本文主要是介绍【论文泛读】OCT-GAN(WWW’21),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Jayoung Kim, Jinsung Jeon, Jaehoon Lee, Jihyeon Hyeong, Noseong Park
Yonsei University
原文传送
摘要
- 表格数据的生成,为人们增加了训练数据。最先进的方法在数据不平衡分布和模式崩溃问题上还不令人满意。
- 主要贡献:
- 鉴别器有一个ODE层来提取一个隐藏的向量演化轨迹进行分类;
- 轨迹由在不同层(或时间)𝑡𝑖上提取的一系列隐藏向量表示。还训练了这些提取时间点;
- 基于轨迹的分类给鉴别器带来了重要的好处,因为不仅可以使用最后一个隐藏向量,还可以使用轨迹中包含的所有信息;
- 生成器采用一个初始ODE层将𝒛⊕𝒄转换为另一个适合生成的潜在隐藏向量𝒛‘,同时保持原语义(同态映射);
- 总共对13个数据集进行了深入的实验(一部分仅为likelihood实验),从保险欺诈检测到在线新闻文章传播预测等。评估任务包括生成假据用于似然估计、分类、回归和聚类,并且方法在许多情况下都大大优于现有的方法。
介绍
- web-based 应用大多使用表格型数据,并且许多企业系统使用关系数据库管理系统。
- 表格数据通常具有不规则分布和多峰性,基于引入Neural ODEs的想法,设计生成器和鉴别器,显著提高了效用。
- 基于node的鉴别器,执行一个基于隐藏向量进化轨迹的分类;
- 结构如图:
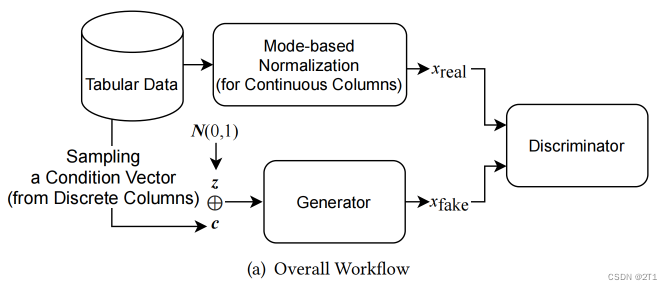
Backgrounds
- Neural Ordinary Differential Equations (NODEs)
- 在NODEs中,一个具有一组参数的神经网络f,记为 θ ( f ) \theta(f) θ(f)
- h ( t m ) = h ( t 0 ) + ∫ t 0 t m f ( h ( t ) , t ; θ f ) d t h(t_m)=h(t_0)+\int_{t_0}^{t_m}f(h(t),t;\theta_f)dt h(tm)=h(t0)+∫t0tmf(h(t),t;θf)dt, 其中 f ( h ( t ) , t ; θ f ) = d h ( t ) / d t f(h(t),t;\theta_f)=dh(t)/dt f(h(t),t;θf)=dh(t)/dt通常的神经网络中,t是离散的,但是在NODEs中t是连续的
- 依赖ODE求解器解决积分问题。文章依赖DOPRI方法,将积分转为一系列的加分,DOPRI能够动态地控制其步长。
- Conditional GAN
- 整体还是基于MLP;
- 原生GAN中,G的目的是欺骗D获得高分。但是CGAN的G需要输入的condition,D除了打分外还需要判断是否满足condition。
- Tabular Data Synthesis
- RGAN 生成连续的时间序列医疗保健记录;
- EhrGAN 使用半监督学习生成看似合理的标记记录,以增加有限的训练数据;
- PATE-GAN在不危及原始数据隐私的情况下生成合成数据;
- TableGAN利用卷积神经网络改进了表格数据的合成,以最大限度地提高标签列上的预测精度。
Main methods
数据预处理
主要考虑两类数据
- 离散型数据 D 1 , D 2 , D 3 . . . D N D D_1,D_2,D_3...D_{N_D} D1,D2,D3...DND,被转换为one-hot向量
