本文主要是介绍AIGC-Animate Anyone阿里的图像到视频 角色合成的框架-论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
论文:https://arxiv.org/pdf/2311.17117
网页:https://humanaigc.github.io/animate-anyone/

MOTIVATION
- 角色动画的目标是将静态图像转换成逼真的视频,这在在线零售、娱乐视频、艺术创作和虚拟角色等领域有广泛应用。
- 尽管生成对抗网络(GANs)和图像动画技术取得了进展,但生成的图像或视频仍存在局部失真、细节模糊、语义不一致和时间不稳定等问题。
- 目前的研究主要集中在特定任务和基准上,导致泛化能力有限。
CONTRIBUTION
- 提出Animate Anyone,一种新技术,能够将静态角色图像转换成由特定姿势序列控制的动画视频。网络设计和预训练权重继承自Stable Diffusion (SD),并对去噪UNet进行修改以处理多帧输入。
- ReferenceNet: 特别设计为对称的UNet结构,用于捕获参考图像的空间细节。通过空间注意力机制在UNet的相应层中整合ReferenceNet的特征,使模型能够在一致的特征空间内学习与参考图像的关系,显著提升外观细节的保持能力。
- 姿态引导器(Pose Guider): 一个轻量级的姿势引导器,有效将姿势控制信号整合到去噪过程中,确保动画的可控性。
- Temporal Layer:引入时间层来模拟多帧之间的关系,保持视觉质量的高分辨率细节,同时模拟连续且平滑的时间运动过程。
RELATED WORKS
扩散模型在视频生成中的应用
- 文本到视频模型:扩散模型在文本到图像应用中的成功,为文本到视频的研究提供了结构上的启示。
- 时间层插入:一些工作通过在预训练的文本到图像模型中插入时间层,将其转换为视频生成器。
- Video LDM和AnimateDiff:提出了在大量视频数据上训练的运动模块,这些模块可以注入到大多数个性化的文本到图像模型中,而无需特定调整。
- VideoComposer和VideoCrafter:扩展了文本到视频的功能到图像到视频,通过在训练期间将图像作为条件控制纳入扩散输入,或将CLIP的文本和视觉特征作为交叉注意力的输入。
扩散模型在人物图像动画中的应用
- PIDM、LFDM和LEO:提出了将期望的纹理模式注入去噪的人物姿势转移、在潜在空间合成光流序列以及表示运动为流图序列并使用扩散模型合成运动代码的方法。
- DreamPose和DisCo:利用预训练的稳定扩散模型,并提出适配器来模拟CLIP和VAE图像嵌入,或从ControlNet中汲取灵感,分离姿势和背景的控制。
METHODS
目标是角色动画的姿势引导图像到视频合成。 给定描述角色外观和姿势序列的参考图像,我们的模型会生成该角色的动画视频。
Preliminariy: Stable Diffusion
Stable Diffusion(SD)是一种基于潜在扩散模型(LDM)的图像生成方法。为了降低模型的计算复杂性,SD在潜在空间中对特征分布进行建模。其核心组件包括一个自动编码器(Autoencoder),由编码器(Encoder) E E E和解码器(Decoder) D D D组成。具体过程如下:
- 编码过程:给定图像 x x x,编码器首先将其映射到一个潜在表示 z = E ( x ) z = E(x) z=E(x)。
- 解码过程:解码器将潜在表示 z z z重建为原图像 x recon = D ( z ) x_{\text{recon}} = D(z) xrecon=D(z)。
SD通过denoise一个正态分布的噪声 ϵ \epsilon ϵ来生成逼真的潜在表示 z z z。在训练过程中,图像潜在表示 z z z在 t t t个时间步中被扩散以产生噪声潜在表示 z t z_t zt,去噪UNet被训练用来预测应用的噪声。其优化目标定义如下:
L = E z t , c , ϵ , t ( ∣ ∣ ϵ − ϵ θ ( z t , c , t ) ∣ ∣ 2 2 ) L = E_{z_t, c, \epsilon, t} (||\epsilon - \epsilon_\theta(z_t, c, t)||_2^2) L=Ezt,c,ϵ,t(∣∣ϵ−ϵθ(zt,c,t)∣∣22)
- ϵ θ \epsilon_\theta ϵθ表示去噪UNet的函数
- c c c表示条件信息的嵌入。在原始SD中,使用CLIP ViT-L/14[9]文本编码器将文本提示表示为文本嵌入。
- 去噪UNet包括四个下采样层、一个中间层和四个上采样层,每个层内的典型块包括三种计算:2D卷积、自注意力和交叉注意力。
- 在推理时, z T z_T zT从初始时间步 T T T的随机高斯分布中采样,并通过确定性采样过程逐步去噪和恢复为 z 0 z_0 z0,最终由解码器 D D D重建为生成的图像。
网络架构
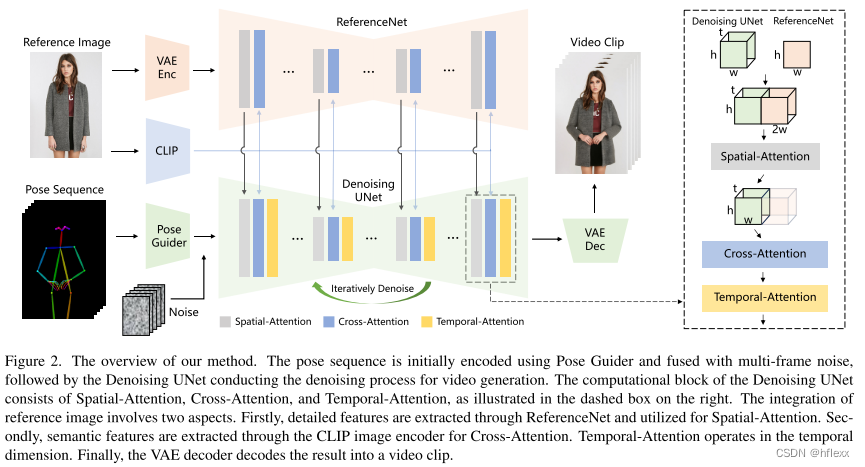
论文的网络架构主要包括三个关键组件:ReferenceNet、姿态引导器(Pose Guider)和时间层(Temporal Layer)。
总览:
- 网络输入:多帧噪声。
- 去噪UNet:基于SD设计,采用相同的框架和块单元,并继承SD的训练权重。
- 关键组件:
- ReferenceNet:编码角色外观特征。
- Pose Guider:编码运动控制信号(motion control signals),实现可控的角色运动。
- 时间层(Temporal layer):编码时间关系,确保角色运动的连续性。
