本文主要是介绍浅谈MapReduce核心之shuffle,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hadoop拥有三大核心组件,HDFS作为底层的分布式文件系统,MapReduce作为计算框架,yarn作为资源调度管理器。
对于开发人员来说,理解MapReduce是很重要的。
在WordCount程序中,map生成的结果是一个个的元组,类似于(hello,1),非常非常多的元组,由context写入到hdfs中,而后续的Reduce阶段,实际上reduce方法接收的参数类似于这种,(hello,<1,2,3,4,5>);这里面,问题就出现了,为什么map的输出结果,到了reduce端成了这个样子,其中最为关键的就是称为shuffle的阶段。
本文,就对shuffle阶段做一定的介绍。
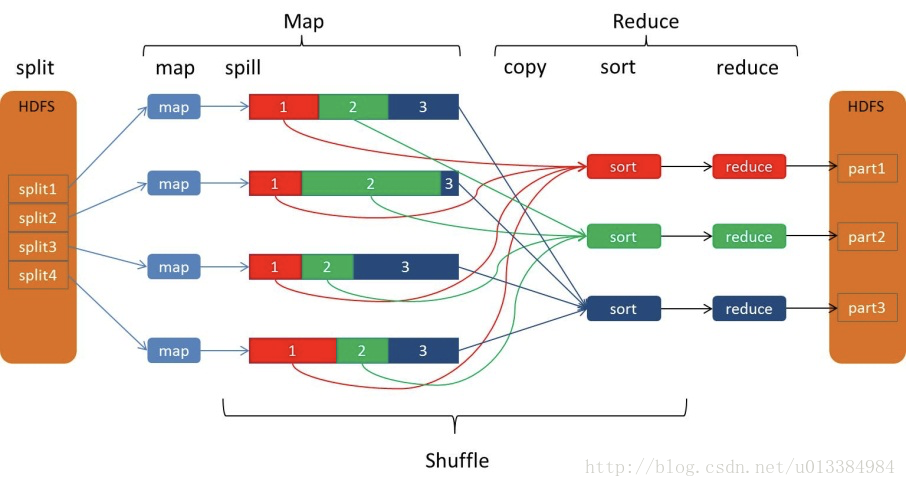
上图,是诸多介绍shuffle过程用得比较多的一张图。
实际上,我们的实现知识map的逻辑以及reduce的逻辑,而以上很多的逻辑,隐藏在MapReduce的内核,只有深刻理解其内部原理,才能写出更好的MapReduce程序,譬如可以很好地避免数据倾斜问题。
以下介绍,全部基于WordCount。
1:数据读取阶段
代码中,最基本的读取应该是InputFormat,其本身是个抽象类,具有很多实现,可以从数据库,本地文件或者HDFS等很多地方读取数据,对于wordCount来说,使用的是FileInputFormat,其会读取文件,并且按照HDFS的存储格式,将文件存储起来,这样就会将文件进行切片,生成一个一个小的split,切分的标准应该是依据于block的大小;而读入的效果,则是类似于这种<offset,line>,offset指的是每一行的偏移量,而line则是每一行的内容,这就是接下来Map阶段的输入。
2:map阶段
map阶段,就是我们通常使用的逻辑,当然,执行起来肯定不单单一个map,而是有很多map在众多节点上分布执行,这里面map基本上都会本地化读取,就是尽可能地读取本机的数据来进行map的处理;而对于处理的结果,会先写到内存中;就单说一个map吧,会源源不断地把结果写入到内存中,但是,这块内存区的大小是有限制的,不可能一直写,通常在其内存区写入达到80%的时候,map输出的结果,就会往磁盘内spill数据。
3:spill阶段
这部分,就是map生成的结果不断往磁盘内写数据的过程,而实际上,spill过程中,会按照partition的不同,分成不同的区,而在区内,数据是有序的;这里提到的区,数量与后面的reducetask的数量是一致的,方便reducetask拉取数据,简单说,就是分区有序,排序算法用的是快速排序;其实我觉得,在内存中排序其实更快一些,没看源码,具体逻辑不清楚了,总之,每次spill都会生成多个对应于多个partition的有序数据;而随着map执行完毕,通常会有partitionNum * spillTimes的文件;而且,每个map任务都有数据。
4:merge
其实,在Map端,应该也是有数据的merge,不仅仅是最后reduce拉取数据之前的combine使用;在这里,对于每个partition来说,都有很多的spill小文件,所以会把这些小文件汇聚成大文件,当然,这里也是排序的,采用归并排序的算法;最后,对于一个map任务来说,其管辖下的众多partition,各自会有自己的大文件,这里,就是reduce处理的Iterator的一小部分了;另外,这里必须要提一下combine,其内部实现逻辑基本与reduce一致,会把数据进行合并,目的就是减小拉取到reduce阶段的数据,比如说如果是max操作或者min操作,可以很大程度减小发送给reducer需要拉取的结果了。
这里,reducer也是优先处理本地的map生成的数据,但通常都要拉取很多文件,因为有些时候最终的reducer只有一个;这里,还要插播一句,map文件存储到本地会有一定的压缩策略,这也是减小reducer拉取数据的一个办法;综上,map端会对数据进行压缩,执行简单的combine逻辑,进行spill文件的合并,准备好reducer拉取的文件。
5:copy
这就是拉取的逻辑了,每个reducer都会从其他的mapper拉取数据,而且这里还存在一个mapReduce的瓶颈,那就是必须所有的map全部结束之后,reducer才能开始拉取数据;一般来说,reducer拉取到的数据,来自于多个mapper。
6:sort & merge
数据拉取过来之后,还需要进行排序:原因在于,虽然拉取到的数据属于一定的范围,但是直接组合在一起并不一定是有序的,所以还需要一定的排序操作;这里边的merge,指的是reducer端的merge,生成最终用于Reducer处理的数据;而reducer对于这些文件进行处理,生成最终的结果。
其实大家计算的过程中会看到,最终有多少个reducer,对应多少个分区,最后就会生成几个文件的。
shuffle原理大致如上。
其实MapReduce是存在几个瓶颈的:
- map结果写入磁盘:写入磁盘之后,后期还需要再进行读取出来,进行传输,这个性能其实是比较差的。注解:网上很多地方提到这一点,但是我觉得,如果不落盘的话,那怎么传输给reducer?内存传输?没搞懂大家为啥都一致认为这一点是spark要优于MR的地方,都是说spark内存运算。
- 当所有的mapper都结束之后,才能开始reducer的操作,这样导致有些执行比较快的mapper,只能空等,而如果让先完成的mapper可以直接把数据发送给reducer的话,对于性能有一定提升。
参考资料:
- http://blog.csdn.net/aijiudu/article/details/72353510
- http://blog.csdn.net/techchan/article/details/53405519
这篇关于浅谈MapReduce核心之shuffle的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



