accelerating专题

IBM Rational(R) ClearCase(R), Ant, and CruiseControl: The Java(TM) Developer's Guide to Accelerating
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Optimize your entire Java build and release process with ClearCase®, Ant, and CruiseControl Better bui
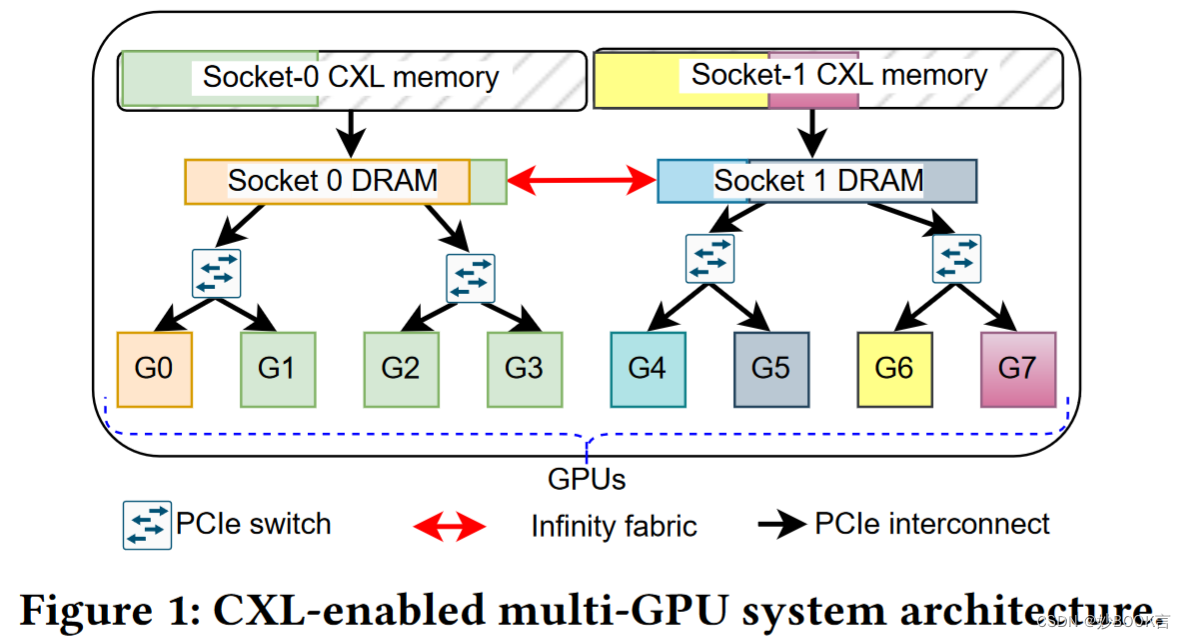
Accelerating Performance of GPU-based Workloads Using CXL——论文泛读
FlexScience 2023 Paper CXL论文阅读笔记整理 问题 跨多GPU系统运行的高性能计算(HPC)工作负载,如科学模拟和深度学习,是内存和数据密集型的,依赖于主机内存来补充其有限的板载高带宽内存(HBM)。为了促进在慢速设备到主机PCIe互连之间更快的数据传输,这些工作负载通常将内存固定在主机系统上,但对同一节点的对等GPU上运行的工作负载的主机内存造成内存容量限制。(预留部

The Key To Accelerating Your Coding Skills(加快你编码能力的关键)
The Key To Accelerating Your Coding Skills(加快你编码能力的关键) 作者 CodeAllen ,转载请注明出处 When you learn to code, there is a moment when everything begins to change. At Firehose, we like to call this the in

OSDI 2023: Userspace Bypass Accelerating Syscall-intensive Applications
我们使用以下6个分类标准对本文的研究选题进行分析: 1. 方法: **系统调用消除:**专注于完全消除 I/O 路径中的系统调用(例如 DPDK、UserspaceBypass)。**系统调用优化:**在不完全消除的情况下,旨在降低系统调用的成本(例如 io_uring、F-Stack)。**替代执行模型:**探索使用用户空间或微内核等不同执行环境来绕过系统调用(例如 QEMU、Unikern

