distributed专题

终止distributed tensorflow的ps进程
1.直接终止: $ ps -ef | grep python | grep 文件名 | awk {'print $2'} | xargs kill文件名为当前运行的程序,名称如:distribute.py 2.查找pid,后kill: $ ps -ef | grep python | grep 文件名 | awk {'print $2'}$ kill -9 <pid>
Java后端分布式系统的服务调用链路分析:Distributed Tracing
Java后端分布式系统的服务调用链路分析:Distributed Tracing 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 在分布式系统中,服务之间的调用关系错综复杂,Distributed Tracing(分布式追踪)技术可以帮助我们清晰地追踪请求在系统中的流转路径,分析性能瓶颈和故障原因。 分布式追踪概述 分布式追踪通过为每个请求生成唯一的追踪

大数据-Hadoop-HDFS(一):数据存储模块(Hadoop Distributed File System,分布式文件系统)【适合一次写入,多次读出的场景】【可以追加数据,但不可修改已有数据】
一、HDFS概述 1、HDFS产出背景及定义 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位

【AMBA Bus ACE 总线11 -- ACE DVM(Distributed Virtual Memory)使用介绍】
文章目录 ACE DVM 使用背景DVM Transactions 类型和作用DVM 消息使用场景DVM 示例Sumamry ACE DVM 使用背景 当 Cache maintenance 指令操作完以后,落实到总线上的时候,它会有一组 cache maintenance transaction 出来,这组 cache maintenance transaction 主要是
理解Spark中RDD(Resilient Distributed DataSet)
1。Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是一个可以并行操作的容错的容错集合。 创建RDD有两种方法:并行化驱动程序中的现有集合,或引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase或提供Hadoop InputFormat的任何数据源。 val sc = spark.sparkContext // 已有内部数据源val data = Array(1, 2,

redis-distributed-id-generator-start之id生成器压测的一些思考
文章目录 1.测试工程集成id生成器2.新建表3.测试代码4.jemeter压测结果预期5.总结 1.测试工程集成id生成器 省略–参考之前的文章 https://mp.weixin.qq.com/s/B1vcrPVnFI1pKH7RAnPQ5ghttps://blog.csdn.net/qq_34905631/article/details/138121262?s
No module named ‘torch.distributed.checkpoint.format_utils问题解决
完整代码: Traceback (most recent call last):File "/data/user/BMLU-use/src/English_chat/qwen1.5.py", line 97, in <module>main(model_path=args.model_path,max_length=args.max_length,name=args.name)File "/da

Bigtable: A Distributed Storage System for Structured Data
2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,底层依赖 GFS 存储,上层供 MapReduce 查询使用 Abstract 是一种分布式结构化数据存储管理系统,存储量级是PB级别。存储的数据类型和延时要求差异都很大。论文介绍数 bigtable 的数据模型。 Introduction BigTable 达成了几个目标:适用面广、伸缩性好、高性能、高可用。即可以满足

MapReduce的Map Size Join以及Distributed Cache
首先介绍Distributed Cache(分布式缓存),主要功能是把DataNode(客户端)一些小的文件送到DataNode上。 1. 通过job.addCacheFile(new Path(filename).toUri) 2.通过job.addCacheFile(new URI("xx/xxx/xxx/xx.json#customer_type")) 通过1和2来传过去(都是U
SQL Server 'Ad Hoc Distributed Queries' 的 STATEMENT'OpenRowset/OpenDatasource' 的访问的方法
1、开启Ad Hoc Distributed Queries组件,在sql查询编辑器中执行如下语句: exec sp_configure 'show advanced options',1reconfigureexec sp_configure 'Ad Hoc Distributed Queries',1reconfigure 2、关闭Ad Hoc Distributed Quer
linux下安装zookeeper(Standalone与Distributed模式)
环境准备 三台虚拟机:spark1,spark2,spark3 三台虚拟机已经实现免密码登录 一、搭建zookeeper的Standalone(单机)模式,在spark1上搭建。 1.向服务器上传zookeeper-3.4.6.tar.gz(版本自行选择),或通过wget下载 [root@spark1 soft]# wget http:

Ray: A Distributed Framework for Emerging AI Applications
Ray是UC Berkeley RISELab新推出的高性能分布式执行框架,目前还处于实验室阶段,具有比Spark更优秀的性能,有望在将来取代Spark。本篇博客是对该论文的简单翻译,如有翻译不妥的地方,欢迎指正。 原论文 pdfRay开发手册 Ray-Guide项目下载 Ray 0 简介 下一代AI应用程序将不断与环境交互,并从这些交互中学习。这些应用程序在性能和灵活性方面提出了新的和
VMware vSphere Distributed Services Engine 和利用 DPU 实现网络加速
VMware相关学习专栏:虚拟化技术 vSphere 8.0 通过加速数据处理单元 (DPU) 上的网络功能实现了突破性的工作负载性能。 vSphere 8.0 通过加速 DPU 上的网络功能实现了突破性工作负载性能,从而满足现代分布式工作负载的吞吐量和延迟需求。借助 vSphere Distributed Services Engine,基础架构服务分布在 ESXi 主机上可用的不同
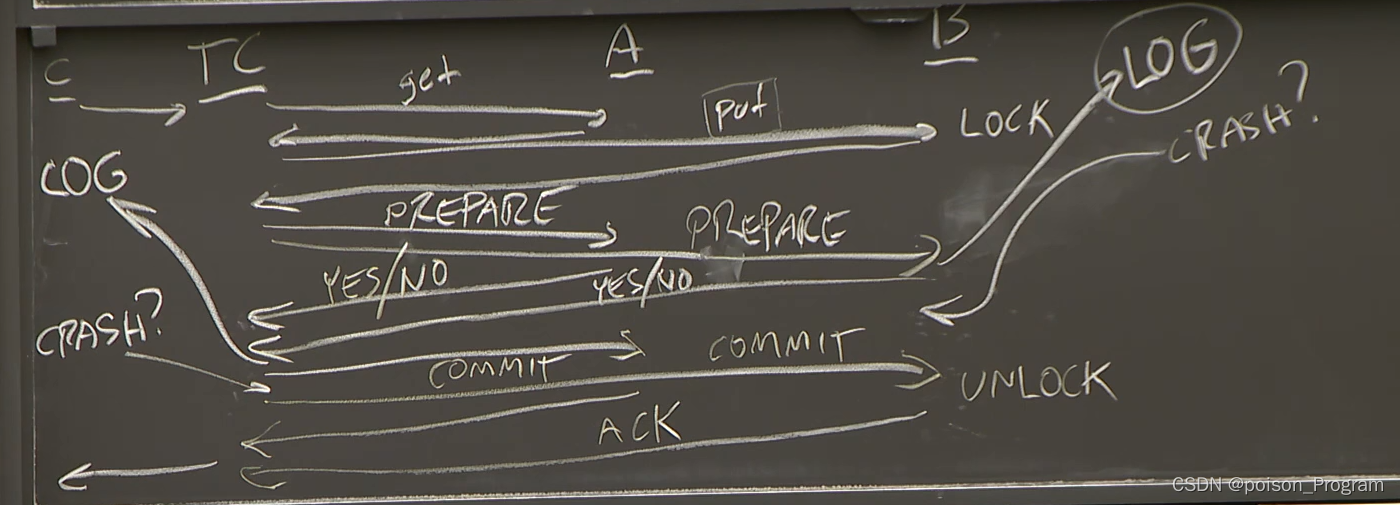
Distributed Transactions Mit 6.824
Topic1:distributed transactions = concurrency control + atomic commit 传统计划:事务 程序员标记代码序列的开始/结束作为事务。 事务示例 x 和 y 是银行余额——数据库表中的记录。x 和 y 位于不同的服务器上(可能在不同的银行)。x 和 y 开始时都是 $10。T1 和 T2 是事务。 T1: 从 x 向 y 转账
【APM】在Kubernetes中,使用Helm安装loki-distributed 2.9.6
1、Loki简介 Grafana Loki 是一个开源的云原生日志聚合和分析系统,由 Grafana Labs 开发并维护。Loki 专注于为大规模的日志处理提供经济高效且易于管理的解决方案,尤其适用于微服务架构以及容器化和分布式环境。 以下是 Loki 的核心特性与设计原则: 标签驱动存储: Loki 不对完整的日志内容进行索引,而是仅对每个日志流(log stream)定义的一组标签(
torch.distributed.launch使用中的问题
error:unrecognized argument: --local-rank=0 link AttributeError: module numpy has no attribute int solu AttributeError: ‘MMDistributedDataParallel’ object has no attribute ‘_use_replicated_te
