mapreduce专题

【Hadoop|MapReduce篇】MapReduce概述
1. MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。 2. MapReduce优缺点 2.1 优点 MapReduce易于编程 它简单的实现一些接口,就可以完成一个分布式

MapReduce算法 – 反转排序(Order Inversion)
译者注:在刚开始翻译的时候,我将Order Inversion按照字面意思翻译成“反序”或者“倒序”,但是翻译完整篇文章之后,我感觉到,将Order Inversion翻译成反序模式是不恰当的,根据本文的内容,很显然,Inversion并非是将顺序倒排的意思,而是如同Spring的IOC一样,表明的是一种控制权的反转。Spring将对象的实例化责任从业务代码反转给了框架,而在本文的模式中,在map

圆形缓冲区-MapReduce中的
这篇文章来自一个读者在面试过程中的一个问题,Hadoop在shuffle过程中使用了一个数据结构-环形缓冲区。 环形队列是在实际编程极为有用的数据结构,它是一个首尾相连的FIFO的数据结构,采用数组的线性空间,数据组织简单。能很快知道队列是否满为空。能以很快速度的来存取数据。 因为有简单高效的原因,甚至在硬件都实现了环形队列。 环形队列广泛用于网络数据收发,和不同程序间数据交换(比如内核与应用

【硬刚Hadoop】HADOOP MAPREDUCE(11):Join应用
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 1 Reduce Join Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。 Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在

【硬刚Hadoop】HADOOP MAPREDUCE(10):OutputFormat数据输出
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 1 OutputFormat接口实现类 2 自定义OutputFormat 3 自定义OutputFormat案例实操 1.需求 过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/o

【硬刚Hadoop】HADOOP MAPREDUCE(9):MapReduce内核源码解析(2)ReduceTask工作机制
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 1.ReduceTask工作机制 ReduceTask工作机制,如图4-19所示。 图4-19 ReduceTask工作机制 (1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中

【硬刚Hadoop】HADOOP MAPREDUCE(8):MapReduce内核源码解析(1)MapTask工作机制
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 MapTask工作机制 MapTask工作机制如图4-12所示。 图4-12 MapTask工作机制 (1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。 (2)Map阶段:该节点主要是将解析出

【硬刚Hadoop】HADOOP MAPREDUCE(7):Shuffle机制(3)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 7 Combiner合并 (6)自定义Combiner实现步骤 (a)自定义一个Combiner继承Reducer,重写Reduce方法 public class WordcountCombiner extends Reducer<Text, IntWritable, Text,

【硬刚Hadoop】HADOOP MAPREDUCE(6):Shuffle机制(2)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 4 WritableComparable排序 1.排序的分类 2.自定义排序WritableComparable (1)原理分析 bean对象做为key传输,需要实现WritableComp

【硬刚Hadoop】HADOOP MAPREDUCE(5):Shuffle机制(1)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 1 Shuffle机制 Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图4-14所示。 2 Partition分区
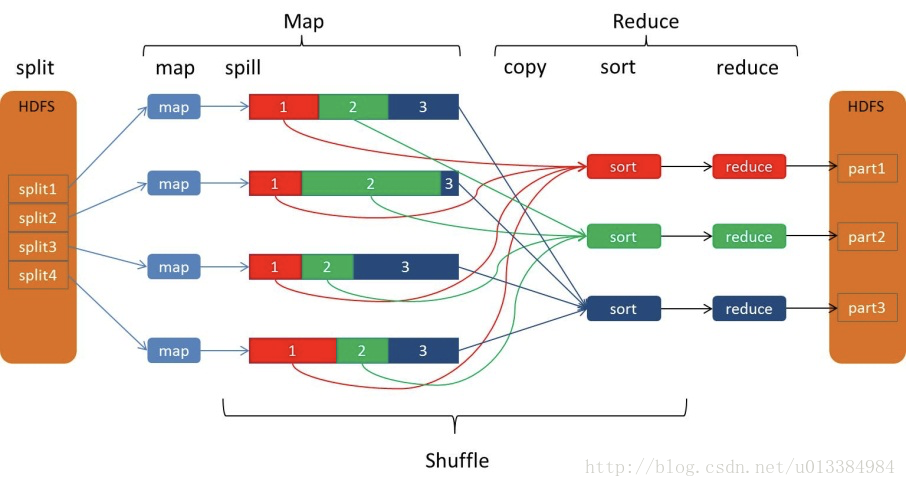
浅谈MapReduce核心之shuffle
Hadoop拥有三大核心组件,HDFS作为底层的分布式文件系统,MapReduce作为计算框架,yarn作为资源调度管理器。 对于开发人员来说,理解MapReduce是很重要的。 在WordCount程序中,map生成的结果是一个个的元组,类似于(hello,1),非常非常多的元组,由context写入到hdfs中,而后续的Reduce阶段,实际上reduce方法接收的参数类似于这种,(hel

MapReduce的shuffle过程详解(分片、分区、合并、归并)
shuffle过程 shuffle概念 shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前
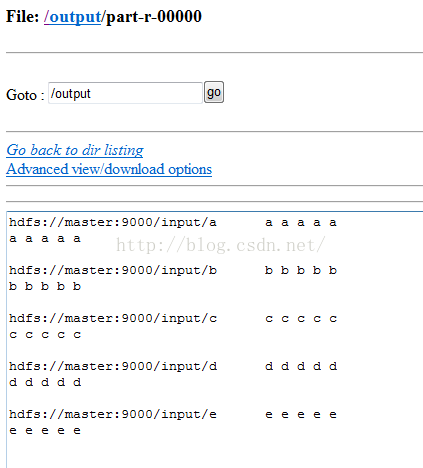
mapreduce将若干小文件合成大文件
1、思路: http://blog.yfteach.com/?p=815,注意原文中有一个错误,就是FileInputformat中并没有找到createRecordReader这个方法,应该在TextInputFormat中有,而不是textFileInputFormat 2、编码: 第一步:编写将整个文件作为一条记录处理的类,即实现FileInputFormat. 注意:F
MapReduce(五):表关联
给出: Tom Lucy Tom Jack Jone Lucy Jone Jack Lucy Mary Lucy Ben Jack Alice Jack Jesse 输出: Tom Alice Tom Jesse Jone Alice Jone Jesse Tom Mary To

