本文主要是介绍Distributed Transactions Mit 6.824,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Topic1:distributed transactions = concurrency control + atomic commit
传统计划:事务
程序员标记代码序列的开始/结束作为事务。
事务示例
x和y是银行余额——数据库表中的记录。x和y位于不同的服务器上(可能在不同的银行)。x和y开始时都是 $10。T1和T2是事务。T1: 从x向y转账 $1。T2: 审计,检查没有钱丢失。
事务操作
T1: T2:
begin_xaction begin_xactionadd(x, 1) tmp1 = get(x)add(y, -1) tmp2 = get(y)
end_xaction print tmp1, tmp2end_xaction
事务的正确行为是什么?
通常被称为“ACID”:
- 原子性(Atomic) - 尽管有失败,但要么全部写入成功,要么一个也不写。
- 一致性(Consistent) - 遵守应用程序特定的不变量。
- 隔离性(Isolated) - 事务之间没有干扰——可串行化。
- 持久性(Durable) - 提交的写操作是永久的。
什么是可串行化?
当您执行一些并发事务并产生结果时,“结果”既包括输出也包括数据库中的变化。如果满足以下条件,则这些结果是可串行化的:
- 存在一种串行执行事务的顺序,
- 这种顺序产生的结果与实际执行的结果相同。
(串行意味着一次一个——没有并行执行。)
(这个定义应该让你想起线性一致性。)
您可以通过寻找产生相同结果的顺序来测试执行结果是否是可串行化的。对于我们的例子,可能的串行顺序是:
- T1; T2
- T2; T1
因此,正确的(可串行化的)结果是:
- T1; T2:x=11 y=9 “11,9”
- T2; T1:x=11 y=9 “10,10”
两者的结果不同;任何一种都可以接受。没有其他结果是可以接受的。实现可能已经并行执行了T1和T2,但它必须仍然产生如同按照串行顺序执行一样的结果。
为什么可串行化很受欢迎
- 对程序员来说是一个简单的模型
- 程序员可以编写复杂的事务,同时忽略并发性。
- 它允许对不同记录的事务进行并行执行。
事务可以在出现问题时“中止”
- 中止会撤销任何记录修改。
- 事务可能会自愿中止,
- 例如,如果账户不存在,或者
y的余额小于等于0。
- 例如,如果账户不存在,或者
- 系统可能会强制中止,例如,为了打破锁定死锁。
- 一些服务器故障会导致中止。
- 应用程序可能会(也可能不会)再次尝试事务
分布式事务包含两个主要组成部分:
- 并发控制(提供隔离性/可串行化)
- 原子提交(尽管有失败,也能提供原子性)
首先,让我们谈谈并发控制:
- 正确执行并发事务
事务的并发控制分为两类:
- 悲观并发控制:
- 在使用记录前对其加锁
- 冲突会导致延迟(等待锁)
- 乐观并发控制:
- 不加锁地使用记录
- 提交时检查读/写操作是否可串行化
- 冲突会导致中止+重试
- 称为乐观并发控制(OCC)
- 如果冲突频繁,悲观并发控制更快
- 如果冲突罕见,乐观并发控制更快
今天的话题是悲观并发控制,下周将讨论乐观并发控制(FaRM)。
“两阶段锁定”是实现可串行化的一种方式:
- 两阶段锁(2PL)定义:
- 事务在使用记录前必须获取记录的锁
- 事务必须持有其锁,直到提交或中止之后
我们例子中的两阶段锁定
假设T1和T2同时开始:
- 事务系统会根据需要自动获取锁
- 因此,T1/T2中首先使用x的将获取锁
- 另一个事务将等待,直到第一个事务完全结束
- 这阻止了非可串行化的交错执行
详细信息:
- 每个数据库记录都有一个锁
- 如果是分布式的,锁通常存储在记录的服务器上
- [图表:客户端、服务器、记录、锁]
- (但两阶段锁定不太受分布式影响)
- 执行事务需要时获取锁,首次使用时
add()和get()隐式获取记录的锁end_xaction()释放所有锁
- 所有锁都是排他性的(在此讨论中,没有读/写锁)
- 全名是“强严格两阶段锁定”
- 与线程锁定相关(例如,Go的Mutex),但更简单:
- 显式的
begin/end_xaction - 数据库在每条记录首次使用时自动加锁
- 数据库在事务结束时自动解锁
- 数据库可能会自动中止以解决死锁
- 显式的
保持锁直到提交(commit)或中止(abort)之后的原因是为了确保事务的整体原子性和一致性。如果在完成记录使用后立即释放锁,可能会导致一些问题,例如:
- 如果T2在
get(x)后立即释放x的锁,T1就可以在T2的两次get()操作之间执行。结果,T2可能会打印10,9,这并不是一个可串行化的执行:既不是T1;T2也不是T2;T1的顺序。 - 如果T1写入x然后立即释放x的锁,T2可以读取x并打印结果。但如果T1之后中止,那么T2使用了一个实际上从未存在过的值。理论上,我们应该中止T2,这将是一个“级联中止”;这样做会非常尴尬。
两阶段锁定(2PL)可能会导致死锁,例如:
T1 T2
get(x) get(y)
get(y) get(x)
系统必须检测(循环?锁超时?)并中止一个事务。
两阶段锁定(2PL)是否会禁止一个正确的(可串行化的)执行?
