本文主要是介绍mapreduce将若干小文件合成大文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、思路:
http://blog.yfteach.com/?p=815,注意原文中有一个错误,就是FileInputformat中并没有找到createRecordReader这个方法,应该在TextInputFormat中有,而不是textFileInputFormat
2、编码:
第一步:编写将整个文件作为一条记录处理的类,即实现FileInputFormat.
注意:FileInputFormat本身有很多子类,也实现了很多不同的输入格式,如下
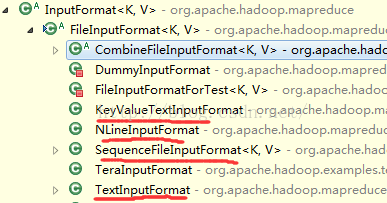
特别注意:KeyValueTextInputFormat这个是以一行的<key,value>形式作为输入的,默认分隔符是Tab键,比如可以使用KeyValueTextInputFormat对WordCount程序进行修改
package com.SmallFilesToSequenceFileConverter.hadoop;import java.io.IOException;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;//将整个文件作为一条记录处理
public class WholeFileInputFormat extends FileInputFormat<NullWritable,Text>{//表示文件不可分@Overrideprotected boolean isSplitable(JobContext context, Path filename) {return false;}@Overridepublic RecordReader<NullWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException,InterruptedException {WholeRecordReader reader=new WholeRecordReader();reader.initialize(split, context);return reader;}}第二步:实现RecordReader,为自定义的InputFormat服务
package com.SmallFilesToSequenceFileConverter.hadoop;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;//实现RecordReader,为自定义的InputFormat服务
public class WholeRecordReader extends RecordReader<NullWritable,Text>{private FileSplit fileSplit;private Configuration conf;private Text value=new Text();private boolean processed=false;//表示记录是否被处理过@Overridepublic NullWritable getCurrentKey() throws IOException,InterruptedException {return NullWritable.get();}@Overridepublic Text getCurrentValue() throws IOException,InterruptedException {return value;}@Overridepublic float getProgress() throws IOException, InterruptedException {return processed? 1.0f : 0.0f;}@Overridepublic void initialize(InputSplit split, TaskAttemptContext context)throws IOException, InterruptedException {this.fileSplit=(FileSplit)split;this.conf=context.getConfiguration();}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if(!processed){byte[]contents=new byte[(int)fileSplit.getLength()];Path file=fileSplit.getPath();FileSystem fs=file.getFileSystem(conf);FSDataInputStream in=null;try{in=fs.open(file);IOUtils.readFully(in, contents, 0, contents.length);value.set(contents,0,contents.length);}finally{IOUtils.closeStream(in);}processed=true;return true;}return false;}@Overridepublic void close() throws IOException {// TODO Auto-generated method stub}}
第三步:编写主类
package com.SmallFilesToSequenceFileConverter.hadoop;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class SmallFilesToSequenceFileConverter{private static class SequenceFileMapper extends Mapper<NullWritable,Text,Text,Text>{private Text filenameKey;//setup在task之前调用,用来初始化filenamekey@Overrideprotected void setup(Context context)throws IOException, InterruptedException {InputSplit split=context.getInputSplit();Path path=((FileSplit)split).getPath();filenameKey=new Text(path.toString());}@Overrideprotected void map(NullWritable key,Text value,Context context)throws IOException, InterruptedException {context.write(filenameKey, value);}}public static void main(String[] args) throws Exception {Configuration conf=new Configuration();Job job=Job.getInstance(conf,"SmallFilesToSequenceFileConverter");job.setJarByClass(SmallFilesToSequenceFileConverter.class);job.setInputFormatClass(WholeFileInputFormat.class);//job.setOutputFormatClass(TextOutputFormat.class);job.setMapperClass(SequenceFileMapper.class);//设置最终的输出job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job,new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0:1);}
}3、测试
原始文件:在input目录下有a、b、c、d、e五个文件,
a文件的数据是:a a a a a
a a a a a
其他同理,
得到最终的结果如下:
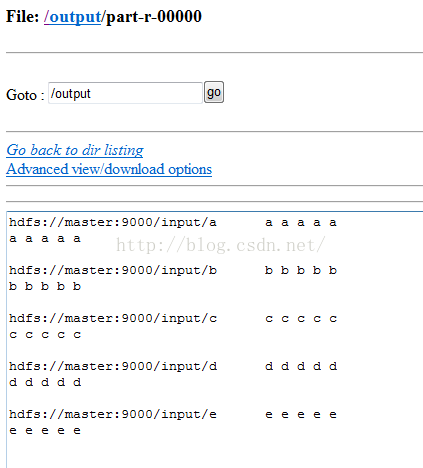
可以看到文件名和数据为一行存在同一个文件当中!
这篇关于mapreduce将若干小文件合成大文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!