本文主要是介绍Boosting Cache Performance by Access Time Measurements——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TOC 2023 Paper 论文阅读笔记整理
问题
大多数现代系统利用缓存来减少平均数据访问时间并优化其性能。当缓存未命中的访问时间不同时,最大化缓存命中率与最小化平均访问时间不同。例如:系统使用多种不同存储介质时,不同存储介质访问时间不同;系统使用NUMA架构时,不同处理器单元访问时间不同。现有的策略隐含地假设统一的访问时间,但在存储、web搜索和DNS解析等领域,访问时间是可变的。
本文方法
本文测量了各种项目的访问时间,并利用访问时间的变化作为缓存算法的额外信号,引入了自适应访问时间感知缓存策略。
-
对TinyLFU进行优化,提出开销感知TinyLFU(CATinyLFU)。对LRU进行优化,提出开销和最近性感知(CRA)。
-
CATinyLFU中感知开销的方法为,测量缓存命中(ht)和未命中(mt)的访问时间。在缓存驱逐时额外考虑访问时间,缓存驱逐项1导致增加时间 T1=访问频率1*(mt1-ht1),缓存进入项2导致减少时间 T2=访问频率2*(mt2-ht2),若 T2>T1,即使项2的访问频率小于项1,也可以将其纳入缓存,从而降低整体平均访问时间。
-
CRA中,因为LRU不提供显示的访问频率预测,采用衰变函数捕捉最近性,△e表示mt-ht。
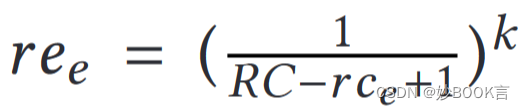
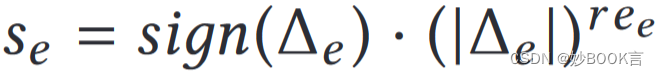
实验表明,本文的自适应算法在存储工作负载中的平均访问时间减少了46%,在网络搜索中的平均访问时间减少了16%,总的平均访问时间缩短了8.4%。
总结
针对缓存策略的优化,现有方法不会考虑不同环境下未命中的访问时间,最大化缓存命中率不一定能最小化平均访问时间。本文测量了缓存命中和未命中的访问时间,由此设计访问时间感知缓存策略,对TinyLFU和LRU进行优化,允许访问频率低但未命中访问时间高的项替代频率高但未命中访问时间低的项,实现降低整体平均访问时间。
这篇关于Boosting Cache Performance by Access Time Measurements——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