MapReduce V2---Yarn的架构及其执行原理
1. MRv1的局限性 1):扩展性差 MRv1中,Jobracker同事兼备了资源管理和作业控制(job的生命周期管理(task调度,跟踪task过程状态,task处理容错)两个功能。 单个的jobtracker无论在内存还是其他资源方面总存在瓶颈,在伸缩性、资源利用率、运行除mapreduce的其他任务等方面都会有限制。 MRv2 Y

MapReduce大致执行过程
大致过程: 将要执行的MapReduce程序复制到Master和每一台Worker机器中Master决定Map程序与Reduce程序分别由哪些Worker机器执行将所有的文件分块,分配到执行Map程序的Worker机器中进行Map将Map后的结果存入Worker机器的本地磁盘执行Reduce程序的Worker机器远端读取每一份Map结果,进行调整排序,同时执行Reduce程序将使用者需要的运算

hadoop实战(五)MAPREDUCE操作
一、基础概念 Maapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架; Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上; (一)、为什么使用MAPREDUCE 1、海量数据在单机上处理因为硬件资源限制,无法胜任 2、一旦将单机版程序扩展到集

大数据修炼之hadoop--MapReduce
文章目录 定义概念流程支持的数据类型demo切片策略FileInputFormat 片与块的关系提交流程关键设置Job提交流程阶段总结准备提交 定义 MapReduce最早是由谷歌公司研究提出的一种面向大规模数据处理的并行计算模型和方法。 特点: MapReduce是一个基于集群的高性能并行计算平台。 MapReduce是一个并行计算与运行软件框架。 MapReduce是一个并

Google的MapReduce和Hadoop的MapReduce基本原理
Google的MapReduce和Hadoop的MapReduce基本原理 MapReduce框架的执行过程可以概述为以下几个关键步骤: 输入分割:用户程序中的MapReduce库首先将输入文件分割成M个片段,每个片段通常大小在16MB到64MB之间,用户可以通过可选参数控制。 启动作业:程序在集群的多台机器上启动多个副本,其中一个机器作为master,其余作为worker。 任务分配
MapReduce学习(一)、(二)
MapReduce:分布式并行编程框架 (一)概述 1.与传统并行计算框架的对比 传统的并行计算框架(如MPI)采用共享式架构(共享内存&存储、采用存储区域网络SAN)、容错性较差;使用的刀片服务器价格高、集群扩展性差(只能从提高机器性能上进行纵向扩展)。它适用于要求实时性、细粒度计算和计算密集型的场景。 MapReduce采用非共享式架构,容错性好;并且它所用的服务器均为普通PC机(价
【Tools】什么是MapReduce
我们从不正视那个问题 那一些是非题 总让人伤透脑筋 我会期待 爱盛开那一个黎明 一定会有美丽的爱情 🎵 范玮琪《是非题》 MapReduce是一种用于处理和生成大规模数据集的编程模型和算法,它由Google公司提出并广泛应用于分布式计算领域。该模型将计算过程分解为两个阶段:Map阶段和Reduce阶段。 在Map阶段,数据集被划分为多个小片段

大数据-数仓-数仓工具:Hive(离线数据分析框架)【替代MapReduce编程;插入、查询、分析HDFS中的大规模数据;机制是将HiveSQL转化成MR程序;不支持修改、删除操作;执行延迟较高】
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。 Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。 Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单

大数据-Hadoop-MapReduce(二):MapReduce编程案例
案例:使用MapReduce进行词频统计 1、读取本地数据,使用本地(Windows中的hadoop)计算资源,计算结果保存到本地 WCMapper.java package com.wyr.wordcount;import java.io.IOException;import java.util.List;import org.apache.hadoop.io.IntWritab

查看mapreduce log日志,查找错误
查看任务报告: 命令:yarn application -status application_1539198654522_1073695 查看mapreduce log日志: 命令:yarn logs -applicationId application_1539198654522_1073695 > log.txt 查看日志也可以通过客户端: 运行过程中会出现这样的记录: the url t

第10节:MapReduce案例分析,MapReduce、自定义分区、MapReduce小文件优化
第10节:MapReduce案例分析,MapReduce、自定义分区、MapReduce小文件优化 MapReduce框架原理3.1 MapReduce工作流程3.2 InputFormat数据输入3.2.1 Job提交流程和切片源码详解3.2.2 FileInputFormat切片机制3.2.3 CombineTextInputFormat切片机制 MapReduce框架原理

第9节:MapReduce分布式编程模型,MapReduce的优缺点、MapReduce的核心思想、MapReduce编程规范、hadoop序列化、workcount编写和myjar集群运行
第9节:MapReduce分布式编程模型,MapReduce的优缺点、MapReduce的核心思想、MapReduce编程规范、hadoop序列化、workcount编写和myjar集群运行 MapReduce入门1.1 MapReduce定义1.2 MapReduce优缺点1.2.1 优点1.2.2 缺点1.3 MapReduce核心思想1.4 MapReduce进程1.5 MapRedu