本文主要是介绍BypassD: Enabling fast userspace access to shared SSDs——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ASPLOS 2024 Paper 论文阅读笔记整理
问题
现代存储设备,如Optane NVMe SSD,提供几微秒的超低延迟和每秒数千GB的高带宽,导致内核软件I/O堆栈是开销的主要来源。例如,Optane SSD可以在4𝜇s内返回4KB块,而通过标准Linux内核读取块几乎需要8𝜇s。
现有方法局限性
减少软件开销的方法主要分为两类:
-
对内核存储堆栈的优化:优化I/O调度[10,26,66],重叠异步操作[37],使用轮询代替中断[10,64]。但仍需要上下文切换才能进入和离开内核,而安全缓解措施使这些切换的成本更高[25,57]。
-
用户空间文件/存储访问:SPDK和其他[34,49,65]通过从用户空间直接访问SSD来减少延迟。但给开发带来了负担,需要更换内核块层和文件系统,并管理原子性和崩溃一致性。其次,在应用程序/用户之间安全地共享设备是一项挑战:设备不知道文件布局或权限,用户空间代码可以访问设备上的所有块。
本文工作
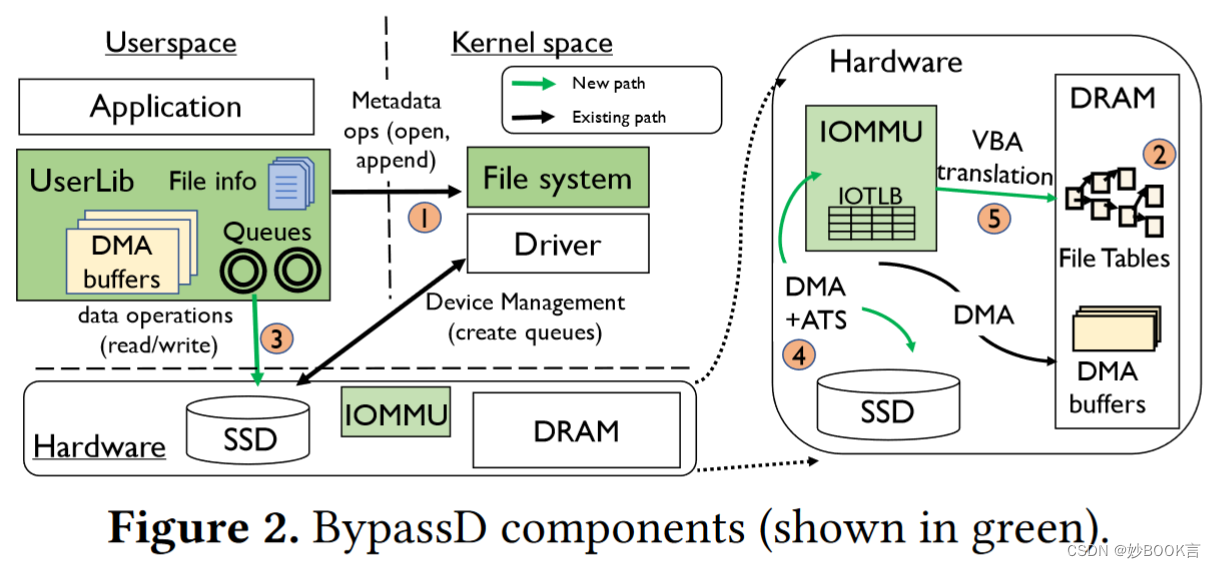
本文提出了一种新的I/O体系结构BypassD,用于快速、用户空间访问共享存储设备。
-
在应用程序地址空间中构建页表,将虚拟地址映射到文件数据位置。用户空间I/O请求使用虚拟地址访问设备,并依靠硬件进行翻译和保护。
-
扩展IOMMU硬件,SSD使用IOMMU来检查访问并检索这些映射,使现有应用程序不需要修改即可使用BypassD。
-
文件访问遵循两条路径:如打开和附加之类的元数据操作由内核文件系统处理。文件读取和写入直接从用户空间库发送到设备。在文件打开期间,内核将文件内容映射到应用程序地址空间,通过虚拟地址读/写文件数据。整个机制对应用程序是透明的。
评估表明,与标准Linux内核相比,BypassD将4KB访问的延迟减少了42%,并且执行的技术接近用户空间,如不支持设备共享的SPDK。通过消除软件开销,BypassD将实际工作负载(如WiredTiger存储引擎)的性能提高了约20%。
总结
针对现代存储设备下,访问存储设备时软件开销过高的问题。本文提出了新的I/O体系结构BypassD,用于快速、用户空间访问共享存储设备。(1)在应用程序地址空间中构建页表,将虚拟地址映射到文件数据位置。用户空间I/O请求使用虚拟地址访问设备,并依靠硬件进行翻译和保护。(2)扩展IOMMU硬件,SSD使用IOMMU来检查访问并检索这些映射,使现有应用程序不需要修改即可使用BypassD。
文件访问遵循两条路径:如打开和附加之类的元数据操作由内核文件系统处理。文件读取和写入直接从用户空间发送到设备。在文件打开期间,内核将文件内容映射到应用程序地址空间,通过虚拟地址读/写文件数据。整个机制对应用程序是透明的。
这篇关于BypassD: Enabling fast userspace access to shared SSDs——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


