shuffle专题

Spark学习之路 (十)SparkCore的调优之Shuffle调优
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 一、概述 二、shuffle的定义 三、ShuffleManager发展概述 四、HashShuffleManager的运行原理 4.1 未经优化的HashShuffleManager 4.2 优化后的HashShuffleManager 五、SortShuffleManager运行原理 5.1 普通

【硬刚Hadoop】HADOOP MAPREDUCE(7):Shuffle机制(3)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 7 Combiner合并 (6)自定义Combiner实现步骤 (a)自定义一个Combiner继承Reducer,重写Reduce方法 public class WordcountCombiner extends Reducer<Text, IntWritable, Text,

【硬刚Hadoop】HADOOP MAPREDUCE(6):Shuffle机制(2)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 4 WritableComparable排序 1.排序的分类 2.自定义排序WritableComparable (1)原理分析 bean对象做为key传输,需要实现WritableComp

【硬刚Hadoop】HADOOP MAPREDUCE(5):Shuffle机制(1)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 1 Shuffle机制 Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图4-14所示。 2 Partition分区

Spark Shuffle FetchFailedException解决方案
在大规模数据处理中,这是个比较常见的错误。 报错提示 SparkSQL shuffle操作带来的报错 org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0 org.apache.spark.shuffle.FetchFailedExcep

【Spark系列8】Spark Shuffle FetchFailedException报错解决方案
前半部分来源:http://blog.csdn.net/lsshlsw/article/details/51213610 后半部分是我的优化方案供大家参考。 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ SparkSQL shuffle操作带来的报
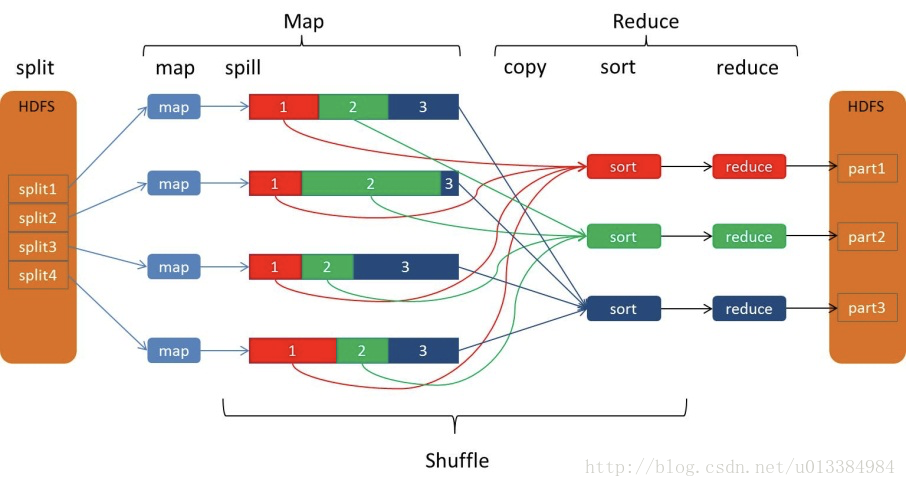
浅谈MapReduce核心之shuffle
Hadoop拥有三大核心组件,HDFS作为底层的分布式文件系统,MapReduce作为计算框架,yarn作为资源调度管理器。 对于开发人员来说,理解MapReduce是很重要的。 在WordCount程序中,map生成的结果是一个个的元组,类似于(hello,1),非常非常多的元组,由context写入到hdfs中,而后续的Reduce阶段,实际上reduce方法接收的参数类似于这种,(hel

MapReduce的shuffle过程详解(分片、分区、合并、归并)
shuffle过程 shuffle概念 shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前
Spark-push-based shuffle
一、上下文 《Spark-Task启动流程》中讲到如果一个Task是一个ShuffleMapTask,那么最后在调用ShuffleWriter写入磁盘后还会判断是否可以启用push-based shuffle机制,下面我们就来继续看看push-based shuffle机制背后都做了什么 二、push-based shuffle机制开启条件 1、spark.shuffle.push.enab
“ error in shuffle in fetcher”的解决方案
问题场景 使用hive进行数据的统计,发现数据进行到一半,就异常退出。查看了报错,是栈溢出,导致了异常。 问题分析 通过查找资料和查看资料,才发现,在shuffle阶段,会将map的output数据给取下来,然后根据设定的参数决定是放进内存中,还是存储到磁盘里面进行操作。而mapreduce.reduce.shuffle.memory.limit.percent这个参数默认值是0.25,代表
【C++】algorithm--shuffle
shuffle在algorithm当中 // shuffle algorithm example#include <iostream> // std::cout#include <algorithm> // std::shuffle#include <array> // std::array#include <random> // std::de

Hadoop中MapReduce中combine、partition、shuffle的作用是什么?在程序中怎么运用?
InputFormat类:该类的作用是将输入的文件和数据分割成许多小的split文件,并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,默认的情况为类TextInputFormat,其中Key默认为字符偏移量,value是该行的值。 Map类:根据输入的<Key,Value>对生成中间结果
numpy.random中的shuffle和permutation
shuffle: 沿着第一个axis打乱子数组的顺序,但是内容不变,相当于沿着第一个axis把array切成n个sub-array,然后打乱sub-array的顺序。(如果只有一维就只打乱元素) >>> arr = np.arange(9).reshape((3, 3))>>> np.random.shuffle(arr)>>> arrarray([[3, 4, 5],[6, 7, 8]

