本文主要是介绍Mantle: A Programmable Metadata Load Balancer for the Ceph File System——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SC 2015 Paper 元数据论文阅读汇总
问题
优化Ceph的元数据局部性和负载平衡。
现有方法
提高元数据服务性能的最常见技术是在专用的元数据服务器(MDS)节点之间平衡负载 [16, 25, 26, 21, 28]。常见的方法是鼓励独立增长并减少通信,使用诸如懒惰客户端和MDS同步 [16, 18, 29, 9, 30]、inode路径/权限缓存 [4, 11, 28]、具有局部感知的/对象间事务 [21, 30, 17, 18] 和高效的查找表 [4, 30] 等技术。
尽管具有迁移元数据的机制,如锁 [21, 20]、零拷贝和两阶段提交 [21] 以及目录分区 [28, 16, 18, 25],但这些系统未能充分利用局部性。
本文方法
为了达到平衡,我们需要了解资源迁移和MDS节点处理能力的权衡。我们介绍了Mantle,这是一个基于CephFS的系统,它通过将迁移策略与机制分离来暴露这些因素,判断应该进行负载均衡还是并行(负载均衡会导致额外的性能开销)。
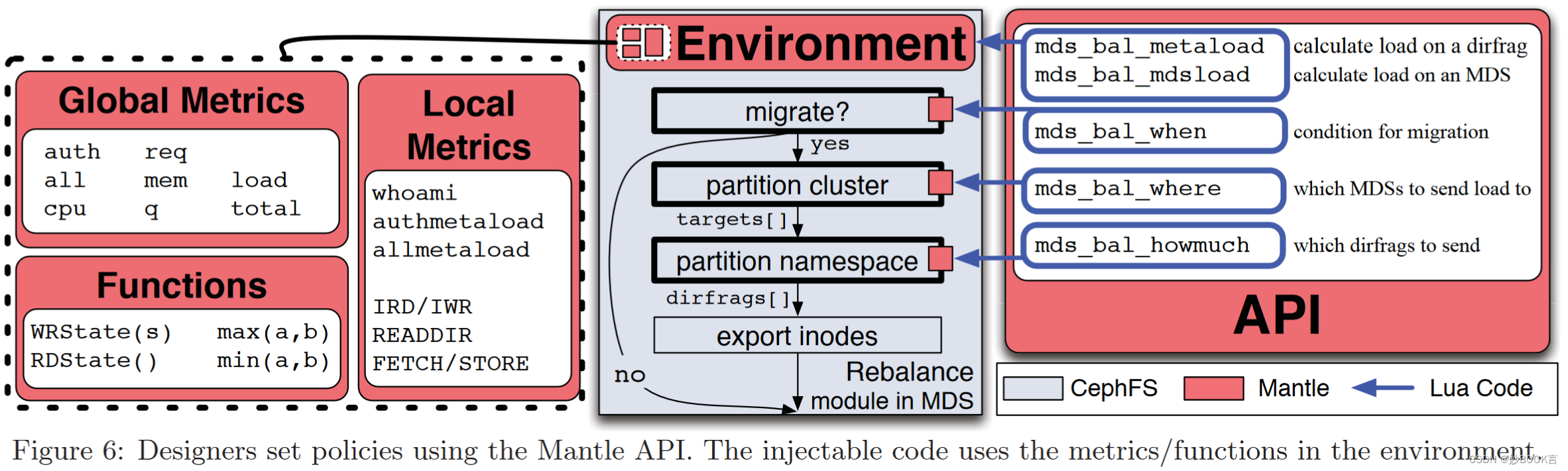
我们通过复制一种最先进的元数据平衡器的策略来展示这种方法的灵活性和透明性,并最后通过将该策略与同一系统上的其他自定义平衡器进行比较来总结。
总结
针对元数据的局部性和负载均衡问题,作者提出进行负载均衡时会导致性能下降,在调度前需要先考虑调度带来的影响。作者提出Mantle,将迁移策略和文件系统解耦。
这篇关于Mantle: A Programmable Metadata Load Balancer for the Ceph File System——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![Java实现将byte[]转换为File对象](/front/images/it_default.gif)



