法学啊!知乎上看到说自己学(无人指导) + 没卡 = 天坑,深以为然,我还差个卡。 另外这几年深度学习的风潮让人工智能专业增加,很多高校实验室GPU资源都不足,采购流程复杂

秃姐学AI系列之:多GPU并行 + 代码实现
目录 单机多卡并行 数据并行 VS 模型并行 总结 代码实现 从零开始实现 简单网络 向多个设备分发参数 allreduce函数 将一个小批量数据均匀地分布在多个GPU上 训练 简洁实现 训练 单机多卡并行 一台机器可以安装多个GPU(1~16个)在训练和预测时,我们将一个小批量计算切分大多个GPU来达到加速目的常用切分方案有 数据并行模型并行通道并行(数据 + 模

vs2019编译opencv+contribute+gpu
1、提前准备 vs2019、opencv4.4.0、opencv-contribute4.4.0、CUDA Toolkit 11.8(不能高于自己电脑的CUDA版本)、CUDNN8.9.6 ps:先提前准备环境 1)cmd中查看:nvidia-smi查看自己的显卡信息,不存在下述信息的话则需先安装英伟达显卡驱动程序。 从下图可知,本机显卡驱动支持的cuda最高版本为12.2,那么只需要安装

【硬件知识】从零开始认识GPU
【硬件知识】从零开始认识GPU 一、GPU的发展史简介二、GPU主要构成三、GPU与AI的关系 一、GPU的发展史简介 GPU(图形处理器)的发展史是一段充满创新与变革的历程,它不仅改变了计算机图形显示的方式,还推动了高性能计算、人工智能等多个领域的发展。以下是GPU发展史的概述及其中的一些趣闻。 GPU发展史 早期发展阶段 起源:GPU的起源可以追溯到早期的图形显示控制器,