大数据-97 Spark 集群 SparkSQL 原理详细解析 Broadcast Shuffle SQL解析过程
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(正在更新!) 章节内容 上节我们完成了如下的内容: SparkSQL 语句 编码 测试 结果输入

大数据技术之_05_Hadoop学习_02_MapReduce_MapReduce框架原理+InputFormat数据输入+MapReduce工作流程(面试重点)+Shuffle机制(面试重点)
大数据技术之_05_Hadoop学习_02_MapReduce 第3章 MapReduce框架原理3.1 InputFormat数据输入3.1.1 切片与MapTask并行度决定机制3.1.2 Job提交流程源码和切片源码详解3.1.3 FileInputFormat切片机制3.1.4 CombineTextInputFormat切片机制3.1.5 CombineTextInputForma
Hadoop中的Shuffle 与 Spark中的Shuffle的区别与联系
MapReduce过程、Spark和Hadoop以Shuffle为中心的对比分析 mapreduce与Spark的map-Shuffle-reduce过程 mapreduce过程解析(mapreduce采用的是sort-based shuffle) 将获取到的数据分片partition进行解析,获得k/v对,之后交由map()进行处理. map函数处理完成之后,进入collect阶段,
理解Spark-RDD的Shuffle操作
1.Spark中的某些操作会触发称为shuffle的事件。 随机广播是Spark的重新分发数据的机制,因此它可以跨分区进行不同的分组。 这通常涉及跨执行程序和机器复制数据,使得Shuffle成为复杂且昂贵的操作。 2.为了理解在shuffle期间发生的事情,我们可以考虑reduceByKey操作的示例。 reduceByKey操作生成一个新的RDD, 其中单个键的所有值都组合成一个元组 -

spark 大型项目实战(四十五):troubleshooting之解决JVM GC导致的shuffle文件拉取失败
1. 比如,executor的JVM进程,可能内存不是很够用了。那么此时可能就会执行GC。minor GC or full GC。总之一旦发生了JVM之后,就会导致executor内,所有的工作线程全部停止。 2. 下一个stage的executor,可能是还没有停止掉的,task想要去上一个stage的task所在的exeuctor,去拉取属于自己的数据,结果由于对方正在gc,就导致拉取了

spark 大型项目实战(四十四):troubleshooting之控制shuffle reduce端缓冲大小以避免OOM
1. map端的task是不断的输出数据的,数据量可能是很大的。 但是,其实reduce端的task,并不是等到map端task将属于自己的那份数据全部写入磁盘文件之后,再去拉取的。map端写一点数据,reduce端task就会拉取一小部分数据,立即进行后面的聚合、算子函数的应用。 每次reduece能够拉取多少数据,就由buffer来决定。因为拉取过来的数据,都是先放在buffer中的。然
tf.train.batch和tf.train.shuffle_batch的理解
capacity是队列的长度 min_after_dequeue是出队后,队列至少剩下min_after_dequeue个数据 假设现在有个test.tfrecord文件,里面按从小到大顺序存放整数0~100 1. tf.train.batch是按顺序读取数据,队列中的数据始终是一个有序的队列, 比如队列的capacity=20,开始队列内容为0,1,..,19=>读取10条记录后,队列剩下10,

Spark-Shuffle阶段优化-Bypass机制详解
Spark概述 Spark-Shuffle阶段优化-Bypass机制详解 Spark的Bypass机制是一种特定情况下的优化策略,目的是减少Shuffle过程中不必要的排序开销,从而提升性能。当Shuffle分区数较少且数据量不大时,Bypass机制可以显著加快Shuffle速度。 1.什么是Shuffle? 在分布式计算中,Shuffle是将数据从Map阶段传递到Reduce阶段的过
python的random模块三choices和shuffle()
choices()从给定序列中随机选取元素序列 语法: random.choices(population, weights=None, *, cum_weights=None, k=1) population:必须是一个序列,可以是列表,元组,字符串等等。表示要从中选取元素的序列。weights:可选参数。必须是一个数字序列,长度必须和population相同。表示每个元素被选中的概率,可
LeetCode contest 192 5428. 重新排列数组 Shuffle the Array
Table of Contents 一、中文版 二、英文版 三、My answer 四、解题报告 一、中文版 给你一个数组 nums ,数组中有 2n 个元素,按 [x1,x2,...,xn,y1,y2,...,yn] 的格式排列。 请你将数组按 [x1,y1,x2,y2,...,xn,yn] 格式重新排列,返回重排后的数组。 示例 1: 输入:nums = [2,5,

spark shuffle的演进过程
spark各版本shuffle的变化 Spark 0.8及以前 Hash Based ShuffleSpark 0.8.1 为Hash Based Shuffle引入File Consolidation机制Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based ShuffleSpark 1.2 默认的Shuffle方式改为Sort Based Shuffle
Hadoop 1.x的Shuffle源码分析之3
shuffle有两种,一种是在内存存储数据,另一种是在本地文件存储数据,两者几乎一致。 以本地文件进行shuffle的过程为例: mapOutput = shuffleToDisk(mapOutputLoc, input, filename, compressedLength) shuffleToDisk函数如下: private MapOutput shuffleTo
Hadoop 1.x的Shuffle源码分析之2
ReduceTask类的内嵌类ReduceCopier的内嵌类MapOutputCopier的函数copyOutput是Shuffle里最重要的一环,它以http的方式,从远程主机取数据:创建临时文件名,然后用http读数据,再保存到内存文件系统或者本地文件系统。它读取远程文件的函数是getMapOutput。 getMapOutput函数如下: private MapOutput