- 连续型数据 C 1 , C 2 , . . . , C N C C_1,C_2,...,C_{N_C} C1,C2,...,CNC,使用mode-specifific normalization(和CTGAN方法一致)进行预处理
第i行的数据 r i r_i ri可以被写为 d i , 1 ⨁ d i , 2 . . . . . . ⨁ d i , N D ⨁ c i , 1 ⨁ c i , 2 . . . . . . ⨁ c i , N C d_{i,1}\bigoplus d_{i,2}......\bigoplus d_{i,N_D}\bigoplus c_{i,1}\bigoplus c_{i,2}......\bigoplus c_{i,N_C} di,1⨁di,2......⨁di,ND⨁ci,1⨁ci,2......⨁ci,NC,通过以下三个步骤将数据 r i r_i ri预处理为 x i x_i xi
-
将每个离散值 d i , 1 , d i , 2 , . . . , d i , N D d_{i,1},d_{i,2},...,d_{i,N_D} di,1,di,2,...,di,ND转换为一个one-hot向量 d o i , 1 , d o i , 2 , . . . , d o i , N D d_{oi,1},d_{oi,2},...,d_{oi,N_D} doi,1,doi,2,...,doi,ND。
-
利用变分高斯混合(VGM)模型,将每个连续列𝐶𝑗拟合到一个高斯混合,高斯混合的表示为: P r j ( c i , j ) = Σ k = 1 n j w j , k N ( c i , j ; μ j , k , σ j , k ) Pr_j(c_{i,j})=\Sigma_{k=1}^{n_j}w_{j,k}\Nu(c_{i,j};\mu_{j,k},\sigma_{j,k}) Prj(ci,j)=Σk=1njwj,kN(ci,j;μj,k,σj,k)其中, n j n_j nj为 C j C_j Cj列中的模数(即高斯分布的数)。 w j , k , μ j , k , σ j , k w_{j,k},\mu_{j,k},\sigma_{j,k} wj,k,μj,k,σj,k是 k t h k_{th} kth高斯分布的拟合权值、均值和标准差
-
对于 P r j ( k ) = w j , k N ( c i , j ; μ j , k , σ j , k ) Σ p = 1 n j w j , p N ( c i , j ; μ j , p , σ j , p ) Pr_j(k)=\frac{w_{j,k}\Nu(c_{i,j};\mu_{j,k},\sigma_{j,k})}{\Sigma_{p=1}^{n_j}w_{j,p}\Nu(c_{i,j};\mu_{j,p},\sigma_{j,p})} Prj(k)=Σp=1njwj,pN(ci,j;μj,p,σj,p)wj,kN(ci,j;μj,k,σj,k),以合适的模式k对 c i , j c_{i,j} ci,j采样,然后将模式k中的 c i , j c_{i,j} ci,j及其拟合的标准差进行归一化,保存归一化值 α i , j \alpha_{i,j} αi,j和模式信息 β i , j \beta_{i,j} βi,j。
-