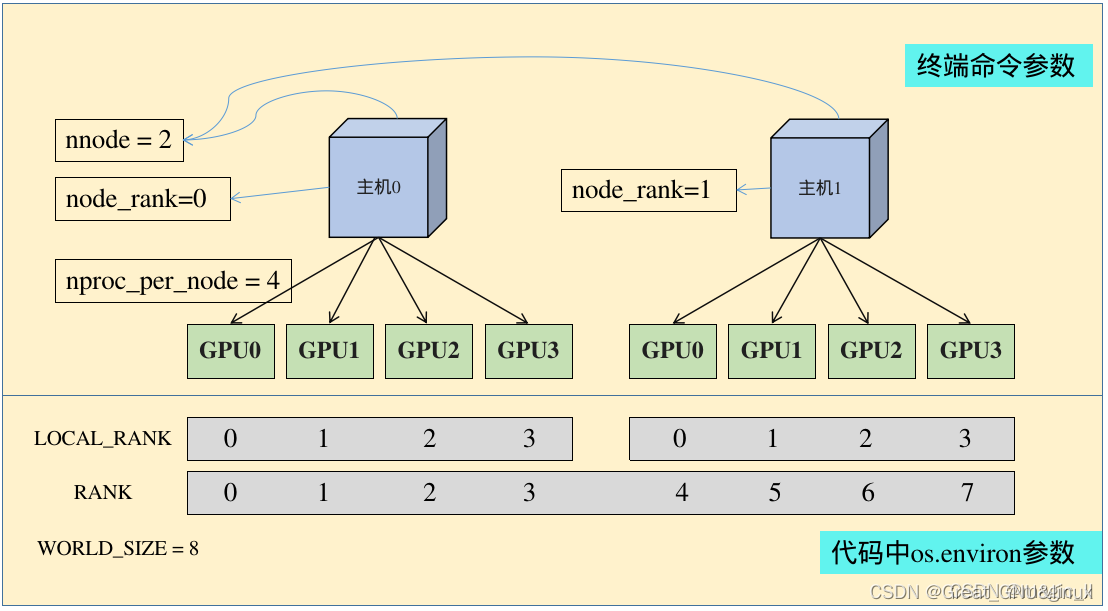
Pytorch分布式train——pytorch.distributed.launch V.S. torchrun
1. 较早的pytorch.distributed.launch python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 train.py --args XXX 参数解析: nnodes:节点(主机)的数量,通常一个节点对应一个主机 node_rank:指的是当前启动的是第几台服务
Fundamentals of Distributed Object Systems: The CORBA Perspective
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Distributed Object Computing teaches readers the fundamentals of CORBA, the leading architecture for desi
Java(TM) Network Programming and Distributed Computing
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp An accessible introduction to the changing face of networking theory, Java technology, and the fundamenta
Design and Analysis of Distributed Algorithms
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Design And Analyze algorithms for distributed computing environments Design and Analysis of Distribute
Distributed Systems Architecture: A Middleware Approach
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Middleware is the bridge that connects distributed applications across different physical locations, wi
Codeforces1401 D. Maximum Distributed Tree(DFS)
