train专题

OpenStack离线Train版安装系列—3控制节点-Keystone认证服务组件
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版

OpenStack离线Train版安装系列—2计算节点-环境准备
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版

OpenStack离线Train版安装系列—1控制节点-环境准备
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版

OpenStack离线Train版安装系列—0制作yum源
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版
OpenStack离线Train版安装系列—10.控制节点-Heat服务组件
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版

OpenStack离线Train版安装系列—11.5实例使用-Cinder存储服务组件
本系列文章包含从OpenStack离线源制作到完成OpenStack安装的全部过程。 在本系列教程中使用的OpenStack的安装版本为第20个版本Train(简称T版本),2020年5月13日,OpenStack社区发布了第21个版本Ussuri(简称U版本)。 OpenStack部署系列文章 OpenStack Victoria版 安装部署系列教程 OpenStack Ussuri版

Tensorflow 中train和test的batchsize不同时, 如何设置: tf.nn.conv2d_transpose
大家可能都知道, 在tensorflow中, 如果想实现测试时的batchsize大小随意设置, 那么在训练时, 输入的placeholder的shape应该设置为[None, H, W, C]. 具体代码如下所示: # Placeholders for input data and the targetsx_input = tf.placeholder(dtype=tf.float32, s
tf.train.batch 和 tf.train.batch_join的区别
先看两个函数的官方文档说明 tf.train.batch官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch tf.train.batch_join官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch_join tf.train.ba
tf.train.ExponentialMovingAverage用法和说明
在这篇博客中对tf.train.ExponentialMovingAverage讲的很清楚,这里主要补充几点说明: 第一点: 当程序执行到 ema_op = ema.apply([w]) 的时候,如果 w 是 Variable, 那么将会用 w 的初始值初始化 ema 中关于 w 的 ema_value,所以 emaVal0=1.0。如果 w 是 Tensor的话,将会用 0.0 初始化。

tf.train.exponential_decay(学习率衰减)
#!/usr/bin/env python3# -*- coding: utf-8 -*-'''学习率较大容易搜索震荡(在最优值附近徘徊),学习率较小则收敛速度较慢,那么可以通过初始定义一个较大的学习率,通过设置decay_rate来缩小学习率,减少迭代次数。tf.train.exponential_decay就是用来实现这个功能。'''__author__ = 'Zhang Shuai'i

How to train openai model using fine tune in nodejs
题意: 如何在 Node.js 中使用微调来训练 OpenAI 模型 问题背景: I need to train my openai model using nodejs programming language. 我需要使用 Node.js 编程语言来训练我的 OpenAI 模型。 I just got python script to train my openai mode
299 - Train Swapping
题目:299 - Train Swapping 题目大意:将火车车厢号按从小到大排序,只有相邻的两节车厢才能交换,计算最少的交换次数。 解题思路:泡沫排序法,每次都将剩余的无序区中的最小元素放到无序区的第一个位置,而且是相邻的数两两比较,进行调整。 #include<stdio.h>#include<stdlib.h>const int N = 55;int t,
scikit-learn中常见的train test split
1. train_test_split 进行一次性划分 import numpy as npfrom sklearn.model_selection import train_test_splitX, y = np.arange(10).reshape((5, 2)), range(5)"""X: array([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])l
【chatgpt】train_split_test的random_state
在使用train_test_split函数划分数据集时,random_state参数用于控制随机数生成器的种子,以确保划分结果的可重复性。这样,无论你运行多少次代码,只要使用相同的random_state值,得到的训练集和测试集划分就会是一样的。 使用 train_test_split 示例 以下是一个示例,展示如何使用train_test_split函数进行数据集划分,并设置random_s
tf.train.batch和tf.train.shuffle_batch的理解
capacity是队列的长度 min_after_dequeue是出队后,队列至少剩下min_after_dequeue个数据 假设现在有个test.tfrecord文件,里面按从小到大顺序存放整数0~100 1. tf.train.batch是按顺序读取数据,队列中的数据始终是一个有序的队列, 比如队列的capacity=20,开始队列内容为0,1,..,19=>读取10条记录后,队列剩下10,
ValueError: Shape must be rank 0 but is rank 1 for 'train_data/ReadFile' (op: 'ReadFile') with input
使用函数tf.train.slice_input_producer读取文件时, input_queue = tf.train.slice_input_producer([flist], shuffle=self.shuffle,seed=0123, num_epochs=self.num_epochs)input_file = tf.read_file(input_queue) 出现错误:
train订票系统优化最终版
.h文件#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <stdlib.h>#include <string.h>struct train {//车次的属性int id;char name[50];int remainTickets;};struct node {//普通节点的属性struct node *next;st
caffe CNN train_val.prototxt 神经网络参数配置说明
name: "CaffeNet"layer {#输入层,即数据层#数据层的类型除了Database外,还可以是In-Memory、HDF5 Input、HDF5 Output、Images、Windows、Dummyname: "data"type: "Data"top: "data"top: "label"include {phase: TRAIN#表示仅在训练阶段包括进去
Sklearn工具包---train_test_split随机划分训练集和测试集
一般形式: train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data,形式为: X_train,X_test, y_train, y_test = cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_stat
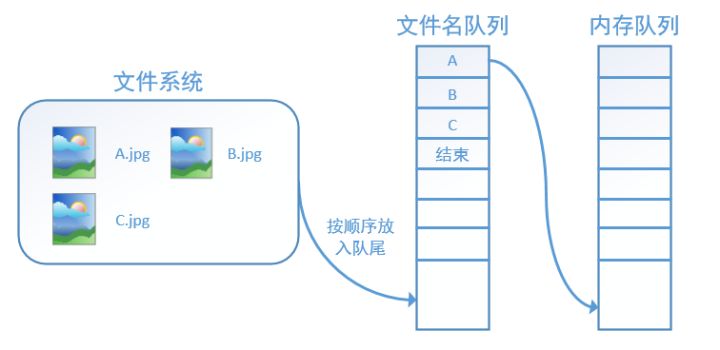
tensorflow中 tf.train.slice_input_producer() 函数和 tf.train.batch() 函数
原创:https://blog.csdn.net/dcrmg/article/details/79776876 别人总结的转载方便自己以后看 tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责
tf.estimator.train_and_evaluate() 训练与测试不一致
问题背景 以一个简单的分类任务为例,在处理完数据之后,使用如下code进行训练: estimator = tf.estimator.Estimator(model_fn, 'model', cfg, params)train_spec = tf.estimator.TrainSpec(input_fn=train_inpf, hooks=[])eval_spec = tf.estimato
UVa - 10194 - Train Swapping
啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦 怀着无比激动的心情。 某大神助攻。 不然就废了 收:strcasecmp(s1, s2); 题目大意: 多支队伍比赛。 记录每支队伍 1总共赢的分数(赢了得3分,平得1分,输不得分) 2共比赛的场数 3共赢的常数 4共平的场数 5共输的场数 6赢球数与输球数之差 7共赢的球数(输的场中

