boosting专题

【机器学习】集成学习的基本概念、Bagging和Boosting的区别以及集成学习方法在python中的运用(含python代码)
引言 集成学习是一种机器学习方法,它通过结合多个基本模型(通常称为“弱学习器”)来构建一个更加强大或更可靠的模型(“强学习器”) 文章目录 引言一、集成学习1.1 集成学习的核心思想1.2 常见的集成学习方法1.2.1 Bagging(装袋)1.2.2 Boosting(提升)1.2.3 Stacking(堆叠) 1.3 集成学习的优势1.4 集成学习的挑战1.5 总结 二、Bag

机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine)
机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine) LightGBM 中文文档 https://lightgbm.apachecn.org/ https://zhuanlan.zhihu.com/p/366952043

基于Python的机器学习系列(18):梯度提升分类(Gradient Boosting Classification)
简介 梯度提升(Gradient Boosting)是一种集成学习方法,通过逐步添加新的预测器来改进模型。在回归问题中,我们使用梯度来最小化残差。在分类问题中,我们可以利用梯度提升来进行二分类或多分类任务。与回归不同,分类问题需要使用如softmax这样的概率模型来处理类别标签。 梯度提升分类的工作原理 梯度提升分类的基本步骤与回归类似,但在分类任务中,我们使

boosting,Adaboost,Bootstrap和Bagging的含义和区别
弱分类器:分类效果差,只是比随机猜测好一点。 强分类器:具有较高的识别率,较好的分类效果。(在百度百科中有提到要能在多项式时间内完成学习) 弱和强更大意义上是相对而言的,并没有严格的限定。比如准确率低于多少就是弱分类器,高于多少是强分类器,因具体问题而定。 1988年,有学者提出是否可以通过一些弱分类器来实现强分类器的分类效果。基于这个问题,之后两三年陆续的有早期的boosting算法

Boosting和AdaBoost的可视化的清晰的解释
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Maël Fabien 编译:ronghuaiyang 前戏 可视化的方法,清楚的解释了Boosting和AdaBoost。 最近,在Kaggle竞赛和其他预测分析任务中,boosting技术正在兴起。我将尽可能清楚地解释boost和AdaBoost的概念。 在本文中,我们将讨论: 快速回顾baggingbagging的限制

Boosting和Bagging: 如何开发一个鲁棒的机器学习算法
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Ben Rogojan 编译:ronghuaiyang 导读 机器学习和数据科学需要的不仅仅是将数据放入python库中并利用得到的结果。数据科学家需要真正理解数据和数据背后的过程,才能实现一个成功的系统。这篇文章从Bootstraping开始介绍,让你听懂什么是Boosting,什么是Bagging。 机器学习和数据科学
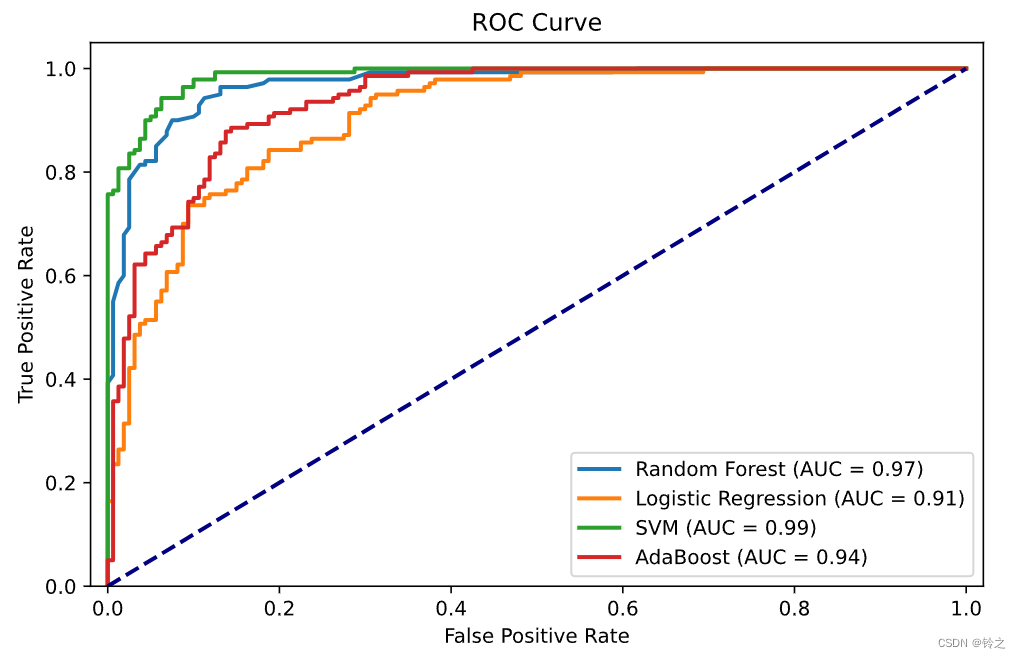
Boosting原理代码实现
1.提升方法是将弱学习算法提升为强学习算法的统计学习方法。在分类学习中,提升方法通过反复修改训练数据的权值分布,构建一系列基本分类器(弱分类器),并将这些基本分类器线性组合,构成一个强分类器。代表性的提升方法是AdaBoost算法。 AdaBoost模型是弱分类器的线性组合: f ( x ) = ∑ m = 1 M α m G m ( x ) f(x)=\sum_{m=1}^{M} \alp