最后, r i r_i ri转化为 x i x_i xi,其表示为: x i = α i , 1 ⨁ β i , 1 ⨁ . . . ⨁ α i , N c ⨁ β i , N c ⨁ d o i , 1 ⨁ . . . ⨁ d o i , N c x_i=\alpha_{i,1}\bigoplus\beta_{i,1}\bigoplus...\bigoplus\alpha_{i,N_c}\bigoplus\beta_{i,N_c}\bigoplus d_{oi,1}\bigoplus...\bigoplus d_{oi,N_c} xi=αi,1⨁βi,1⨁...⨁αi,Nc⨁βi,Nc⨁doi,1⨁...⨁doi,Nc
在 x i x_i xi中包含 r i r_i ri基于模式的信息,GAN的G和D可以使用 x i x_i xi来分辨模式。同时,使用高斯混合的拟合参数, x i x_i xi可以很容易地更改为 r i r_i ri
鉴别器 Discriminator
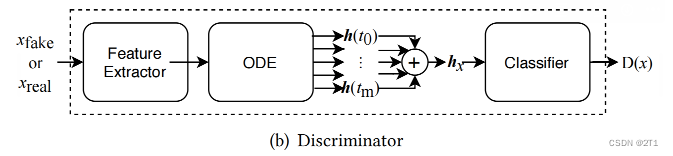
基于ODE的鉴别器,并在预测输入样本 x ( t ) x(t) x(t)的真否同时,考虑了 h h h的轨迹。
- h ( 0 ) = D r o p ( L e a k y ( F C 2 ( D r o p ( L e a k y ( F C 1 ( x ) ) ) ) ) ) h(0)=Drop(Leaky(FC2(Drop(Leaky(FC1(x)))))) h(0)=Drop(Leaky(FC2(Drop(Leaky(FC1(x))))))
- h ( t 1 ) = h ( 0 ) + ∫ 0 t 1 f ( h ( 0 ) , t ; θ f ) d t h(t_1)=h(0)+\intop_0^{t_1}f(h(0),t;\theta_f)dt h(t1)=h(0)+∫0t1f(h(0),t;θf)dt
- h ( t 2 ) = h ( t 1 ) + ∫ t 1 t 2 f ( h ( t 1 ) , t ; θ f ) d t h(t_2)=h(t_1)+\intop_{t_1}^{t_2}f(h(t_1),t;\theta_f)dt h(t2)=h(t1)+∫t1t2f(h(t1),t;θf)dt
- h ( t m ) = h ( t m − 1 ) + ∫ t m − 1 t m f ( h ( t m − 1 ) , t ; θ f ) d t h(t_m)=h(t_{m-1})+\intop_{t_{m-1}}^{t_{m}}f(h(t_{m-1}),t;\theta_f)dt h(tm)=h(tm−1)+∫tm−1tmf(h(tm−1),t;θf)dt
-
h x = h ( 0 ) ⨁ h ( t 1 ) ⨁ h ( t 2 ) ⨁ . . . ⨁ h ( t m ) h_x=h(0)\bigoplus h(t_1)\bigoplus h(t_2)\bigoplus ...\bigoplus h(t_m) hx=h(0)⨁h(t1)⨁h(t2)⨁...⨁h(tm)
-
D ( x ) = F C 5 ( L e a k y ( F C 4 ( L e a k y ( F C 3 ( h x ) ) ) ) ) D(x)=FC5(Leaky(FC4(Leaky(FC3(h_x))))) D(x)=FC5(Leaky(FC4(Leaky(FC3(hx)))))
其中,m是超参数,(3)到(6)共享相同的参数 θ f \theta_f θf,构成单一的ODE系统,定义 a t ( t ) = d L d t a_t(t) = \frac{dL}{dt} at(t)=dtdL
损失Loss的计算
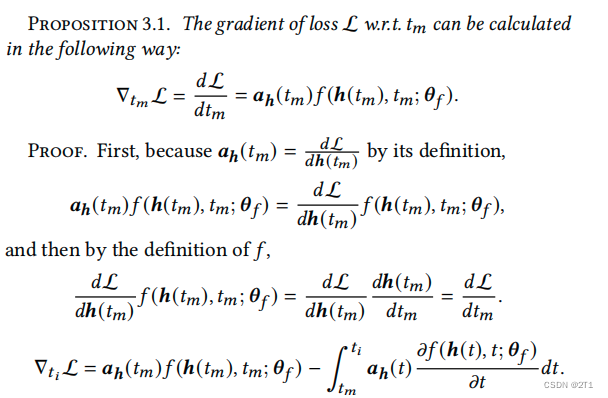
综上,只需要保存一个伴随的数位 a h ( t m ) a_h(t_m) ah(tm),并使用两个函数𝑓和 a h ( t ) a_h(t) ah(t)计算∇𝑡𝑖L
