本文主要是介绍【论文解读】Accelerating motion estimation by genetic algorithm approach in x265,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时间:2018
级别:SCI
机构:College of Engineering Pune
摘要:
在过去 20 年,在视频编码和压缩领域,研究人员提出了几种减少运动估计的计算量和时间的技术,本文提出了一种基于遗传算法初始种群确定的x265视频编解码器运动估计算法。遗传算法因其自适应收敛而闻名,这是由生物的适者生存过程激发的。
该方案的目标是减少B帧和P帧的整数像素块匹配运动估计算法中的搜索点(SP),该算法设置为三个参考帧。该方法构成的初始种群是视频帧不同时空位置的预编码编码单元和预定义的六边形(HEX)位置的函数。本文提出一种"确定性开始" GA (GADet),以x265结构部署。在x265代码的框架下,GADet在考虑进行实验的选定视频类别中提供了SP的减少。
为了验证所提算法的有效性,将实验结果与参考软件中基于块的快速全搜索算法和十六进制搜索算法进行了比较。采用随机构成初始种群的传统遗传算法(标记为GAStc),并与GADet进行了实证比较。所提出的GADet框架减少了运动估计时间,同时提供了可接受的峰值信噪比损失和比特率的增加。
介绍:
HEVC 相比 h264,相同 PSNR 可以实现码率节省 50% 以上;作为符合 HEVC 标准的开源编码器,x265 旨在快速、高效的HEVC 编码,具体的编码细节和文献可以在 x265 的网址上找到。
运动估计(和补偿)是关键的一步,特别是在互编码中,为视频序列的一帧中的每个运动对象计算运动矢量(MVs),从而得到残差帧。因此,自适应码率在保证视频质量的前提下运动估计起着至关重要的作用。
典型的块匹配运动估计算法(BMME)是视频标准中推荐的算法。
关于 BMME,关于BMME,研究报告了许多次优算法,如非对称六边形(HEX)搜索,增强预测带状搜索,六边形搜索,菱形搜索等,以及它们的变种也被发现由于特定的搜索模式和步长而表现不佳。
另一种流行的运动估计算法是测试区域搜索(test zone search, TZ)算法,在H.264和HEVC中都采用了该算法。Purnachand等人指出,由于TZ算法结合了各种正方形和菱形搜索模式,搜索时间较长,建议使用六边形搜索模式对TZ算法进行优化。
HEX算法具有SP约简和接近圆形图案的特性,因此HEX算法已经被选择在实际工作中。
在探索运动估计的自适应选项时,研究较少的遗传算法(genetic algorithm, GA)因其在每一代中的自适应能力而被认为是一种很有前途的解决方案。
正如所参考的文献,由于其预先决定的组织模式,如菱形、六边形和方形,BMME被发现对SP进行了限制。由于这种固定的模式,BMME算法的性能是次优的。