ReferenceNet:
- 设计:采用与去噪UNet相同的架构(但不包括时间层),继承原始SD的权重,进行独立权重更新。
- 特征融合:在去噪UNet的自注意力层中替换为空间注意力层。给定来自去噪UNet的特征图 x 1 ∈ R t × h × w × c x_1 \in \mathbb{R}^{t \times h \times w \times c} x1∈Rt×h×w×c和来自ReferenceNet的特征图 x 2 ∈ R h × w × c x_2 \in \mathbb{R}^{h \times w \times c} x2∈Rh×w×c,首先复制 x 2 x_2 x2,然后在 w w w维度上与 x 1 x_1 x1连接,执行自注意力,并提取前半部分特征图作为输出。这种设计的优势:
- ReferenceNet可以利用预训练的图像特征建模能力,结果初始化良好。
- 由于ReferenceNet和去噪UNet具有相同的网络结构和共享的初始化权重,去噪UNet可以选择性地从ReferenceNet中学习相关特征。
- 基于扩散的视频生成中,所有视频帧都经过多次去噪,而ReferenceNet在整个过程中只需要提取一次特征。 因此,在推理过程中,不会导致计算开销的大幅增加。
姿态引导器(Pose Guider):
- 设计:采用四层卷积层(4×4卷积核,2×2步幅,通道数分别为16、32、64、128),将姿态图像与噪声潜在空间对齐。处理后的姿态图像与噪声潜在空间相加,然后输入去噪UNet。
- Pose Guider用高斯权重初始化,最终投影层使用零卷积。
时间层(Temporal Layer):
在Res-Trans块中的空间注意力和交叉注意力之后插入时间层。首先重塑特征图,然后沿时间维度执行自注意力操作。通过残差连接将时间层的特征整合到原始特征中。
- 位置:时间层集成在Res-Trans块内的空间注意力(spatial-attention)和交叉注意力(cross-attention)组件之后。这种设计灵感来源于AnimateDiff模型。
- 特征图重塑:假设输入特征图为 x ∈ R b × t × h × w × c x \in \mathbb{R}^{b \times t \times h \times w \times c} x∈Rb×t×h×w×c,其中 b b b表示批量大小, t t t表示时间步长, h h h和 w w w表示特征图的高度和宽度, c c c表示通道数。首先将特征图重塑为 x ∈ R ( b × h × w ) × t × c x \in \mathbb{R}^{(b \times h \times w) \times t \times c} x∈R(b×h×w)×t×c,然后沿着时间维度 t t t进行自注意力操作(即时间注意力)。
- 时间注意力:时间注意力指的是沿时间维度 t t t进行自注意力计算。这种方式允许模型在处理每一帧时,考虑前后帧的信息,从而捕捉帧与帧之间的时间依赖关系。
- 应用范围:时间层专门应用于去噪 UNet 的 Res-Trans 块内。 对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。
训练策略
训练过程分为两个阶段:
- 第一阶段:
- 训练内容:在这一阶段,模型使用单个视频帧进行训练,不包括时间层。
- 模型输入:模型输入为单帧噪声。
- 组件训练:在这一阶段同时训练ReferenceNet和Pose Guider。
- 参考图像选择:从整个视频片段中随机选择参考图像。
- 权重初始化:
- 去噪UNet和ReferenceNet的模型权重基于Stable Diffusion(SD)的预训练权重进行初始化。
- Pose Guider使用高斯权重初始化,最终的投影层使用零卷积。
- VAE的编码器和解码器的权重,以及CLIP图像编码器的权重在训练过程中保持固定。
- 优化目标:使模型能够在给定的参考图像和目标姿势条件下生成高质量的动画图像。
- 第二阶段:
- 时间层引入:将时间层加入到之前训练好的模型中。
- 权重初始化:使用AnimateDiff的预训练权重来初始化时间层。
- 模型输入:模型输入变为24帧的视频片段。
- 权重固定:在这一阶段,只训练时间层,而保持网络其余部分的权重不变。
- 训练目的:通过训练时间层,增强模型在视频帧之间的时间连贯性,进一步提升生成动画的质量。
EXPERIMENT
为了证明方法在动画化各种角色中的适用性,从互联网上收集了 5K 角色视频剪辑(2-10 秒长)来训练模型。 我们使用DWPose提取视频中角色的姿势序列,包括身体和手,将其渲染为OpenPose[5]的姿势骨架图像。 实验在 4 个 NVIDIA A100 GPU 上进行
-
第一阶段训练:
- 数据处理:从视频中采样单帧,调整大小并中心裁剪到768×768分辨率。
- 训练步骤:训练30000步,每批次大小为64。
- 学习率:设置为1e-5。
-
第二阶段训练:
- 数据处理:使用24帧视频序列进行训练。
- 训练步骤:训练10000步,每批次大小为4。
- 学习率:设置为1e-5。
推理过程中,重新·调整驱动姿势骨架的长度以接近参考图像中角色的骨架长度,并使用DDIM采样器进行20步去噪。采用EDGE中的时间聚合方法(temporal aggregation),将不同批次的结果连接起来生成长视频。
实验结果表明:Animate anyone可以对任意角色进行动画处理,包括全身人物、半身肖像、卡通人物和人形人物。能够生成高清和逼真的角色细节。即使在实质性运动下,它也能保持与参考图像的时间一致性,并在帧之间表现出时间连续性。