阅读笔记——《RapidFuzz: Accelerating fuzzing via Generative Adversarial Networks》
【参考文献】Ye A, Wang L, Zhao L, et al. Rapidfuzz: Accelerating fuzzing via generative adversarial networks[J]. Neurocomputing, 2021, 460: 195-204.【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。 目录 摘要 一、介绍 二、相关工作 三
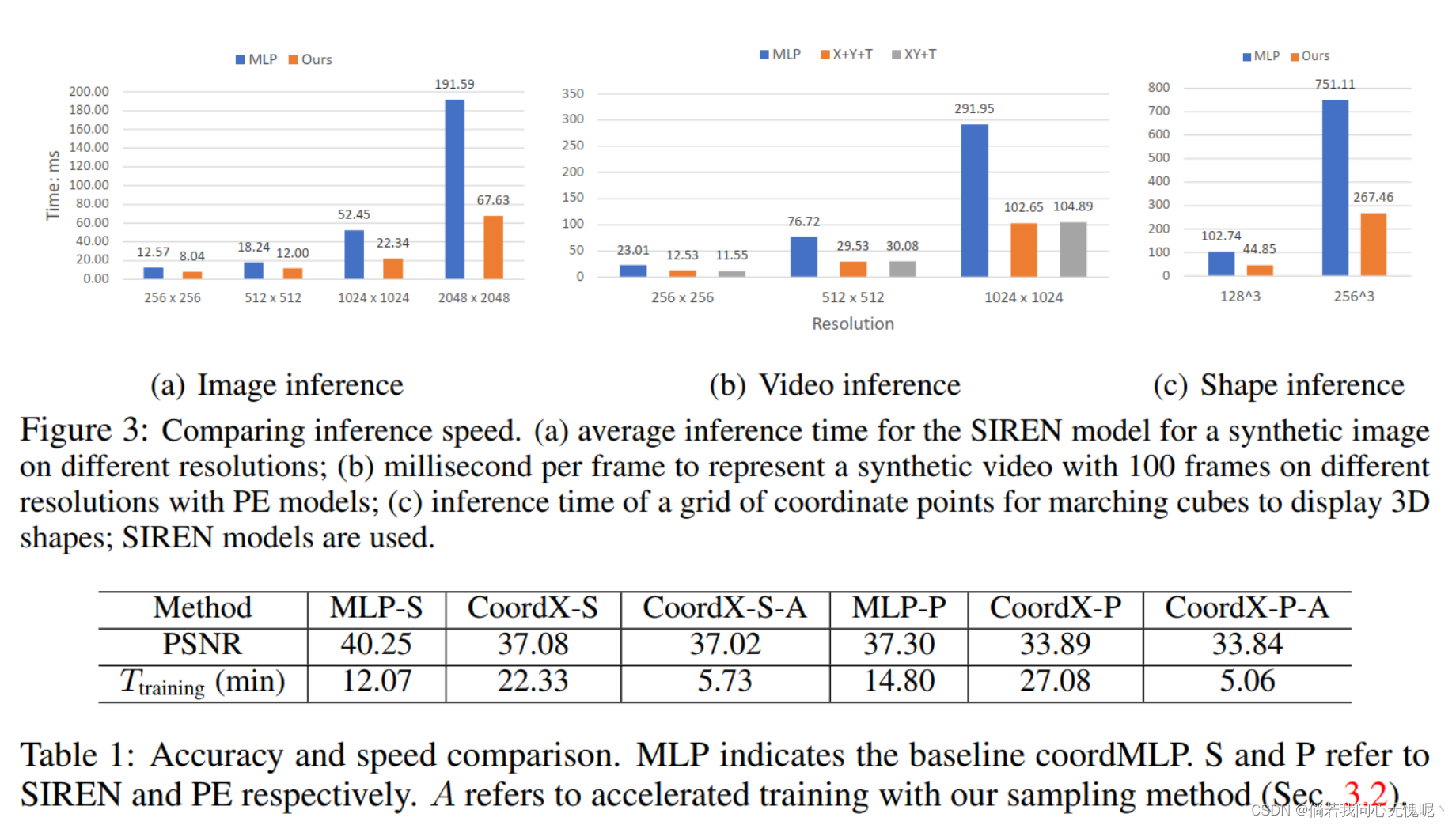
论文阅读:(arxiv 2022)COORDX: ACCELERATING IMPLICIT NEURAL REPRESENTATION WITH A SPLIT MLP ARCHITECTURE
COORDX: ACCELERATING IMPLICIT NEURAL REPRESENTATION WITH A SPLIT MLP ARCHITECTURE (arxiv 2022) Paper:https://arxiv.org/abs/2201.12425 Code:https://github.com/nexuslrf/CoordX 2022/7/21:今天中午学校终于解封了,晚上
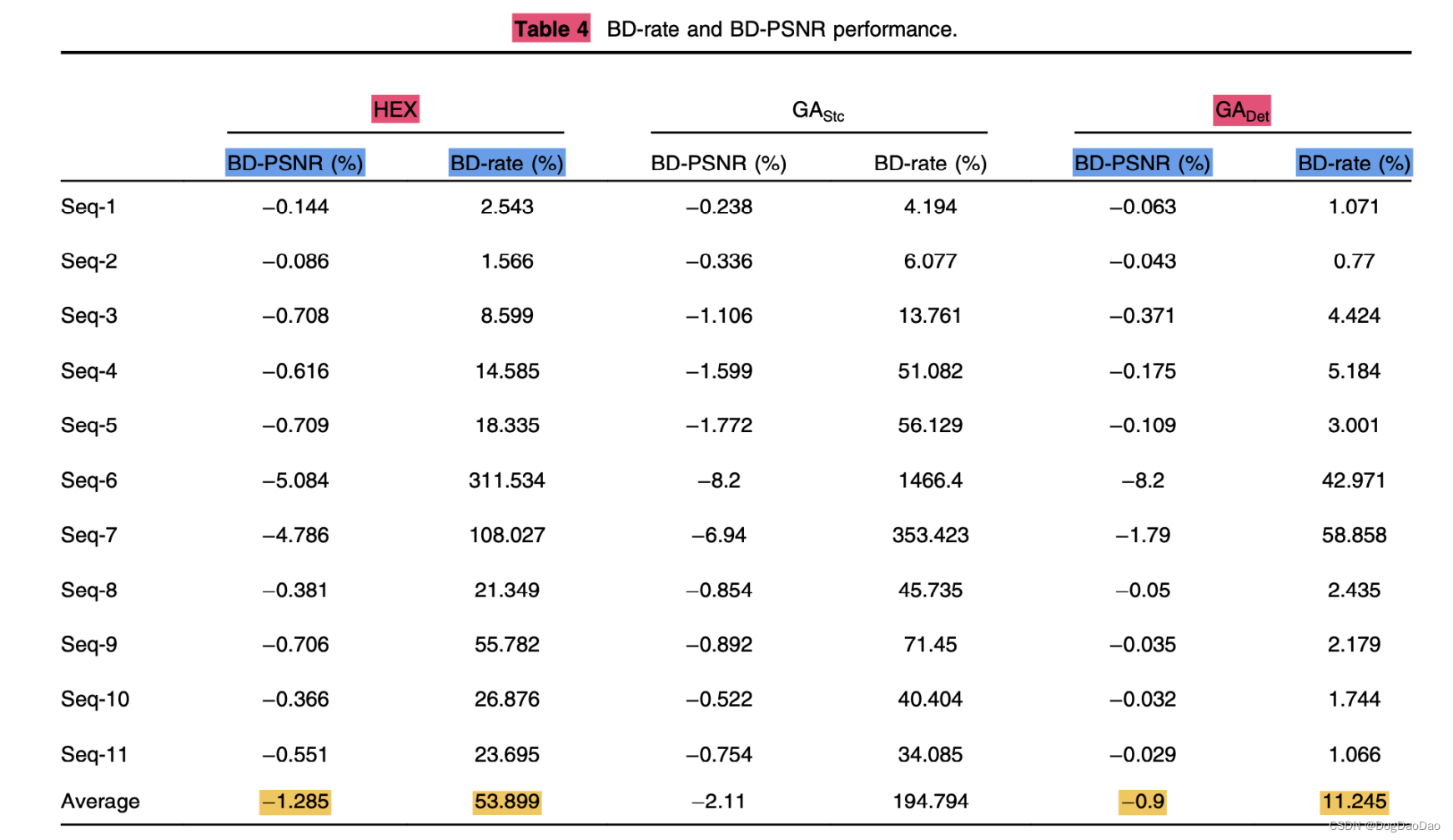
【论文解读】Accelerating motion estimation by genetic algorithm approach in x265
