cache专题

Golang基于内存的键值存储缓存库go-cache
《Golang基于内存的键值存储缓存库go-cache》go-cache是一个内存中的key:valuestore/cache库,适用于单机应用程序,本文主要介绍了Golang基于内存的键值存储缓存库... 目录文档安装方法示例1示例2使用注意点优点缺点go-cache 和 Redis 缓存对比1)功能特性

使用Spring Cache时设置缓存键的注意事项详解
《使用SpringCache时设置缓存键的注意事项详解》在现代的Web应用中,缓存是提高系统性能和响应速度的重要手段之一,Spring框架提供了强大的缓存支持,通过@Cacheable、... 目录引言1. 缓存键的基本概念2. 默认缓存键生成器3. 自定义缓存键3.1 使用@Cacheab
![[项目][CMP][Thread Cache]详细讲解](https://i-blog.csdnimg.cn/direct/9b45402cc79244b08d14c60f1767084e.png)
[项目][CMP][Thread Cache]详细讲解
目录 1.设计&结构2.申请内存3.释放内存4.框架 1.设计&结构 Thread Cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表 每个线程都会有一个Thread Cache对象,这样每个线程在这里获取对象和释放对象时是无锁的 TLS – Thread Local Strorage Linux gcc下TLSWindows vs下TLS
![[项目][CMP][Central Cache]详细讲解](https://i-blog.csdnimg.cn/direct/69b6f4cebe024adb8138522b95b1571d.png)
[项目][CMP][Central Cache]详细讲解
目录 1.设计&结构2.申请内存3.释放内存4.框架 1.设计&结构 Central Cache也是一个哈希桶结构,它的哈希桶的映射关系跟Thread Cache是一样的不同的是它的每个哈希桶位置挂的是SpanList链表结构(带头双向循环链表),不过每个映射桶下面的span中的大内存块被按映射关系切成了一个个小内存块对象挂在span的自由链表中 8Byte映射位置下面挂的是

LRU算法 - LRU Cache
这个是比较经典的LRU(Least recently used,最近最少使用)算法,算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。 一般应用在缓存替换策略中。其中的”使用”包括访问get和更新set。 LRU算法 LRU是Least Recently Used 近期最少使用算法。内存管理的一种页面置换算法,对于在内存中但又不用的

Fast Image Cache
https://github.com/path/FastImageCache Fast Image Cache is an efficient, persistent, and—above all—fast way to store and retrieve images in your iOS application. Part of any good iOS applica

Kafka【五】Buffer Cache (缓冲区缓存)、Page Cache (页缓存)和零拷贝技术
【1】Buffer Cache (缓冲区缓存) 在Linux操作系统中,Buffer Cache(缓冲区缓存)是内核用来优化对块设备(如磁盘)读写操作的一种机制(故而有一种说法叫做块缓存)。尽管在较新的Linux内核版本中,Buffer Cache和Page Cache已经被整合在一起,但在理解历史背景和功能时,了解Buffer Cache仍然很有帮助。 Buffer Cache 的历史和定义

Gradle's dependency cache may be corrupt解决方法
问题描述: 1 2 3 4 5 6 7 Error:Unable to find method 'com.google.common.cache.CacheBuilder.build(Lcom/google/common/cache/CacheLoader;)Lcom/google/common/cache/LoadingCache;'. Possible causes for this u

12306项目学习笔记(框架篇cache)
BloomFilterPenetrateProperties @ConfigurationProperties(prefix = BloomFilterPenetrateProperties.PREFIX): 指定这个类的属性会从配置文件中读取,前缀为 framework.cache.redis.bloom-filter.default。 /*** 每个元素的预期插入量*/privat
cache flush和cache invalid区别
“Cache flush”和“Cache invalidation”是两种管理缓存的操作,尽管它们有一些相似之处,但在作用和使用场景上有所不同。 ### Cache Flush - **定义**: Cache flush 是指将整个缓存清空,也就是移除缓存中的所有数据。所有缓存的内容都会被删除,缓存回到一个空的状态。 - **使用场景**: Cache flush 通常在以下情况下使用: -
综述翻译:Machine Learning-Based Cache Replacement Policies: A Survey 2021
摘要: 虽然在提高命中率方便有了广泛进展,设计一个模拟Belady‘s 算法的缓存替换策略依旧很有挑战。现存的标准静态替换策略并不适合动态的内存访问模式,而计算机程序的多样性加剧了这个问题。有几个因素影响缓存策略的设计,如硬件升级,内存开销,内存访问模式,模型延时等。 用机器学习的算法解决缓存替换的问题取得了令人惊讶的结果,并朝着具有成本效应的解决方案发展。在本文中,我们回顾了一些基于机器学习

