合成专题

Java实战之自助进行多张图片合成拼接
《Java实战之自助进行多张图片合成拼接》在当今数字化时代,图像处理技术在各个领域都发挥着至关重要的作用,本文为大家详细介绍了如何使用Java实现多张图片合成拼接,需要的可以了解下... 目录前言一、图片合成需求描述二、图片合成设计与实现1、编程语言2、基础数据准备3、图片合成流程4、图片合成实现三、总结前
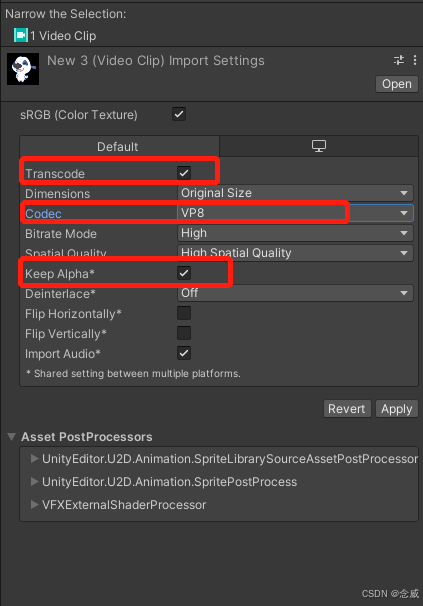
unity导入半透明webm + AE合成半透明视频
有些webm的文件导入unity后无法正常播报,踩坑好久才知道需要webm中的:VP8 标准 现在手上有几条mp4双通道的视频,当然unity中有插件是可以支持这种视频的,为了省事和代码洁癖,毅然决然要webm走到黑。 mp4导入AE合成半透明 打开 AE 软件,创建一个新的合成项目。在项目面板中,选择 “导入” 或直接将 MP4 视频文件拖放到项目面板中,导入视频素材。项目面板中,右击

三文带你轻松上手鸿蒙的AI语音03-文本合成声音
三文带你轻松上手鸿蒙的AI语音03-文本合成声音 前言 接上文 三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 HarmonyOS NEXT 提供的AI 文本合并语音功能,可以将一段不超过10000字符的文本合成为语音并进行播报。 场景举例 手机在无网状态下,系统应用无障碍(屏幕朗读)接入文本转语音能力,为视障人士提供播报能力。类似微信读书,可以实现将文章内容通过语音朗读,可以

多行命令提示符中的命令合成一行
C:\Windows\System32\cmd & cd C:\Siemens\Teamcenter12\tc_menu & C:\Siemens\Teamcenter12\tc_menu\tcdb_config1.bat & C:\Users\Administrator\Desktop\ITK\TEST1\x64\Debug\TEST1.exe 用&分割 C:\Windows\System3

震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集
震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集 Abstract 由于摄像机视角多变和场景条件不可预测,在动态路边场景中从单目图像中准确检测三维物体仍然是一个具有挑战性的问题。本文介绍了一种两阶段的训练策略来应对这些挑战。我们的方法首先在大规模合成数据集RoadSense3D上训练模型,该数据集提供了多样化的场景以实现稳健的特征学习。随后,
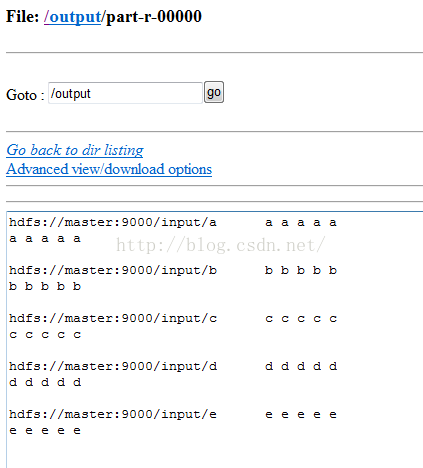
mapreduce将若干小文件合成大文件
1、思路: http://blog.yfteach.com/?p=815,注意原文中有一个错误,就是FileInputformat中并没有找到createRecordReader这个方法,应该在TextInputFormat中有,而不是textFileInputFormat 2、编码: 第一步:编写将整个文件作为一条记录处理的类,即实现FileInputFormat. 注意:F