结合Boosting理论与深度ResNet:ICML2018论文代码详解与实现
代码见:JordanAsh/boostresnet: A PyTorch implementation of BoostResNet 原始论文:Huang F, Ash J, Langford J, et al. Learning deep resnet blocks sequentially using boosting theory[C]//International Conference

集成学习方法:Bagging与Boosting的应用与优势
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119@qq.com] 📱个人微信:15279484656 🌐个人导航网站:www.forff.top 💡座右铭:总有人要赢。为什么不能是我呢? 专栏导航: 码农阿豪系列专栏导航 面试专栏:收集了java相关高频面试题,面试实战
bootstrap, boosting, bagging的区别和联系
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。 (2) 根据抽出的样本计算给定的统计量T。
Boosting Bagging Stacking整理
一. 知识点 Bias-Variance Tradeoff bias-variance是分析boosting和bagging的一个重要角度,首先讲解下Bias-Variance Tradeoff. 假设training/test数据集服从相似的分布,即 yi=f(xi)+ϵi, y i = f ( x i ) + ϵ i , y_i = f(x_i) + \epsilo
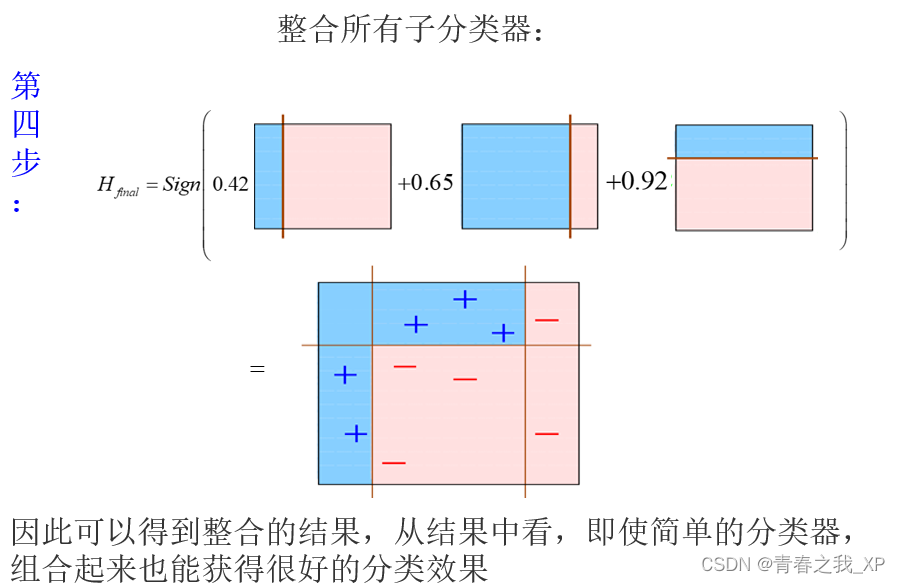
【机器学习系列】深入理解集成学习:从Bagging到Boosting
目录 一、集成方法的一般思想 二、集成方法的基本原理 三、构建集成分类器的方法 常见的有装袋(Bagging)和提升(Boosting)两种方法 方法1 :装袋(Bagging) Bagging原理如下图: 方法2 :提升(Boosting) Boosting工作原理 目前已有几个Boosting算法,其区别在于: 四、随机森林(Bagging集成方法的一种) (一)随

【量化课堂】Boosting 介绍和 Python 实现【记录我的学习】
一面兴奋进来、看到公式到结束一面懵逼出去、还没理解完全部,加油咯。。。 引言:Boosting 是一种集成算法,经常使用 决策树(decision tree) 作为基础分类器,有些 Boosting 模型也用逻辑回归(logistic regression),SVM 等方法做分类器的,倘若读者初学机器学习,学习这部分时建议补完决策树的相关知识,帮助理解。本文主要用 Boosting 的始祖算法
bootstrap, boosting, bagging
介绍boosting算法的资源: 视频讲义,介绍boosting算法,主要介绍AdaBoosing http://videolectures.net/mlss05us_schapire_b/在这个网站的资源项里列出了对于boosting算法来源介绍的几篇文章,可以下载: http://www.boosting.org/tutorials一个博客介绍了许多视觉中常用算法,作者的实验和理解,这里附录
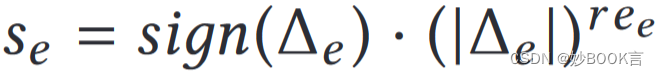
Boosting Cache Performance by Access Time Measurements——论文泛读
TOC 2023 Paper 论文阅读笔记整理 问题 大多数现代系统利用缓存来减少平均数据访问时间并优化其性能。当缓存未命中的访问时间不同时,最大化缓存命中率与最小化平均访问时间不同。例如:系统使用多种不同存储介质时,不同存储介质访问时间不同;系统使用NUMA架构时,不同处理器单元访问时间不同。现有的策略隐含地假设统一的访问时间,但在存储、web搜索和DNS解析等领域,访问时间是可变的。 本