提出一种适用于HEVC框架的确定性GA运动估计方法。GAStc和GADet在HEVC的编码效率和复杂度进行了比较。同时快速全搜索和六边形搜索算法也被加入对比,并将所提出的GADet算法与传统方法进行了比较。
HEVC 的 AMVP 和 HEX运动估计算法
在任何搜索算法中,起始点都是开始搜索的关键。简要回顾了用于块编码的四叉树结构、HEVC中的AMVP算法和HEX ME算法,为本文提出的搜索算法奠定了基础。
块预测的四叉树结构:每幅图像被分成 CTB,CTB 进一步分成 CB 和相应的 CU,每个 CU 由PU 和 TU 组成。
AMVP:帧内预测支持 33 种角度、DC、Planar,每个 CU 的帧间预测有“inter、Merge、skip”被选择,Merge和skip指定了用于Merge的索引,从而减少了比特流的信令负担。对于帧间模式,AMVP从由空间或时间预测器组成的候选列表中预测MV,对每个预测块更新List0和List1,并向解码器发出信号。
HEX ME算法:在运动估计中,寻找匹配块的目标函数可以用块中像素的强度值表示;全搜索算法在特定的窗口内搜索参考帧的所有可能块;全搜索算法的搜索结果可以作为ME 算法的比较基准。许多快速算法被提出,如方形、菱形、HEX 等。其中 HEX 具有较好的编码性能,被当做默认搜索算法,具体过程如下图。

基于基因的ME算法的背景和介绍
遗传算法是基于自然选择理论在每一代中产生随机解。为了确定近似最优解,需要进行交叉、变异等操作。遗传算法(GA)因其快速收敛性和在搜索空间中产生多样性群体的能力而得到广泛应用。
术语和建议参数:
Genotype:基因型
MV 可以表示为 MV(x, y),它的二进制编码可以表示为如下,s 是genotype ,xi、yi 可能是 0 或 1,n 是 8。(xi, yi )组合表示搜索空间的SP 候选。
 z = (log2SRmax),其中SRmax是W/2,是搜索范围的限制参数;因此,z总是小于n,因为z表示MV以二进制形式实际需要的比特数。
z = (log2SRmax),其中SRmax是W/2,是搜索范围的限制参数;因此,z总是小于n,因为z表示MV以二进制形式实际需要的比特数。
genotype代表在搜索空间里的 MV;
对 x265 代码进行修改,搜索空间/窗口被设置成 64x64。搜索范围参数被设置为“log2SearchRange”。
本文,z 被设置为 5,为了避免交叉/变异操作跨越搜索范围的边界,n 为 8。
Initial populations :初始种群
它是一组以基因型为特征的个体。较大的种群规模增加了在几个周期内收敛的可能性。另一方面,这增加了计算的数量。为了平衡编码需求,在这个实现中根据经验选择数组的大小为10。
fitness function:适应度函数