是的,例如:
T1 T2
get(x) get(x)put(x,2)
put(x,1)
锁定会禁止这种交错执行,但结果(x=1)是可串行化的(与T2;T1相同)。
问题:描述一个情况,其中两阶段锁定比简单锁定产生更高的性能。
简单锁定:在任何使用之前锁定每个记录;在中止/提交后释放。
两阶段锁定(2PL)比简单锁定(Simple Locking)表现出更高性能的一个情况是:
- 当事务访问的数据集合较小并且与其他事务的重叠较少时。在这种情况下,2PL通过只在需要时锁定记录,允许更多的并行执行。事务可以更快地完成其操作并释放资源,减少了等待和阻塞的时间,从而提高了整体系统性能。
- 相反,简单锁定策略要求事务在开始执行任何操作之前锁定其将访问的所有记录,这会导致不必要的等待,特别是在事务只需要读取一小部分其锁定记录的情况下。这种策略在高并发环境下性能较差,因为它限制了并行操作的可能性,增加了事务完成时间。
Next topic: distributed transactions versus failures
我们将开发一个称为“两阶段提交”的协议,它被分布式数据库用于多服务器事务
我们想要的是“原子提交”:
- 一群计算机在某项任务上合作
- 每台计算机扮演不同的角色
- 想要确保原子性:全部执行,或者全部不执行
- 挑战:故障,性能
设置
- 数据在多个服务器之间分片
- 事务在“事务协调器”(TC)上运行
- 对于每个读/写,TC向相关的分片服务器发送RPC
- 每个都是一个“参与者”
- 每个参与者管理其数据分片的锁
- 可能有许多并发事务,许多TC
- TC为每个事务分配唯一的事务ID(TID)
- 每条消息,每个表条目都用TID标记
- 为了避免混淆
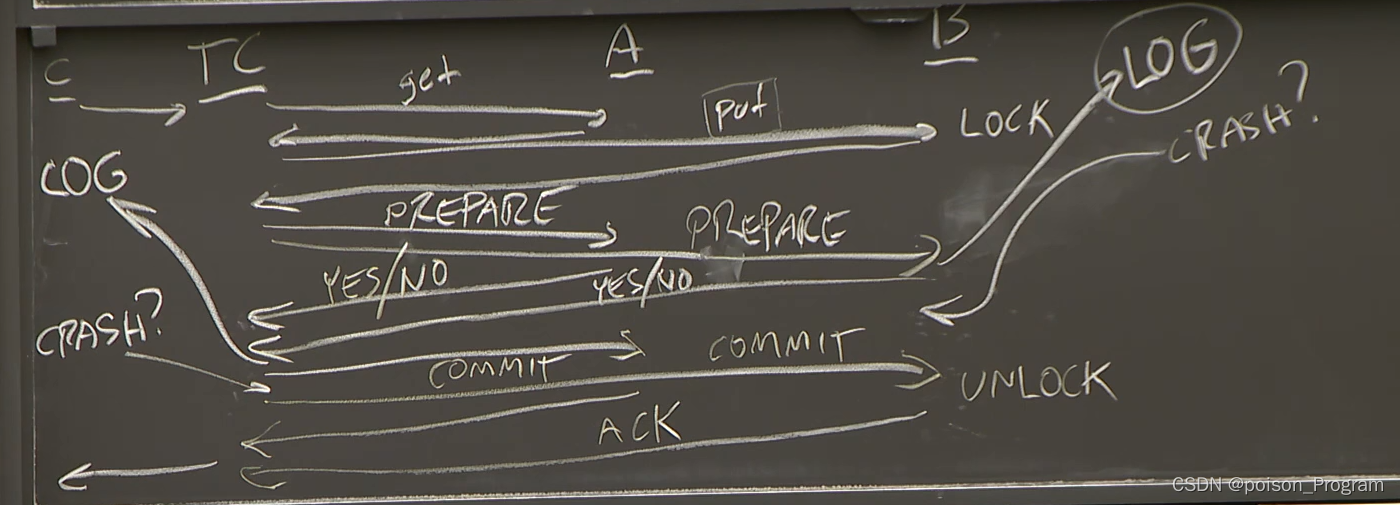
无故障时的两阶段提交:
- TC向A,B发送put(),get()等RPC
- 修改是暂定的,只有在提交时才会安装。
- TC进行到事务的末尾。
- TC向A和B发送准备(PREPARE)消息。
- 如果A愿意提交,
- A回应YES。
- 然后A处于“准备好的”状态。
- 否则,A回应NO。
- B也是同样。
- 如果A和B都说YES,TC向A和B发送提交(COMMIT)消息。
- 如果A或B任何一个说NO,TC发送中止(ABORT)消息。
- 如果A/B收到TC的提交消息,他们将提交。
- 即,他们将暂定记录写入真实数据库。
- 并释放其记录上的事务锁。