cximage mix 注意图像合成时内部坐标
double h1,w1,h2,w2,h3,w3,h4,w4,bpp; //getheight(w4,h4); CString spath1 = _T("测试1"); CString spath2 = _T("测试2"); CString spath3 = _T("测试3"); CStringArray arraystr; arraystr.Add(
2024-09-01 - 通用人工智能技术 - AI 数字人直播 - 合成篇 - 流雨声
摘要 2024-09-01 周日 杭州 风和日丽 小记: 这周以政府采购评审专家的身份参加了采购评审,前几天摔伤的地方也逐渐愈合了,不过现在的我多少还是有点叛逆的,天天洗澡,等伤好了一定要去泡温泉。 应用实践 1 项目获取 git clone https://github.com/ai-liuys/DH_live.git 2 安装依赖 # windows 研发测试,需要安装 ffm
react虚拟事件(合成事件)与dom原生事件的混用
react合成事件 如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统差异,实现了一个中间层——SyntheticEvent。 原理 React中,如果需要绑定事件,我们常常在jsx中这么写: <div onClick={this.onClick}>react事件</div> 原理


ChatTTS 长音频合成和本地部署2种方式,让你的“儿童绘本”发声的实战教程(文末有福利)
接上文(GLM-4-Flash 大模型 API 免费了,手把手构建“儿童绘本”应用实战(附源码)),老牛同学通过 GLM-4-Flash 文生文和 CogView-3 文生图大模型,和大家一起编写了一个图文并茂的儿童绘本应用,并且以《黑神话·悟空》当前热门游戏为背景,做了一本名为《悟空探秘之旅》的儿童小绘本。 绘本我们是做好了,可是还得我们读给小朋友们听,老牛同学懒虫又犯了:能不能把绘本转换成音

解读GaussianTalker:利用音频驱动的基于3D高斯点染技术的实时高保真讲话头像合成
单位:首尔大学 项目地址:https://ku-cvlab.github.io/GaussianTalker/ github:https://github.com/KU-CVLAB/gaussiantalker 本文是对GaussianTalker的解读,欢迎大家阅读指正! 目录 前言摘要一、背景介绍二 相关工作三 3DGS四 方法4.1 问题阐述和概述4.3 学习音频驱动的3D高斯
多个sql文件合成一份
文章目录 前言一、合并sql二、使用步骤1.windows2.linux 总结 前言 导入.sql文件的时候,当然是越少约好了 不过由于代码生成,或者其他原因,有时候会有多分sql文件,此时给导入数据库的工作,增加了很多重复性的工作,如何解决呢? 一、合并sql 可以通过命令将多个文件,合并成一个.sql文件,这样就方便多了 二、使用步骤 1.windows
python使用ffmpeg将视频、音频合并合成(速度最快)
一、ffmpeg安装 ffmpeg下载安装教程及介绍 基本方法:ffmpeg视频音频合成命令 ffmpeg -y -i video.mp4 -i audio.m4a -c:v copy -c:a copy -strict experimental -shortest output.mp4 二、合成代码 import subprocessvideo_path = r"D:\Vide

有界注意力:增强文本到图像合成中的控制
人工智能咨询培训老师叶梓 转载标明出处 传统的文本到图像扩散模型虽然能够生成多样化和高质量的图像,但在处理包含多个主题的复杂输入提示时,往往难以准确捕捉预期的语义。特别是当这些主题在语义上或视觉上相似时,模型生成的图像常常出现语义不准确的问题,如主题特征混合、属性绑定错误或主题被忽略等。为了解决上述问题,特拉维夫大学与 Snap 研究团队共同提出了一种名为“Bounded Attention”(

AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务
AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务。 AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱 Toucan TTS是由德国斯图加特大学自然语言处理研究所(MS)精心打造的文本转语音(TTS)工具箱,它支持超过7000种语言,包括多样的方言和语言变体。这款工具箱建立在P
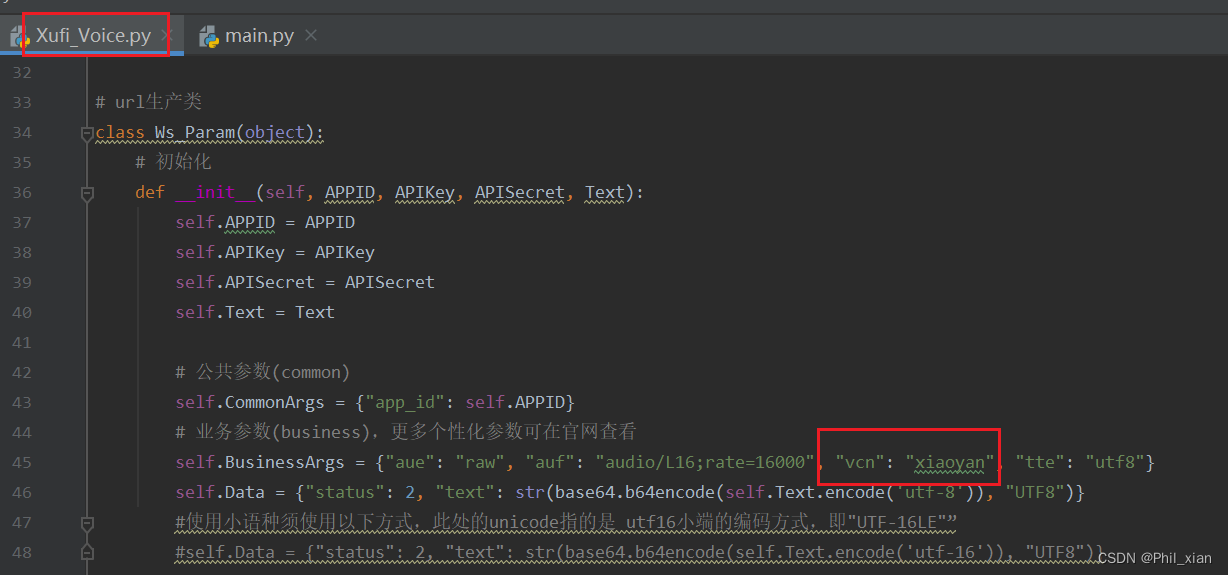
关于文章“python+百度语音识别+星火大模型+讯飞语音合成的语音助手”报错的修改
前言 关于我的文章:python+百度语音识别+星火大模型+讯飞语音合成的语音助手,运行不起来的问题 文章地址: https://blog.csdn.net/Phillip_xian/article/details/138195725?spm=1001.2014.3001.5501 1.报错问题 如果运行中报错,且报错位置在Xufi_Voice.py文件中的pcm_2_wav,如下图所示