Linux内存、Swap、Cache、Buffer详细解析
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 来源:r6d.cn/abK6G 1. 通过free命令看Linux内存 total:总内存大小。 used:已经使用的内存大小(这里面包含cached和buffers和shared部分)。 free:空闲的内存大小。 shared:进程间共享内存(一般不会用,可以忽略)。 buffers:

Cache 工作原理,Cache 一致性,你想知道的都在这里
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 可以随便到网上查一查,各大互联网公司笔试面试特别喜欢考一道算法题,即 LRU缓存机制,又顺手查了一下LRU缓存机制最近有哪些企业喜欢考察,超级大热门! 今天给大家分享一篇关于 Cache 的硬核的技术文,基本上关于Cache的所有知识点都可以在这篇文章里看到。 关于 Cache 这方面内容图

WordPress 后台缓存插件:WP Admin Cache提高缓存页面
使用WordPress建站会安装一些静态缓存插件,比如:WP Rocket、Cache Enabler、Comet Cache、W3 Total Cache、WP Super Cache、WP Fastest Cache、Hyper Cache等等,这些都用于缓存前端。 今天介绍一款专门用于缓存后台的插件:WP Admin Cache。 启用后,提速效果还是很明显,比如后台所有文章页面秒开

Volley的cache之硬盘缓存--DiskBasedCache
前言 衡量一个框架的优劣,缓存的处理是很重要的指标。这次我将对Volley的硬盘缓存DiskBasedCache从源码的角度进行解析。 下面先对DiskBasedCache的原理做简要介绍,开个头,然后根据简介做源码分析。 缓存原理 在说缓存原理之前,要说一下缓存的数据怎么来的。 第一步: 当NetWorkDispatcher的run方法开始执行(NetWorkDispatcher是T

书生大模型实战营闯关记录----第十一关:LMDeploy 量化部署进阶实践 KV cache量化部署,W4A16 模型量化和部署
文章目录 1 配置LMDeploy环境1.1 环境搭建1.2 InternStudio环境获取模型1.3 LMDeploy验证启动模型文件 2 LMDeploy与InternLM2.5 2.1 LMDeploy API部署InternLM2.52.1.1 启动API服务器 2.1.2 以命令行形式连接API服务器 2.1.3 以Gradio**网页形式连接API服务器** 2.2 LMDe

【计组 | Cache原理】讲透Cache的所有概念与题型方法
Cache 写在前面:高速缓存Cache一直408中的重点以及绝对的难点,前几天我在复习计组第三章的知识,Cache这一节把我困住了,我发现很多概念我都不记得了,一些综合性强的计算题根本无从下手,我深知Cache对于每个408的初学者来说,都是痛点、难点所在,因此花了一晚上狠狠学习Cache总结做了这个Cache“大观”,尝试用最精简且具有逻辑性的方式,只讲重难点和考点,给大家讲透Cache(我
使用 Flask-Cache 缓存给Flask提速
Django里面可以很方便的应用缓存,那Flask里面没准备这么周全怎么办?自己造轮子么?不用的,前人种树后人乘凉,我们有Flask-Cache,用起来和Django里面一样方便哦! 1.安装 pip install Flask-Cache 2.配置 以我的zhihu项目(源码)为例: 在config.py里面,设置simple缓存类型,也可以用第三方的redis之类的,和Django一
Failed to open zip file. Gradle's dependency cache may be corrupt (this sometimes occurs after a net
修改 gradle-wrapper.properties为文件的,从其他工程复制一份就可以,一样的项目自带的就不可以,复制一份就可以,Mac版android Studio3.1版本 下面这段用第五行的就报错,用第六行就可以。两行代码用肉眼看明明是一样的呀。 把其中任意一行代码执行Ctrl+H查找,确只能找到其中一行。 distributionPath=wrapper/distszipS
pip 清除缓存cache
问题:经常使用pip安装python包,增加缓存,导致电脑空间不足 在使用pip安装Python库时,如果之前已经下载过该库,pip会默认使用缓存来安装库,而不是重新从网络上下载。缓存文件通常存储在用户目录下的缓存文件夹中,具体位置因操作系统和Python版本而异。以下是一些常见的Python版本和操作系统下缓存文件的默认位置: Windows 10:C:\Users\username\App