时间:2018 级别:SCI 机构:College of Engineering Pune 摘要: 在过去 20 年,在视频编码和压缩领域,研究人员提出了几种减少运动估计的计算量和时间的技术,本文提出了一种基于遗传算法初始种群确定的x265视频编解码器运动估计算法。遗传算法因其自适应收敛而闻名,这是由生物的适者生存过程激发的。 该方案的目标是减少B帧和P帧的整数像素块匹配运动估计算法中的搜索点(

Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
题目:Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing 边缘智能:通过边缘计算按需加速深度神经网络推理 在深度学习中,推理是指将一个预先训练好的神经网络模型部署到实际业务场景中,如图像分类、物体检测、在线翻译等。 由于推理直接面向用户,因此推理性

Faastlane: Accelerating Function-as-a-Service Workflows
简介 原文链接 摘要 在 FaaS 工作流中,一组函数通过相互交互和交换数据来实现应用程序逻辑。现代 FaaS 平台在单独的容器中执行工作流的每个函数。当工作流中的函数交互时,产生的延迟会减慢执行速度。 Faastlane通过努力将工作流的函数作为线程在容器实例的单一进程中执行,从而最大限度地减少了函数交互延迟,这通过简单的加载/存储指令简化了数据共享。对于操作敏感数据的FaaS工作流,F
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
本文是LLM系列文章,针对《NarrowBERT: Accelerating Masked Language Model Pretraining and Inference》的翻译。 NarrowBERT:加速掩蔽语言模型的预训练和推理 摘要1 引言2 NarrowBERT3 实验4 讨论与结论局限性 摘要 大规模语言模型预训练是自然语言处理中一种非常成功的自监督学习形式,但随着