本文主要是介绍MapReduce的Map Size Join以及Distributed Cache,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
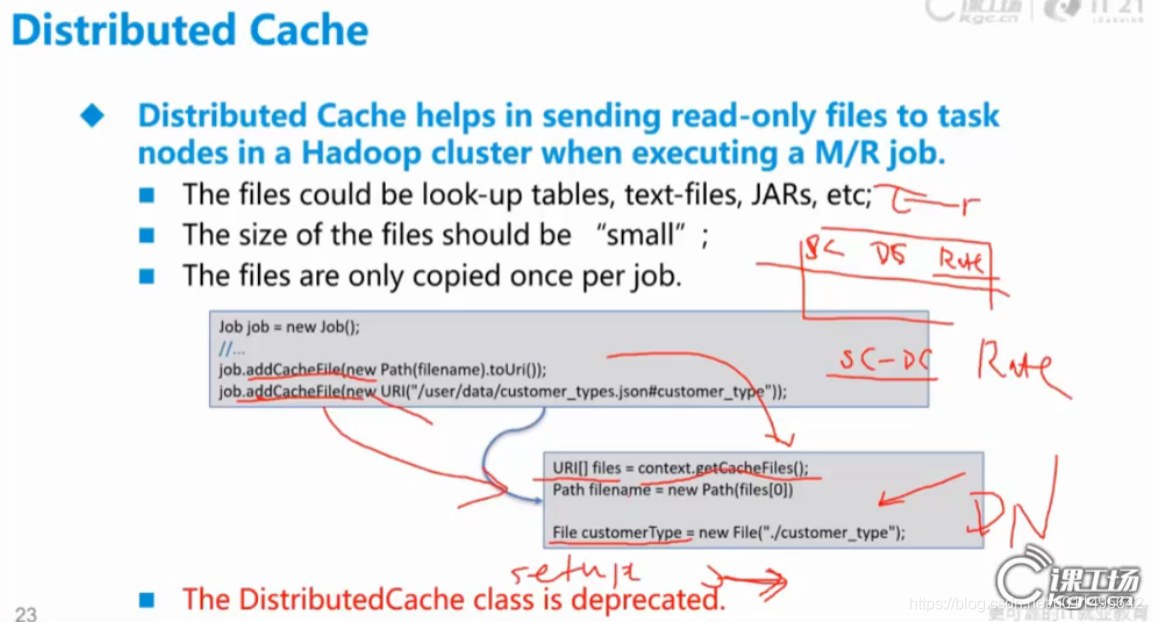
首先介绍Distributed Cache(分布式缓存),主要功能是把DataNode(客户端)一些小的文件送到DataNode上。
1. 通过job.addCacheFile(new Path(filename).toUri)
2.通过job.addCacheFile(new URI("xx/xxx/xxx/xx.json#customer_type"))
通过1和2来传过去(都是URI 就是方便你知道在客户端上这些文件的位置 )
如果知道文件路径的话,new File正好帮你创建一个。
如果不知道文件路径,可以通过context一口气获取所有缓存的文件,放到一个列表里,这样想拿谁都可以。
客户端某个文件的内容会被拿到DataNode,但不会修改这些内容,拿过来默认是和原来的文件一样的名字。#号可以重新起名。
Map-Side Join就是这样,在mapper的setup方法里,把这些小表拿过来
erFile:File = new File("./er.csv")
变成其他格式 比如Hashtable
然后和大表对照做Join

这篇关于MapReduce的Map Size Join以及Distributed Cache的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