You are given a tree that consists of 𝑛 nodes. You should label each of its 𝑛−1 edges with an integer in such way that satisfies the following conditions: each integer must be greater than 0; the p
CassandraAppender - distributed logging,分布式软件logback-appender
农历年最后一场scala-meetup听刘颖分享专业软件开发经验,大受启发。突然意识到一直以来都没有完全按照任何标准的开发规范做事。诚然,在做技术调研和学习的过程中不会对规范操作有什么严格要求,一旦技术落地进入应用阶段,开始进行产品开发时,只有严格按照专业的软件开发规范才能保证软件产品的质量。刘颖在meetup中提到了异常处理(exception handling)和过程跟踪(logging
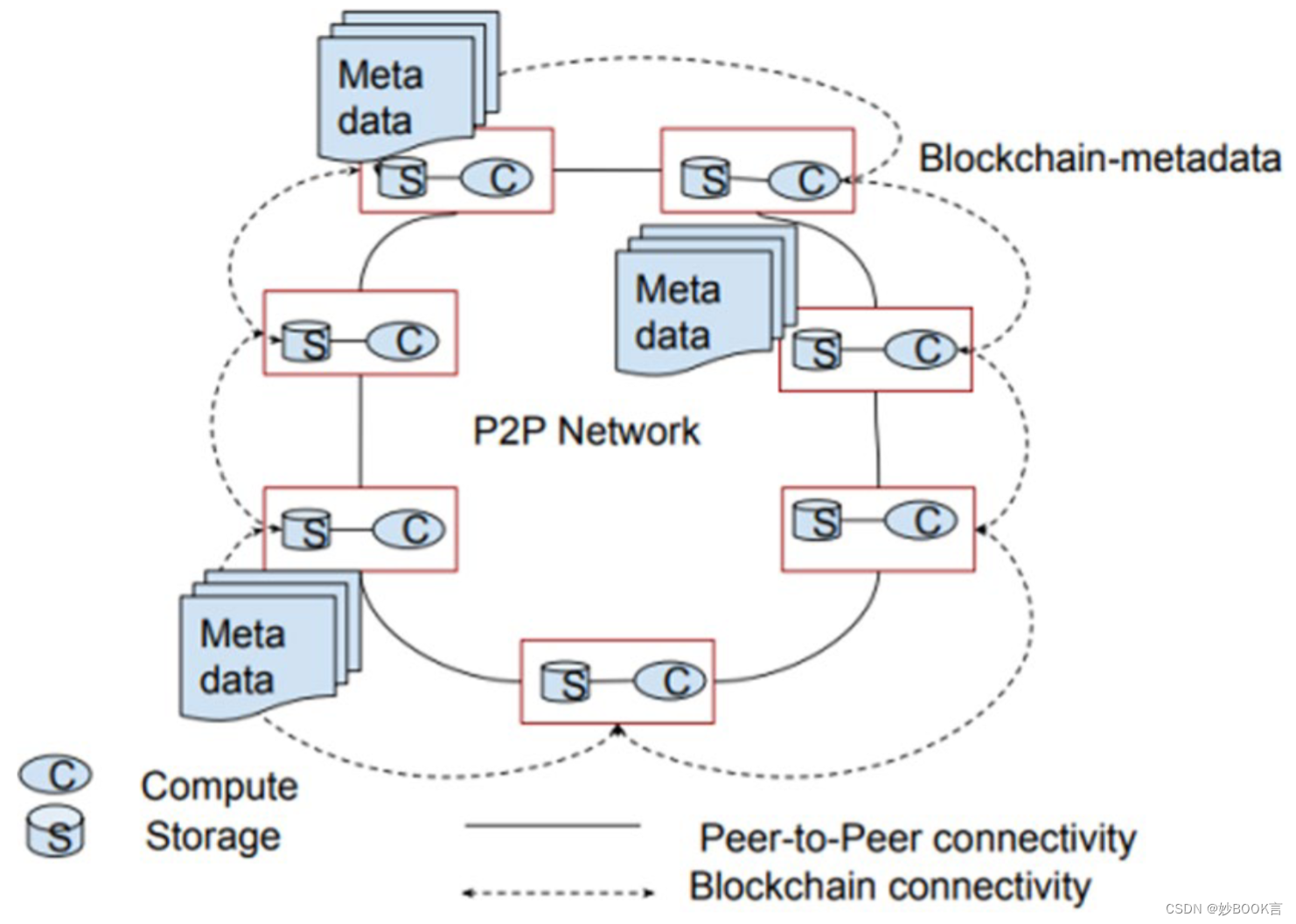
A Novel Distributed File System Using Blockchain Metadata——论文泛读
Wireless Personal Communications 2023 Paper 分布式元数据论文阅读笔记整理 问题 随着来自不同来源(如在线社交媒体、物联网、移动数据、传感器数据、黑匣子数据等)的大量数据以指数级的速度增长,集群计算已成为数据处理中不可避免的一部分。分布式文件系统定义了不同的方法来在不同的集群计算节点之间分发、读取和删除文件。但流行的分布式文件系统(如Google fi
使用sp_configure启用 'Ad Hoc Distributed Queries'
1.启用Ad Hoc Distributed Queries: exec sp_configure 'show advanced options',1 reconfigure exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure 2.为了安全使用完成后,关闭Ad Hoc Distributed Queries
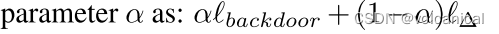
A Little Is Enough: Circumventing Defenses For Distributed Learning
联邦学习的攻击方法:LIE 简单的总结,只是为了能快速想起来这个方法。 无目标攻击 例如总共50个客户端,有24个恶意客户端,那么这个时候,他需要拉拢2个良性客户端 计算 50 − 24 − 2 50 − 24 = 0.923 \frac{50-24-2}{50-24}=0.923 50−2450−24−2=0.923,然后查正态分布的表,找到对应的z值,修改恶意客户端的参数即可。