《Boosting Object Detection with Zero-Shot Day-Night Domain Adaptation》2024CVPR
域不变特征:是指在不同的数据域或环境下,特征能够保持不变或具有一定程度的鲁棒性。实现域不变特征可以在许多计算机视觉和机器学习任务中具有重要的作用,特别是在涉及跨域或跨环境的应用场景中。 以下是一些常用的实施域不变特征的方法: 1. 数据归一化:通过将数据进行归一化处理,将其缩放到一个统一的范围内。常见的归一化方法包括零均值归一化(Zero-mean normalization)和单位方差归一

Boosting算法揭秘:从原理到scikit-learn实战
Boosting算法揭秘:从原理到scikit-learn实战 在机器学习的江湖中,Boosting算法以其强大的预测能力和独特的训练方式占据了一席之地。与Bagging算法并行训练的理念不同,Boosting算法更注重模型的串行迭代和错误修正。本文将从Boosting算法的基本原理出发,逐步深入到scikit-learn中的Boosting实现,并提供一些技术细节和最佳实践的见解。 1. B
【机器学习】集成方法---Boosting之AdaBoost
一、Boosting的介绍 1.1 集成学习的概念 1.1.1集成学习的定义 集成学习是一种通过组合多个学习器来完成学习任务的机器学习方法。它通过将多个单一模型(也称为“基学习器”或“弱学习器”)的输出结果进行集成,以获得比单一模型更好的泛化性能和鲁棒性。 1.1.2 集成学习的基本思想 集成学习的基本思想可以概括为“三个臭皮匠顶个诸葛亮”。通过将多个简单模型(弱学习器)的预测

集成方法(Boosting:以AdaBoost为例)原理以及实现
集成方法(boosting又称为提升方法) 提升方法重要概念 1.思路:三个臭皮匠顶个诸葛亮2.重要概念: PAC:(Probably approximately correct):概率近似正确 强可学习:PAC中,面对假设模型,如果存在一个多项式的学习算法能够学习它,且正确率很高,那么这个概念就是强可学习 弱可学习:PAC中,面对假设模型,如果存在一个多项式的学习算法能够学习它,且正确
[机器学习] 第八章 集成学习 1.Boosting(GBDT Adaboost Xgboost) Bagging(随机森林)
https://www.cnblogs.com/techflow/p/13445042.html 文章目录 一、Boosting ↓bias1. GBDT回归(划分结点:mse)1.1 Regression Decision Tree:回归树1.2 Boosting Decision Tree:提升树算法1.3 Shrinkage (避免GBDT过拟合,学习率) 2. GBDT分类(划分结点
![[机器学习必知必会]集成学习Boosting、Boostrap和Bagging算法介绍](https://img-blog.csdn.net/20180604142302143)
[机器学习必知必会]集成学习Boosting、Boostrap和Bagging算法介绍
集成学习算法简介: (1)原理: 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。 集成学习的主要思想是利用一定的手段学习出多个分类器,而且这多个分类器要求是弱分
【机器学习】集成学习 Bagging Boosting 综述
集成学习 Ensemble learning: 主要包括三种形似的集成方式【Bagging、Boosting、Stacking】 指将若干弱分类器 (或基(础)分类器) 组合之后产生一个强分类器 (可以是不同类型的分类器) ·并不算是一种分类器,而是一种分类器的结合方法; ·一个集成分类器的性能会好于单个分类器; 1
Boosting、Bagging和Stacking知识点整理
全是坑,嘤嘤哭泣= = 简述下Boosting的工作原理 Boosting主要干两件事:调整训练样本分布,使先前训练错的样本在后续能够获得更多关注 集成基学习数目 Boosting主要关注降低偏差(即提高拟合能力)描述下Adaboost和权值更新公式 Adaboost算法是“模型为加法模型、损失函数为指数函数、学习算法为前向分布算法”时的二类分类学习方法。 Adaboost有两项内容:

DataWhale集成学习【中】:(三)Boosting
这篇博文是 DataWhale集成学习【中】 的第二部分,主要是介绍Boosting的思想原理以及其衍生的各种算法参考资料为DataWhale开源项目:机器学习集成学习与模型融合(基于python)和scikit-learn官网学习交流欢迎联系 obito0401@163.com 文章目录 Boosting原理分类AdaBoost原理方法示例 前向分步算法梯度提升决策树(GBDT)XGBo

集成学习boosting和bagging
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。这对“弱学习器”尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。弱学习器指泛化性能略优于随机猜测的学习器,例如在二分类问题上,精度略高于50%的分类器。个体学习器应该“好而不同”,即个体学习器性能不能太坏,且个体学习器之间要存在差异性。根据个体学习器的生成方式,目前的集成学习方