h ( t m ) h(t_m) h(tm)是最后隐藏向量。使用 h ( t m ) h(t_m) h(tm)和整个轨迹来进行分类。
- 通过寻找关键的时间点来区分轨迹,进一步提高了该方法的有效性;
- 在通常的神经网络中,训练𝑡𝑖是不可能的,因为它们的层结构是离散的,利用ODE的性质,可以选择最佳的 t i t_i ti节点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E4Cje7o3-1666617360117)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/41452542-71db-40c9-ac43-51cbfd3fdbca/Untitled.png)]](https://img-blog.csdnimg.cn/d4cb35a08d4d4f099687dccbf5721014.png)
条件生成器 Conditional Generator
OCT-GAN是一个条件GAN,其生成器读取一个噪声向量和一个条件向量来生成一个假样本。
给定一个初始输入𝒑(0)=𝒛⊕𝒄,将其送入一个ODE层,以转换为另一个潜在向量。
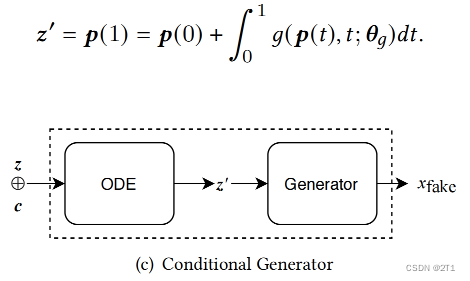
ODE是一个同态映射。可以利用这个特性来设计一个语义上可靠的映射。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3mwpI7Tu-1666617360118)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/c877d9a5-b0d6-4865-84b1-e5a553100a2c/Untitled.png)]](https://img-blog.csdnimg.cn/b5417a5b1c5a47548358dfe54bd4ceea.png)
-
ODE层在初始输入分布和真实数据分布之间找到了一个平衡分布
-
生成了真实的假样本
特别地,加入ODE的变换使合成样本的插值平滑。
即,给定两个相似的初始输入,生成器生成两个相似的合成样本(如格隆沃尔-贝尔曼不等式所证明的)——实验部分展示了这些平滑的插值。
训练算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3n02RHqg-1666617360118)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/24677b79-0aaa-4e2c-992e-80c5b4a511b7/Untitled.png)]](https://img-blog.csdnimg.cn/859bd62b6dc842cf83d71c4938841c4f.png)
实验
仿真数据的 likelihood fitness
-
首先模拟数据集:
- 收集了各种预先训练过的贝叶斯网络和高斯网络;
- 使用预训练模型生成 T t r a i n T_{train} Ttrain和 T t e s t T_{test} Ttest
-
评估方法:使用模拟数据的好处是可以评估对于给定预训练模型S的合成可能性。
- 用 T t r a i n T_{train} Ttrain训练包含OCT-GAN的生成模型;
- 从每个训练模型生成的合成数据;记F为仿真数据
- 测量F给定S的可能性 P r ( F ∣ S ) Pr(F|S) Pr(F∣S)
- 从头开始用F训练模型S’