AIGC-Animate Anyone阿里的图像到视频 角色合成的框架-论文解读
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation 论文:https://arxiv.org/pdf/2311.17117 网页:https://humanaigc.github.io/animate-anyone/ MOTIVATION 角色动画的
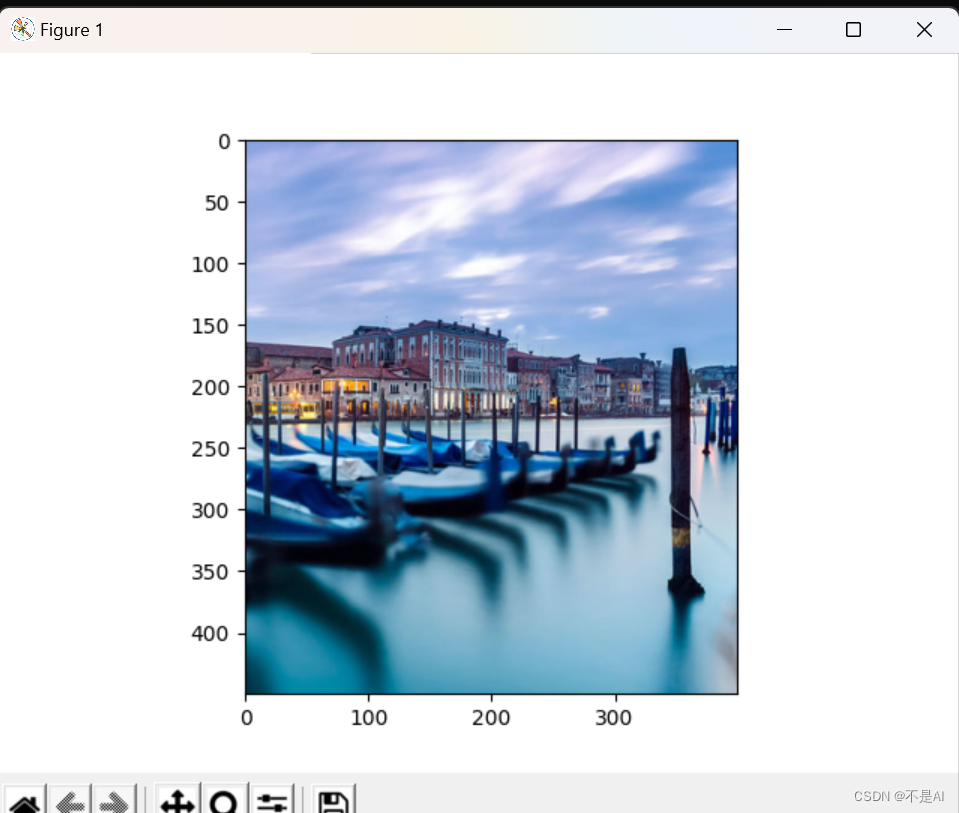
【PyTorch】【机器学习】图片张量、通道分解合成和裁剪
一、导入所需库 from PIL import Imageimport torchimport numpy as npimport matplotlib.pyplot as plt 二、读取图片 pic = np.array(Image.open('venice-boat.jpg')) 上述代码解释:先用Image.open()方法读取jpg格式图片,再用np.array()方法
超拟人合成接口使用指南(讯飞)
简介 超拟人合成接口是一种先进的文本转音频技术,通过利用大模型生成拟声词,使合成音频更加拟人化和真实。本文将对该接口的主要功能、请求和响应格式、常见错误码等进行总结归纳,帮助用户快速上手并正确使用该接口。 接口描述 超拟人合成接口支持将文本数据合成为音频,音频结果(audio)以多帧形式返回。由于结果帧的顺序可能无法保证,建议在接入方在一定时间片内根据服务响应
手把手教程 | 云端部署语音合成神器——ChatTTS
近期,ChatTTS 凭借其高度仿真的 AI 语音合成技术迅速走红!ChatTTS 是专为对话场景设计的文本转语音模型,例如 LLM 助手对话任务,支持中英文两种语言。其最大的模型在超过 10 万小时的中英文数据上进行训练,确保了高质量的语音输出。 从宣传视频中可以发现,合成语音自动添加了“嗯……”“然后”等语气词,以及适时的笑声,展现了丰富的韵律和情感,几乎无法分辨真假。 本文将手把
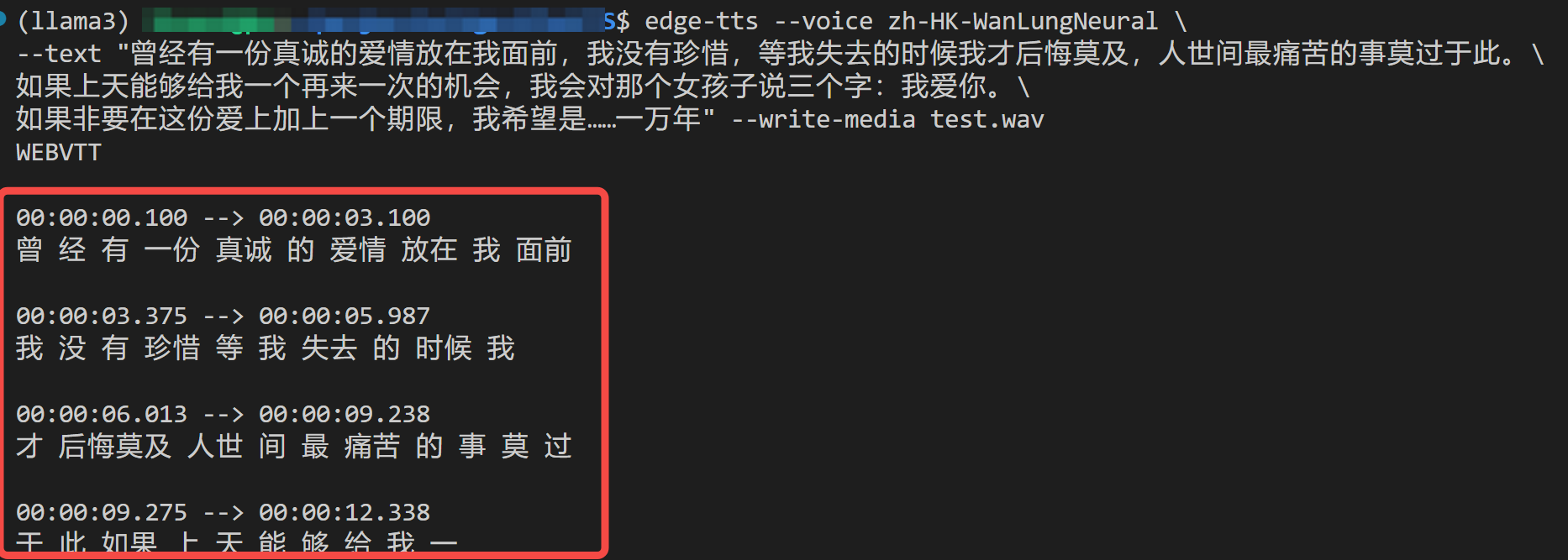
开源的语音合成项目-EdgeTTS,无需部署无需Key
前几天和大家分享了:全网爆火的AI语音合成工具-ChatTTS。 有很多小伙伴反应模型下载还有点麻烦~ 今天再给大家带来一款开源的语音合成 TTS 项目-EdgeTTS,相比ChatTTS,操作起来对小白更友好。 因为其底层是使用微软 Edge 的在线语音合成服务,所以不需要下载任何模型,甚至连 api_key 都给你省了,简直不要太良心~ 关键是,除了支持普通话外,还支持很多地方口音(比
FFmpeg AAC文件和H264文件合成MP4/FLV文件
使用FFmpeg库把AAC文件和H264文件合成MP4/FLV文件,FFmpeg版本为4.4.2-0。 需要aac和h264测试文件的,可以从我上传的MP4文件中用ffmpeg提取,命令如下: ffmpeg -i <input.mp4> -map 0:v -c:v copy <output.h264> -map 0:a -c:a copy <output.aac> 代码如下: #i