- A/B确认提交消息。
这个协议试图确保即使在分布式系统中发生故障时,事务也能保持原子性,确保所有参与的服务器要么都提交事务,要么都不提交。
这为什么到目前为止是正确的?
- 除非A和B都同意,否则它们都不能提交。
如果B崩溃并重启会怎样?
- 如果B在崩溃前发送了YES,B必须记住(尽管发生了崩溃)!
- 因为A可能已经收到了COMMIT消息并提交了。
- 所以B必须能够在重启后提交(或不提交)。
因此,参与者必须写入持久的(磁盘上的)状态:
- B在说YES前必须在磁盘上记住,包括修改过的数据。
- 如果B重启,磁盘显示YES但没有COMMIT,
- B必须询问TC,或等待TC重新发送。
- 与此同时,B必须继续持有事务的锁。
- 如果TC说COMMIT,B将修改的数据复制到真实数据。
如果TC崩溃并重启会怎样?
- 如果TC可能在崩溃前发送了COMMIT,TC必须记住!
- 因为一个工作者可能已经提交了。
- 因此,TC必须在发送COMMIT消息前将COMMIT写入磁盘。
- 并且如果它崩溃并重启后重复COMMIT,
- 或者如果参与者询问(即,如果A/B没有收到COMMIT消息)。
- 参与者必须过滤掉重复的COMMIT(使用TID)。
如果TC从B那里永远得不到YES/NO怎么办?
- 也许B崩溃了并没有恢复;也许网络出现了故障。
- TC可以超时,并中止(因为没有发送任何COMMIT消息)。
- 好处是:允许服务器释放锁。
如果B在等待TC的PREPARE时超时或崩溃怎么办?
- B还没有对PREPARE做出回应,所以TC不能决定提交
- 所以B可以单方面中止,并释放锁
- 对未来的PREPARE响应NO
如果B回答了PREPARE的YES,但没有收到COMMIT或ABORT怎么办?
- B可以单方面决定中止吗?
- 不可以!TC可能已经从两者那里得到了YES,
- 并且向A发送了COMMIT,但在发送给B之前崩溃了。
- 那么A将提交而B将中止:这是错误的。
- B也不能单方面提交:
- A可能已经投了NO。
所以:如果B投了YES,它必须“阻塞”:等待TC的决定。
注意:
- 提交/中止决定由单一实体——TC做出。
- 这使得两阶段提交相对直接。
- 惩罚是A/B在投了YES之后必须等待TC。
TC何时可以完全忘记一个已提交的事务?
- 如果它从每个参与者那里收到了对COMMIT的确认。
- 然后没有参与者会再次需要询问。
参与者何时可以完全忘记一个已提交的事务?