适应度函数量化了与最优解的接近程度,在父代选择中起着关键作用。根据进化法则,“适者生存”将成为下一代的父母。一些研究人员将一个或多个父母包括在下一代数组中。一些基于范数的准则如下,当范数p为2时,通过最小化当前帧和参考帧块之间的欧氏距离来进行块匹配。
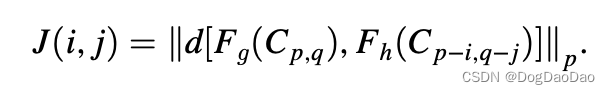
匹配准则用 SSD 来衡量,如下。
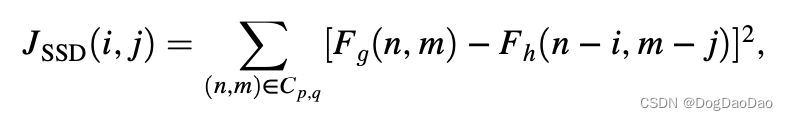
然而,SSD算法也存在不足,例如需要对每个像素进行p * q次乘法运算,如果块中有像素被噪声污染,则会因平方运算而导致误差增大。为了缓解这个问题,我们可以使用SAD,它类似于平均绝对误差:

此外,在文献中提出了结构相似度指标(SSI),由于SSI和SSD对计算复杂度的要求较高,使用SAD作为适应度函数。最小的SAD表示与参考帧的CU接近。因此,每个染色体的SAD被用作选择的排序基础。最适合的父母将成为交配池的一部分,被选中的父母将进行交叉/变异操作。
Operations on genotypes:基因型运算
个体选择:
这种选择有不同的方法,如随机选择,锦标赛选择,轮盘赌轮盘选择,根据回顾的文献。通过轮盘赌的方法选择最适合的父代,增加了选择SAD最小的父代的可能性。在这一过程中作出贡献的父母总数被称为选择压力。如果选择压力过低,收敛速度也会降低。然而,如果该值过高,将会在基因库中选择更多适合的亲本,从而增加陷入局部最小值的可能性。一旦产生初始种群,就对选择的亲本进行遗传操作,即交叉和变异,产生下一代。
交叉crossover:
在交叉操作中,来自染色体的基因在最适合的亲本之间交换。交叉和变异的样本操作如图2所示。这种重组使算法能够探索更多目标为全局最小值的SP。在最后一个比特位置和它的优先位置进行交叉,既能防止跨越搜索范围边界的随机化,又能保证在同一象限产生SP。当搜索范围为64 × 64时,基因载体的大小根据搜索范围的不同而发生相应的变化。
变异mutation:
它的主要功能是搜索空间中的“未知方向”。因此,该基因中的任何一条染色体都可以进行学术翻转,如图2的下部所示。一般来说,在遗传算法中,变异的概率非常低。在我们的工作中,每隔第五代,就会发生两个突变,即突变概率为0.04。建议在位置x和y坐标的最重要位置进行突变。

Termination criteria:终止准则
更早地终止搜索可以节省时间,也减少了搜索算法中的计算次数。迭代次数多会增加计算复杂度,而迭代次数少可能不会导致解的收敛。决定将最大迭代次数限制为10次,这是启发式选择的。其他终止准则SAD为15,与x265参考代码中使用的HEX算法相同。
GAStc和GADet 算法
GAStc是传统的基因算法,GADet是本文提出的确定起始点基因算法。
对于ME上下文,初始种群是在搜索区域内从视频前一参考帧确定生成的十二个SP。