AS 升级之Gradle's dependency cache may be corrupt问题解决办法
问题: 今天,发现自己的AndroidStudio可以升级2.3了,于是就兴高采烈的将自己的AndroidStudio由2.2—rc1升级到 2.3 了。升级之后本以为终于可以试试了结果让我呆了。出现如下所示的问题: 解决办法: 1、在Windows操作系统中,先删除用户目录下的.gradle文件夹(如下所示)。 2、MAC中应该删除掉Application包下的gradle文件夹,
转载:缓存一致性(Cache Coherency)入门
说明 最近在做Xilinx MPSoC 双核CPU裸跑的工程,遇到了基本的缓存一致性问题,这里转载一篇学习过程中看到的一篇很好的文章,给大家分享下,后面实验成功,会给出工程的具体教程。 传送门
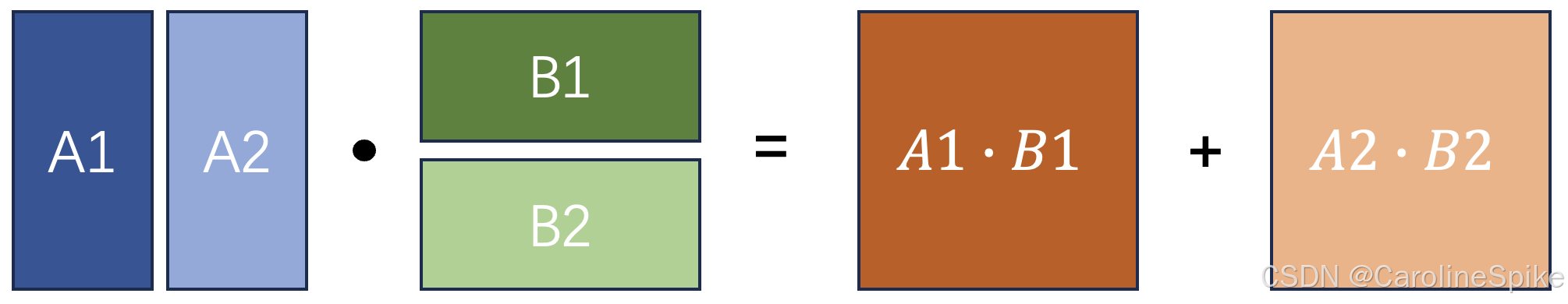
LLM - GPT(Decoder Only) 类模型的 KV Cache 公式与原理 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/141605718 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 在 GPT 类模型中,KV Cache (键值缓存) 是用于优化推理效率的重要技术,基本思想是通过缓存先
LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数 TurboMind理解
参考https://blog.csdn.net/m0_65719612/article/details/138634868 模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0
zdppy+vue3+onlyoffice文档管理系统实战 20240827上课笔记 zdppy_cache框架完善
遗留问题 1、判断是否为管理员2、批量增加 判断是否为管理员 目标: 1、管理员具有特殊权限2、普通用户有自己的专属缓存区域,能够实现物理分割 要解决的问题: 1、客户端需要传递自己的账号密码2、zdppy_cache 需要解析账号密码 怎么传递账号密码? 能明文传递吗? 网页的账号密码也是明文传递的,所以我们也使用明文传递,这是最简单的方式。 放在哪里? 请求头请求体?

达梦数据库的系统视图v$db_object_cache
达梦数据库的系统视图v$db_object_cache 达梦数据库(DM Database)中的 V$DB_OBJECT_CACHE 视图提供了数据库对象缓存的相关信息。这些信息包括缓存中的各种数据库对象(如表、索引、存储过程等)的具体状态和属性。通过 V$DB_OBJECT_CACHE 视图,数据库管理员可以监控数据库对象的缓存情况,从而优化性能并提高系统响应速度。 V$DB_OBJECT_