本文主要是介绍Pytorch分布式train——pytorch.distributed.launch V.S. torchrun,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 较早的pytorch.distributed.launch
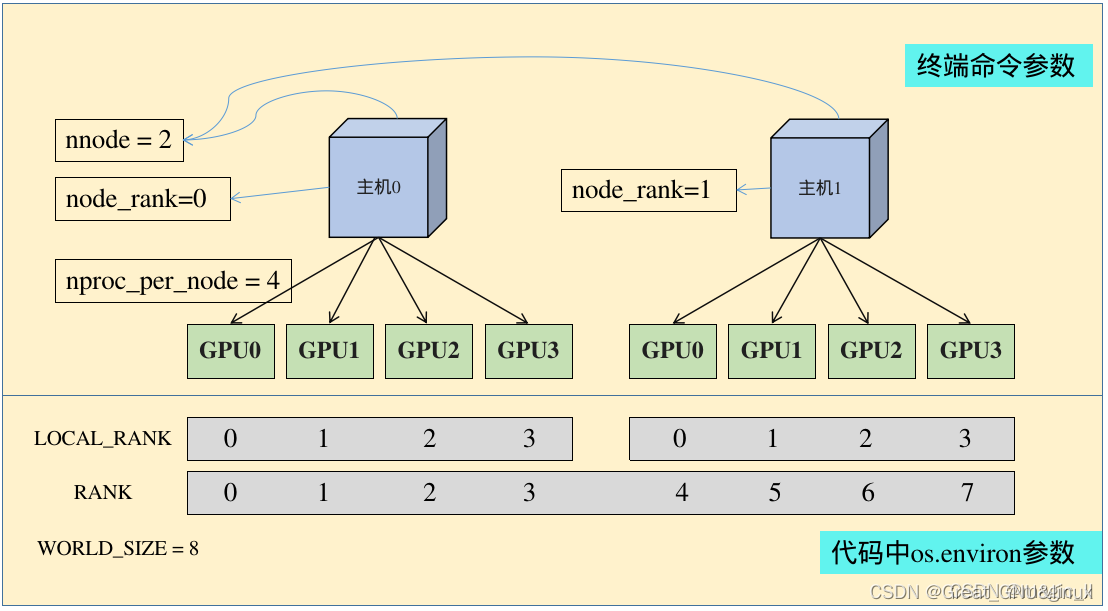
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 train.py --args XXX
参数解析:
nnodes:节点(主机)的数量,通常一个节点对应一个主机
node_rank:指的是当前启动的是第几台服务器,从 0 开始。
nproc_per_node:一个节点中显卡的数量
-master_addr:master节点的ip地址,也就是0号主机的IP地址,该参数是为了让 其他节点 知道0号节点的位,来将自己训练的参数传送过去处理
-master_port:master节点的port号,在不同的节点上master_addr和master_port的设置是一样的,用来进行通信
原文链接:http://t.csdnimg.cn/bDRj0
2. transfer a torch variable to a gpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 指定设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 指定设备device = (input1.device if input1.is_cuda else torch.device('cpu')) # 指定目标变量的设备x=x.to(device)
这篇关于Pytorch分布式train——pytorch.distributed.launch V.S. torchrun的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