- 测量 P r ( T t e s t ∣ S ′ ) Pr(T_{test}|S') Pr(Ttest∣S′)
两种可能性估计应该足够好, P r ( T t e s t ∣ S ′ ) Pr(T_{test}|S') Pr(Ttest∣S′)的低值表示F包含模式崩溃等情况。
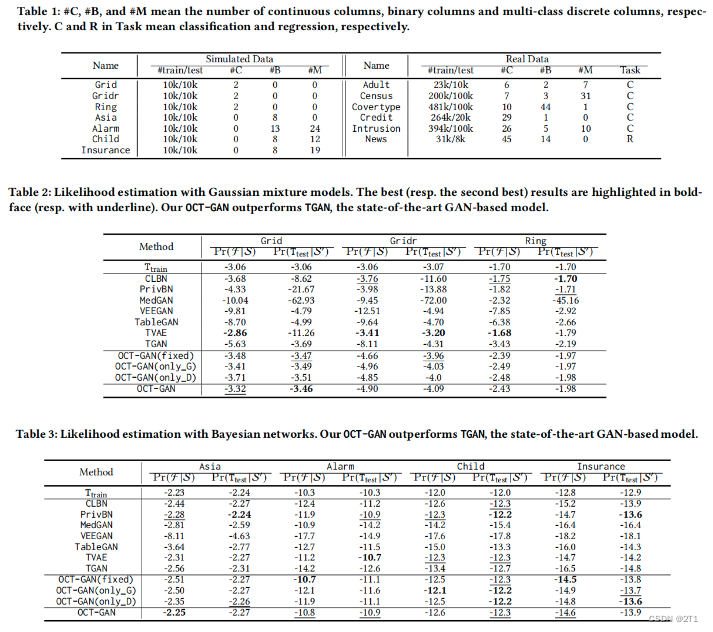
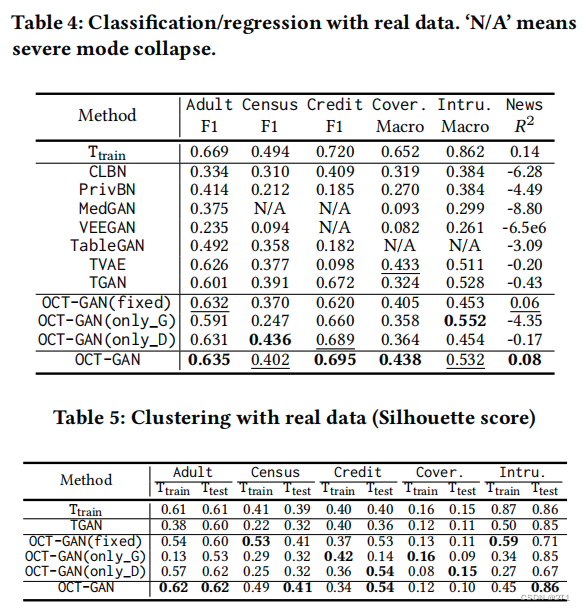
在表2和表3中,包含了所有的似然估计结果。CLBN和PrivBN的性能出现了波动。CLBN和PrivBN在Ring和Asia中分别表现较好,而PrivBN在Grid和Gridr中表现较差。TVAE在许多情况下对 P r ( F ∣ S ) Pr(F|S) Pr(F∣S)表现出良好的性能,但在Grid和Insurance中对 P r ( T t e s t ∣ S ′ ) Pr(T_{test}|S') Pr(Ttest∣S′)的性能相对较差,这意味着模式崩溃。同时,TVAE对Grid也表现出了很好的性能。总而言之,TVAE在这些实验中表现出了reasonable performance。在除OCT-GAN外的许多GAN模型中,TGAN和TableGAN表现出合理的性能,其他GAN在许多情况下不如它们。例如Insurance数据集的 P r ( T t e s t ∣ S ′ ) Pr(T_{test}|S') Pr(Ttest∣S′) , -14.3 for TableGAN,-14.8 for TGAN -18.1 for VEEGAN。(However, all these models are significantly outperformed by our proposed OCT-GAN. In all cases, OCT-GAN is better than TGAN, the state-of-the-art GAN model.)
真实数据的分类任务
数据集:Adult, Census, Covertype, Credit, Intrusion
Adult: 从美国1994年人口普查调查中提取的不同人口统计信息,预测了两类高收入(>5万美元)和低收入(≤5万美元)收入
Census: 与Adult相似,具有不同列
Covertype: 从制图变量中预测森林覆盖类型,并收集自科罗拉多州北部的罗斯福国家森林
Credit: 用于信用卡欺诈检测,于2013年9月从欧洲持卡人处收集
Intrusion: 被应用于国际知识发现和数据挖掘竞赛中,其中包含了许多网络入侵检测样本
Adult Census Credit 二元分类,而其他是多分类
如图4所示,除了OCT-GAN外的各种方法显示出不合理的准确性。
-
评估方法:
1)首先训练各种生成模型,包括OCT-GAN
2)用训练的模型生成仿真数据F
3)用假数据训练Adaboost、DecisionTree and MLP
4)test with T t e s t T_{test} Ttest
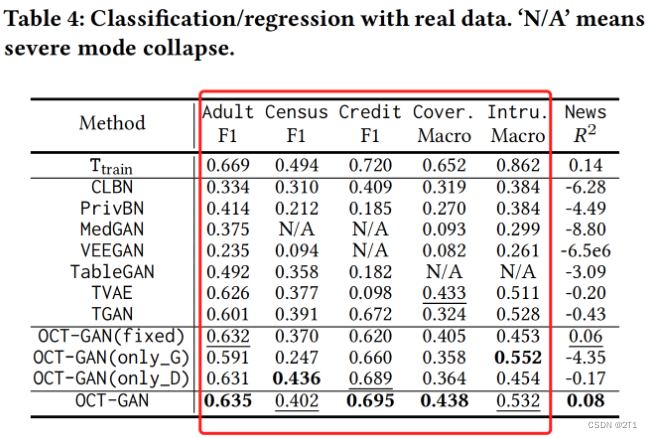
除TGAN和OCT-GAN外,许多GAN模型在许多情况下都显示出较低的得分。许多GAN模型在许多情况下都显示出较低的得分。在Census中,VEEGAN的F-1得分为0.094。
回归实验
数据集:News(UCI **Online News Popularity Data Set)**它包含了从在线新闻文章中提取的许多特征来预测社交网络中的分享数量,例如,推文、转发等等。很好地展示了该方法在基于web的应用程序中的有效性