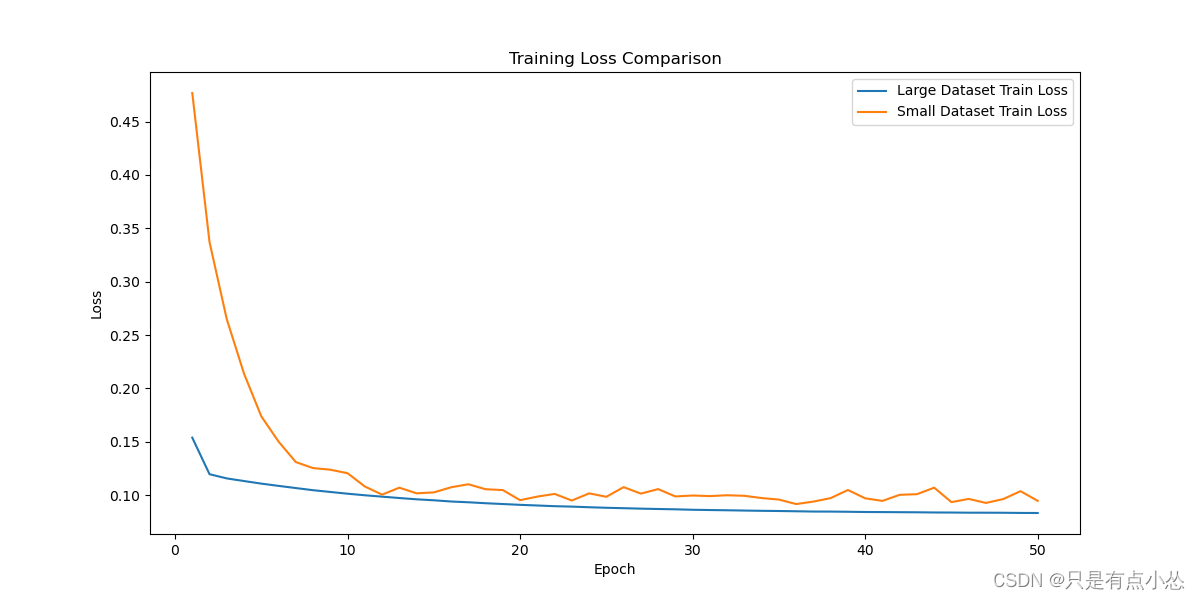
yolov8m train 验证时间过长
yolov8m train 验证时间过长 YOLOv8m(You Only Look Once version 8 medium)是YOLO目标检测系列的一个中等大小的模型版本。如果您在训练YOLOv8m模型时发现验证时间过长,可能是由以下几个原因导致的: 数据集大小:如果您的数据集非常大,那么每次验证时都需要处理大量的图像,这会显著增加验证时间。 模型复杂度:虽然YOLOv8m是中等大小的

train_gpt2_fp32.cu - layernorm_forward_kernel3
源码 __global__ void layernorm_forward_kernel3(float* __restrict__ out, float* __restrict__ mean, float* __restrict__ rstd,const float* __restrict__ inp, const float* __restrict__ weight,const float*