- 在它确认了TC的COMMIT消息之后。
- 如果它再次收到COMMIT,并且没有该事务的记录,
- 它必须已经提交并忘记了,并且可以再次确认。
两阶段提交的视角
- 在事务使用多个分片上的数据时,在分片数据库中使用
- 但它有不好的声誉:
- 慢:多轮消息传递
- 慢:磁盘写入
- 在准备/提交交换期间持有锁;阻塞其他事务
- TC崩溃可能导致无限期阻塞,同时持有锁
- 因此通常只在单一小领域中使用
- 例如,不在银行之间,不在航空公司之间,不在广域网上
Raft和两阶段提交解决的是不同的问题!
- 使用Raft通过复制来获得高可用性
- 即,当一些服务器崩溃时仍能操作
- 服务器都做相同的事情
- 使用2PC是当每个参与者做不同的事情时
- 并且所有参与者都必须做他们的部分
- 2PC不提高可用性
- 因为所有服务器必须运行才能完成任何事情
- Raft不确保所有服务器都做某事
- 因为只需要大多数活着就可以了
如果你想要高可用性和原子提交怎么办?
- 这里有一个计划。
- TC和服务器应该每个都用Raft复制
- 在复制的服务之间运行两阶段提交
- 然后你可以在容忍故障的同时仍然取得进展
- 你将在实验4中构建类似的东西来转移分片
- 下次会议的Spanner使用了这种安排
FAT
-
为什么事务的原子性如此重要?
所谓“事务”,意味着事务内的步骤相对于故障和其他事务而言是原子性发生的。这里的原子性意味着“全部或无”。事务是某些存储系统提供的一项功能,旨在简化编程工作。事务有用的一个例子是银行转账。如果银行想要从爱丽丝的账户转移100美元到鲍勃的账户,如果在此过程中途发生崩溃,导致爱丽丝的账户被扣除了100美元但鲍勃的账户未增加100美元,这将非常尴尬。因此,如果您的存储系统支持事务,程序员可以编写如下内容:
BEGIN TRANSACTIONdecrease Alice's balance by 100;increase Bob's balance by 100; END TRANSACTION事务系统将确保事务是原子的;即使在某处发生故障,也要么两者都发生,要么都不发生。
-
两阶段锁定是否会产生死锁?
是的。如果两个事务都使用记录R1和R2,但以相反的顺序,它们将各自获得其中一个锁,然后在尝试获取另一个锁时发生死锁。数据库能够检测到这些死锁并解决它们。数据库可以通过锁获取的超时,或者在事务之间的等待图中寻找循环来检测死锁。可以通过中止参与的其中一个事务来打破死锁。
-
可以同时有多个活跃的事务吗?参与者如何知道一条消息是指哪个事务?
可以有许多并发事务,由许多事务协调器(TC)管理。TC为每个事务分配一个唯一的事务ID(TID)。每条消息都包括相关事务的TID。TC和参与者用TID标记他们表中的条目,这样(例如)当一个COMMIT消息到达一个参与者时,它知道哪些暂定记录要变成永久的,以及要释放哪些锁。
-
如果必须中止一个事务,两阶段提交系统如何撤销修改?
每个参与者对记录的临时副本进行修改。如果参与者对TC的准备消息回答“是”,参与者必须首先将临时记录值保存到其磁盘上的日志中,这样如果它崩溃并重启,它可以找到它们。如果TC决定提交,参与者必须将临时值复制到真实数据库记录中;如果TC决定中止,参与者必须丢弃临时记录。
-
可串行化与线性一致性有什么关系?
它们是来自不同社区的类似概念。两者都要求最终结果与某些串行执行相同。可串行化通常指的是涉及多个操作的整个事务。线性一致性通常指的是简单的读和写操作。还有一点是,线性一致性要求等效的串行执行与实际执行的实时顺序相匹配,而可串行化通常不要求这一点。
-
为什么在我们查看的设计中经常出现日志?
- 一个原因是日志捕获了系统为事务选择的串行顺序,这样例如所有副本以相同的顺序执行事务,或者服务器在崩溃+重启后按照与崩溃前相同的顺序考虑事务。
- 另一个原因是日志是一种高效的方式将数据写入硬盘或SSD,因为这两种媒介在顺序写入(即追加到日志)时要比随机写入快得多。、第三个原因是日志是一种方便的方式,让崩溃恢复软件看到系统在崩溃前进行到哪一步,以及最后的事务是否在日志中有完整记录,因此可以安全地重放。也就是说,日志是实现可崩溃恢复的原子事务的一种方便方式,通过预写日志(write-ahead logging)。
这篇关于Distributed Transactions Mit 6.824的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!