使用线性回归和MLP作为基础回归模型,并使用𝑅2作为评价度量
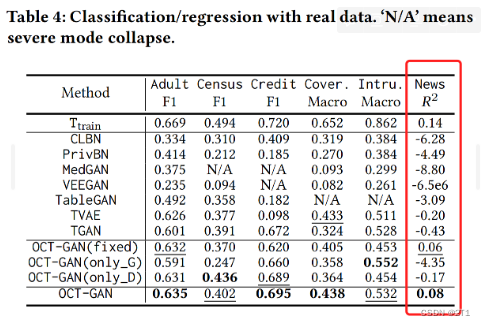
除OCT-GAN外,所有方法的精度都不合理。用 T t r a i n T_{train} Ttrain训练的原始模型显示了一个𝑅2分数为0.14,而OCT-GAN显示了一个接近它的分数。只有OCT-GAN 和原来标有 T t r a i n T_{train} Ttrain标记的模型则显示出正分。
聚类实验
使用了5个分类实验的数据集;
K = ∣ C ∣ , ∣ 2 C ∣ , ∣ 3 C ∣ K={|C|,|2C|,|3C|} K=∣C∣,∣2C∣,∣3C∣, C C C是一组类标签,对假数据 F F F运行 K − M e a n s + + K-Means++ K−Means++,选择一个得到最高的剪影轮廓得分的𝐾值。通过假数据 F F F的质心,计算应用不同GAN的 T t r a i n T_{train} Ttrain和 T t e s t T_{test} Ttest的Silhouette score
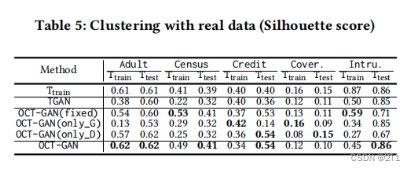
OCT-GAN在几乎所有情况下都优于TGAN。
噪声向量插值
为了进一步展示基于ode的转换在生成器中的有效性,在Adult中可视化了几个插值结果。选择两个噪声向量𝒛1,𝒛2,并通过𝑒𝒛1+(1−𝑒)𝒛2对多个中间向量进行插值。0<𝑒<1
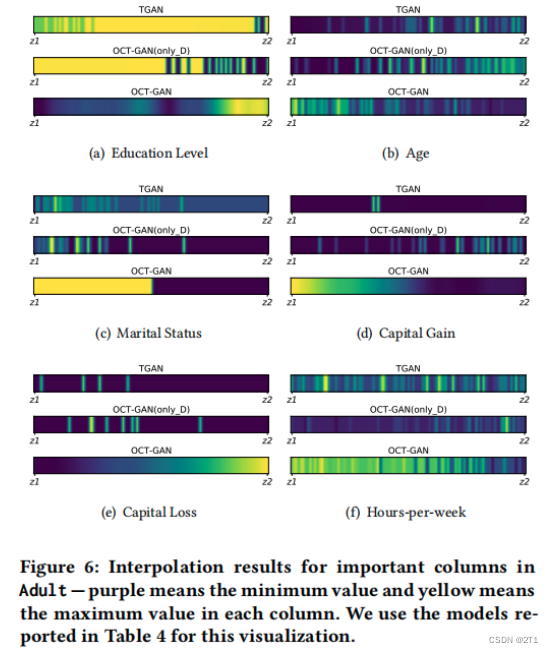
如图,TGAN和OCT-GAN(only_D)表现出相似的插值模式,而OCT-GAN可以以平滑的方式进行插值。
消融实验
- 在OCT-GAN(fixed),不训练 t i t_i ti而将其设置为等间距的结点
- 只向生成器添加ODE层,即 D ( x ) = F C 5 ( l e a k y ( F C 4 ( l e a k y ( F C 3 ( h ( 0 ) ) ) ) ) ) D(x)=FC5(leaky(FC4(leaky(FC3(h(0)))))) D(x)=FC5(leaky(FC4(leaky(FC3(h(0))))))
- 只向鉴别器增加ODE层,即直接 z ⨁ c z\bigoplus c z⨁c输入生成器
在表2和表3中,这些消融研究模型令人惊讶地显示了比完整模型OCT-GAN更好的似然估计
在Adult数据上,OCT-GAN(only_G)得分比其他模型要低得多。由此可得,在Adult数据上,鉴别器中的ODE层起着关键作用。
结论
一般来说,简单的模型,如PrivBN,TVAE和消融研究模型,显示出更好的似然估计,而复杂的模型显示出更好的机器学习任务分数;In real-world environments, however, we think that task-specific data utility is more important than likelihood. Therefore, OCT-GAN can benefit many applications.
所有的方法都没有显示出接近于标记为 T t r a i n T_{train} Ttrain的原始模型的分数,这说明了数据合成的难度。它们都是多类分类数据集。作者认为,对于复杂的机器学习任务,数据合成的质量(效用)还有一个提高的空间。
这篇关于【论文泛读】OCT-GAN(WWW’21)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