canvas 图像合成
globalAlpha globalAlpha 属性设置或返回绘图的当前透明值(alpha 或 transparency)。 globalAlpha 属性值必须是介于 0.0(完全透明) 与 1.0(不透明) 之间的数字。 语法:context.globalAlpha=number; number介于0到1之间,0 完全透明,1 不透明 globalCompositeOperati
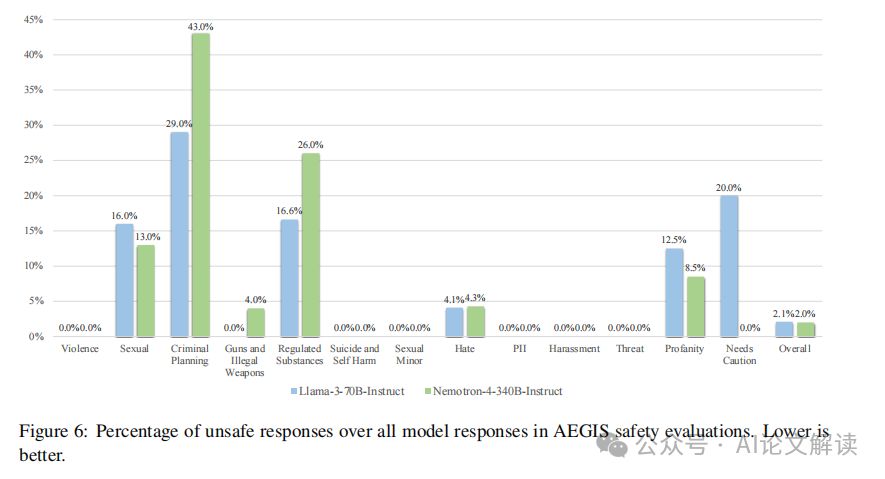
NVIDIA新模型Nemotron-4:98%的训练数据是合成生成的,你敢信?
获取本文论文原文PDF,请公众号 AI论文解读 留言:论文解读 标题:Nemotron-4 340B Technical Report 模型概述:Nemotron-4 340B系列模型的基本构成 Nemotron-4 340B系列模型包括三个主要版本:Nemotron-4-340B-Base、Nemotron-4-340B-Instruct和Nemotron