对于GADet,初始种群如下图,
● (a)所示为当前CU位置周围8个SP的HEX种群。考虑到水平方向运动的概率较大,HEX有6个点在水平方向,2个点在垂直方向。
● (b)所示的时空预测器对先前CU的四个预测MVs。它们分别是空间近邻CU的均值MV,同位CU在参考帧的均值MV,零位表示前一帧坐标相同的位置,最后一个是时间候选CU的均值。
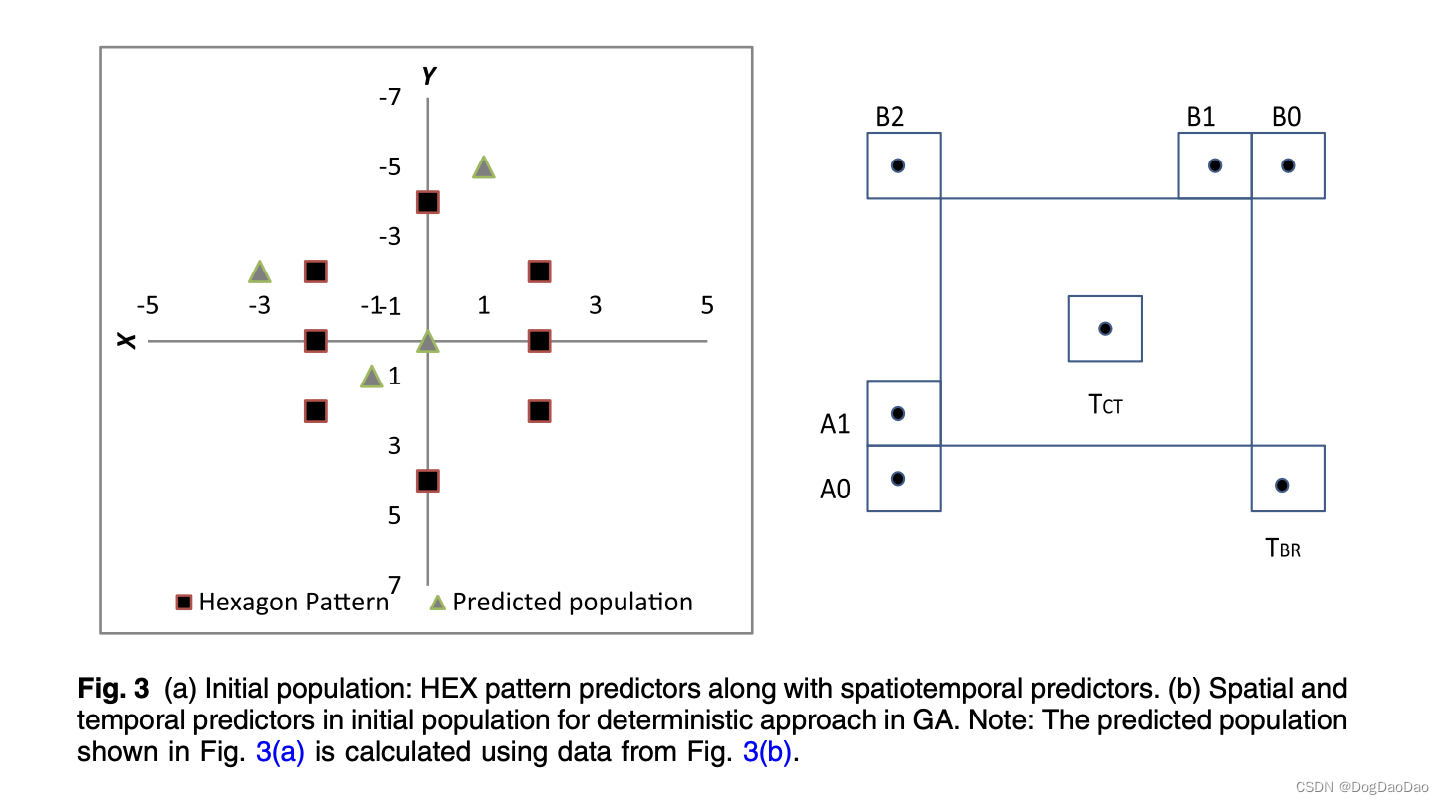
AMVP算法中4个候选时空序列的贡献图如图3(b)所示。
● 左候选(A0 或 A1,任意先来的一个)
● 上候选(B0、B1、B2,任意先来一个)
● 时域下右TBR和时域相同位置 TCT
在 GADet 中使用的参数如图 4,总结如下:
- 初始种群选择基于 HEX 的 SP 和时空预测器
- SAD 被用作适应度函数
- 配对池的选择采用轮盘赌法
- 对于64 × 64的搜索范围,最后两位选择交叉
- 每5个周期后进行变异
- 终止是在10个周期后或SAD < 15

GA~Det~算法的执行:
step1:初始化
● Search_range = 64,产生坐标coordinates的搜索范围尺寸
generations = 10; 遗传算法中的代的数量
● populationi,j = [0, 0],用于GA的种群数组,分别存储x和y,其中 i = 1,2…12,j = 1, 2
● coordinatesk,l = [0, 0]
repeat = false, 检查每代重复后计算cost值的最终坐标,其中 k = 1,2…12,l = 1, 2
● probn = 0
cdfm(probn )= 0,根据轮盘赌找到每个候选的概率,其中 n,m = 1,2…12
● sadcost = 0
sum = 0
bcost = 15;适应度函数,如果新的SAD和当前的SAD之间的差是15,那么新的MV坐标将被更新为最佳MV
● Final_populationp,q = [0, 0],最终选择进行交配的种群, p = 1,2…12,q = 1, 2
step2:确定性方法的编码
● populationi,j = 初始种群生成来自 AMVP 和 HEX 坐标生成的数组
● coordinatesk,l = 检查populationp,q 矩阵是否有重复元素,并相应的修改 repeat 标志,生成不包括重复 SP 的coordinatesk,l 数组
step3:适应度函数值计算
● “COST MV X4 DIR” 函数计算 cost代价值,"COPY 1 IF LT"函数比较sadcost~k, l~的cost 代价
step4:计算代价值的概率和累积分布函数
● sum = sum + sadcostk,l所有 SAD 值的求和
● 轮盘赌的概率计算:
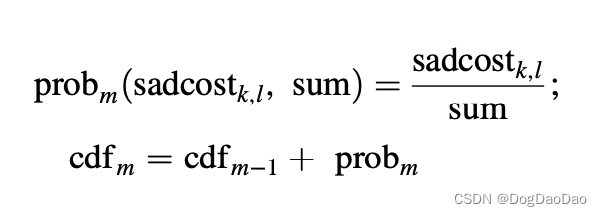
● 根据概率值对coordinatesk,l进行排序
step5:新种群的一代
● 根据轮盘赌中的值更新Final_populationp,q我们为下一代选择最适合的坐标,称为交配池
● 如果generations < 5,执行交叉操作,否则,如果generations = 5,执行变异操作
step6:终止
● 如果上一次迭代的最小SAD与当前最小SAD之差<它们平均值的0.1%;转到第二步。否则如果迭代次数<10; 转到步骤2
● 更新sadcost的值,然后转到子像素 ME
GAStc算法的编码:
在 step 1 中使用 c++库函数 rand()来初始化
populationi,j = rand(),其中 i = 1,2…12,j = 1, 2
其余跟GADet相似。
由于在实验中GA是应用于PU级的,因此终止准则足以处理PU级的收敛。然而,为了进一步评估平均性能,重复实验以测试其收敛性,使最终PSNR的变化小于前10次迭代的平均值的1%(这表明接近全局最小值)。下一节将给出ME时间需求、每帧SP、BD-PSNR和BD-rate的平均结果以及它们的分析。
实验结果
测试条件:x265-1.7、CMAKE-3.5.8、YASM-1.2.0
编码参数:QP{22、27、32、37}、profile=main、leve=4.1、keyint=250、maxcusize = 64
实验设备: Ubuntu 12.04 、i5-3210 2.5GHz、4G RAM
结论:GADet技术采用确定性方法,使用AMVP减少了搜索范围内SP的数量。与传统的随机遗传算法相比,重用已有的AMVP可以减少算法初始种群的计算量。实验结果表明,对于整个测试视频集,该算法比六边形算法和随机遗传算法(GAStc)的速度更快。对于所有的视频序列,SP的节省是该算法的一个关键特点。在使用GADet的情况下,相比较全搜索算法,总的ME模块时间节省了83%到98%。在BD-rate增加11.245%的情况下,平均BD-PSNR损失为0.9%,在视频编码可接受范围内;与其形成对比的HEX的 BD-rate 增加53.889%,平均 BD-PSNR 损失1.285%,随机遗传算法(GAStc)的 BD-rate 增加194.794%,平均 BD-PSNR 损失2.11%。对于ME算法,GADet算法的编码效率也优于HEX算法和GAStc算法。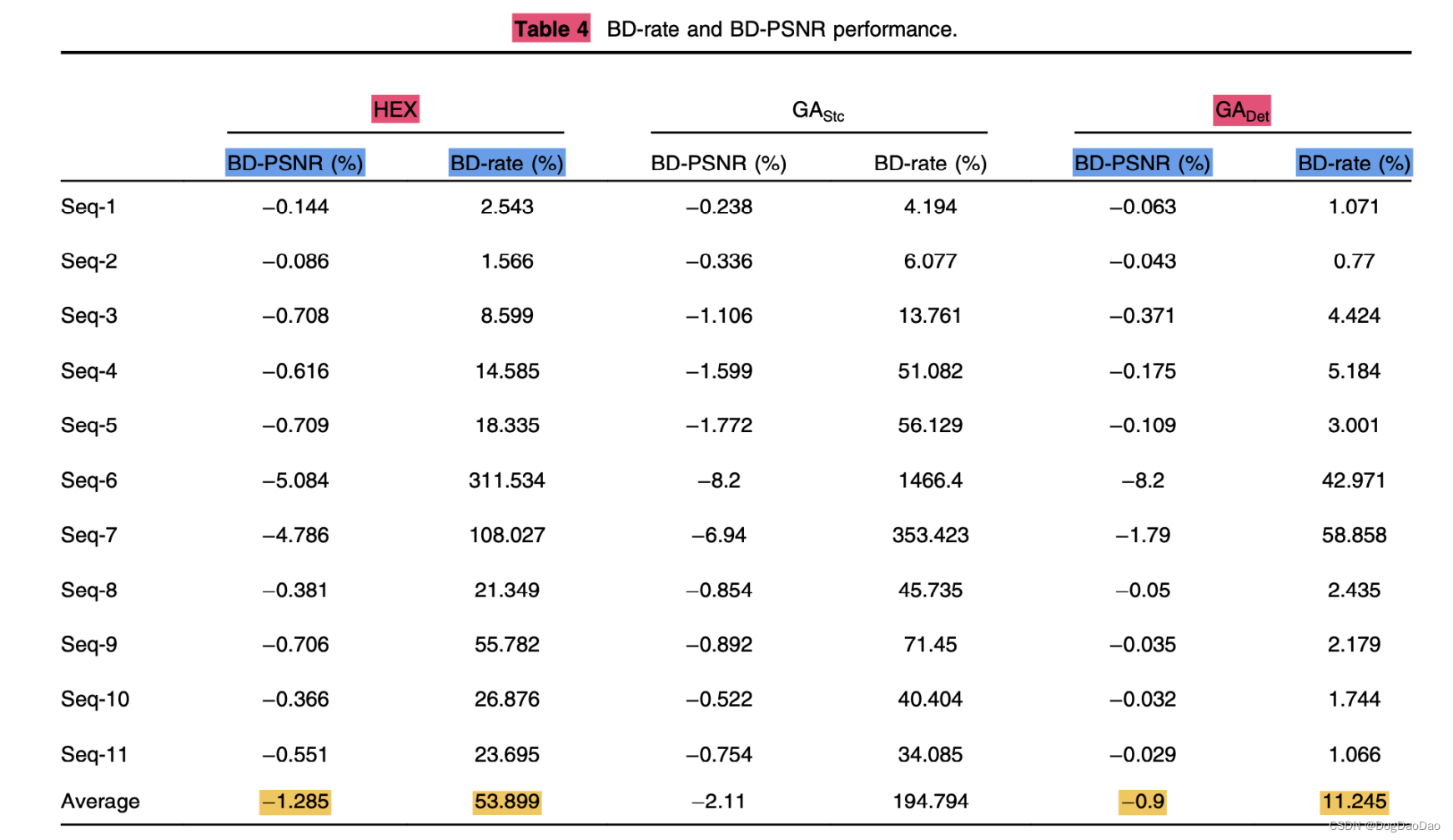
这篇关于【论文解读】Accelerating motion estimation by genetic algorithm approach in x265的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