为了展示animate anyone的优越性,在三个特定基准(UBC时尚视频数据集、TikTok数据集和Ted-talk数据集)上评估了其性能,并进行了与其他方法的对比实验。
-
时尚视频合成:
- 定量对比:在UBC时尚视频数据集上的定量对比结果如表1所示,我们的方法在视频指标上表现尤为突出。

- 定性对比:图4展示了与其他方法的定性对比,其他方法在保持衣物细节一致性方面表现不佳,而animate anyone能够有效保持衣物细节的一致性。

- 定量对比:在UBC时尚视频数据集上的定量对比结果如表1所示,我们的方法在视频指标上表现尤为突出。
-
人类舞蹈生成:
-
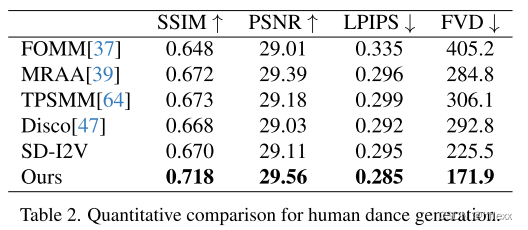
定量对比:在TikTok数据集上的定量对比结果如表2所示,animate anyone的方法取得了最佳结果。
-
定性对比:图5展示了与DisCo方法的定性对比,在复杂的舞蹈序列中,animate anyone的方法在保持视觉连续性和处理多样化角色外观方面表现更好。

-
-
讲话手势生成:
-
定量对比:在Ted-talk数据集上的定量对比结果如表3所示,animate anyone显著优于DisCo和SD-I2V。图6展示了与MRAA和TPSMM方法的定性对比,animate anyone能够生成更加准确和清晰的结果。

局限性
-
手部运动的稳定性:模型可能难以为手部运动生成稳定的结果,有时可能会导致图像扭曲和运动模糊。手部的细节和复杂性可能对模型的预测和生成提出了更高的要求。
-
视角问题:由于图像仅从一个角度提供信息,生成角色运动过程中看不见的部分是一个不适定问题,可能会遇到潜在的不稳定性。这意味着模型在处理视角变化或视角之外的信息时可能会面临挑战。
-
运行效率:使用了DDPM(Denoising Diffusion Probabilistic Models)的模型相比于非扩散模型的方法在运行效率上较低。这可能影响模型在需要实时或快速生成动画视频的应用场景中的实用性。
这篇关于AIGC-Animate Anyone阿里的图像到视频 角色合成的框架-论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






