本文主要是介绍A Novel Distributed File System Using Blockchain Metadata——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Wireless Personal Communications 2023 Paper 分布式元数据论文阅读笔记整理
问题
随着来自不同来源(如在线社交媒体、物联网、移动数据、传感器数据、黑匣子数据等)的大量数据以指数级的速度增长,集群计算已成为数据处理中不可避免的一部分。分布式文件系统定义了不同的方法来在不同的集群计算节点之间分发、读取和删除文件。但流行的分布式文件系统(如Google file System和Hadoop distributed file System)集中存储元数据,可能产生单点故障,从而需要备份和替代解决方案在故障时恢复元数据。此外,名称节点服务器是使用昂贵且可靠的硬件构建的,对于中小型集群,维护昂贵的名称节点服务器是不划算的,而使用廉价的商品硬件作为替代又很容易出现硬件故障。
本文方法
本文提出了一种新的无中心名称节点的分布式文件系统 DFS-DM,在对等网络连接的集群上分发文件。该文件系统使用分布式共识和哈希来分发元数据。尽管分布式元数据对公众可见,但方法确保了它是不可变的和无可辩驳的。

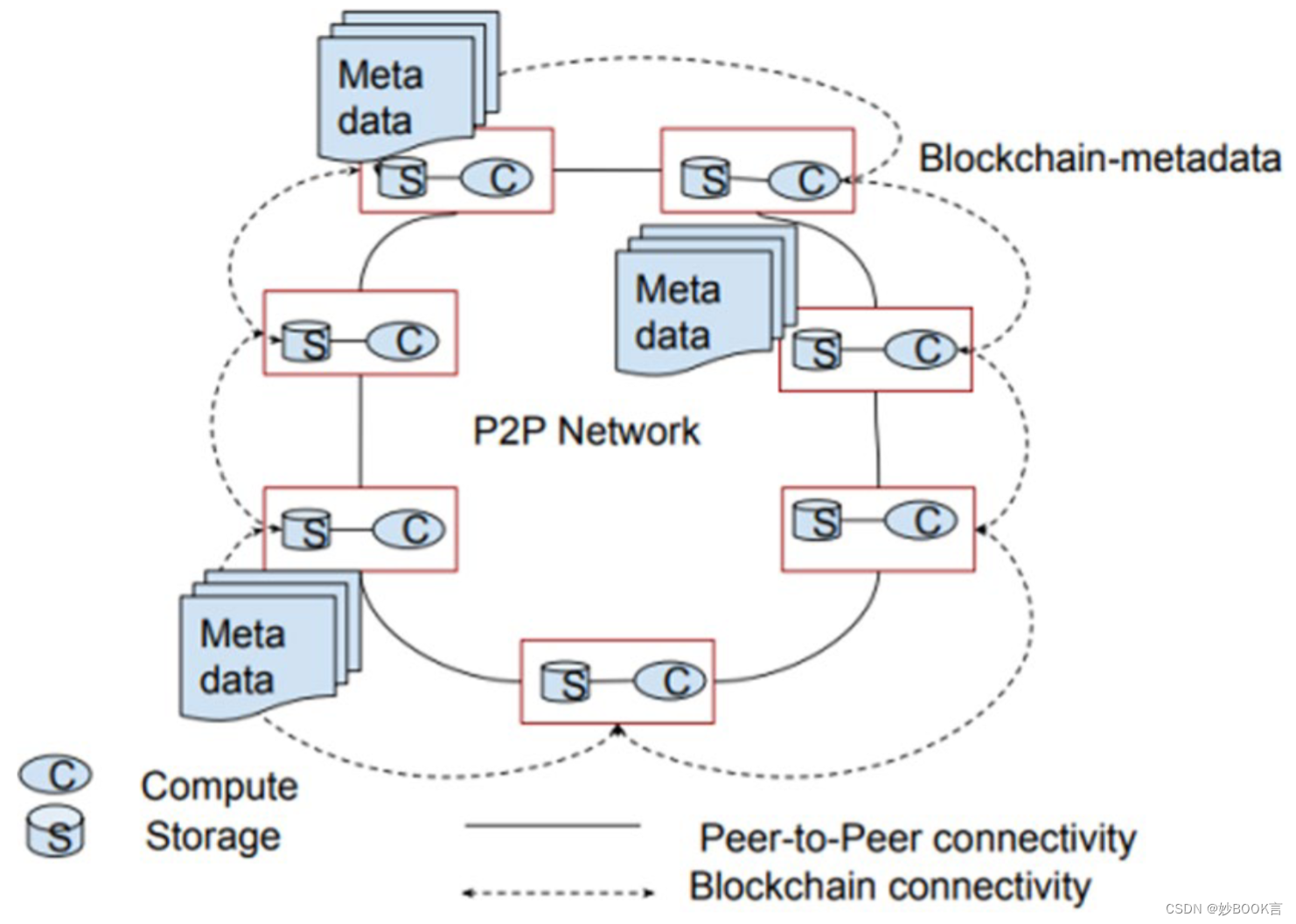
几个特性:
-
通过将单个辅助副本作为副本和奇偶校验文件来维护,从而提供高可用性。如果单个节点出现故障,则会自动提取辅助副本。如果辅助副本也出现故障,则使用与数据文件一起存储的奇偶校验文件来重建相应的块。
-
添加CRC校验和文件来提供错误检测过程。
-
遵循P2P网络配置,对网络上的所有节点具有同等优先级,使用廉价的商品硬件实现。
-
使用区块链将元数据分发给P2P网络上的所有对等体。
所提出的文件系统已在谷歌云平台上成功测试,并与Hadoop分布式文件系统进行了比较,实现了更好的效果。
实验
实验对比:读写时间、执行时间
实验参数:数据大小
总结
使用区块链的思想构建分布式文件系统元数据。避免使用昂贵的单个名称节点,使用多个廉价硬件,通过分布式共识确保元数据不被修改,通过单个辅助副本和奇偶校验进行故障恢复。
这篇关于A Novel Distributed File System Using Blockchain Metadata——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![Java实现将byte[]转换为File对象](/front/images/it_default2.jpg)






