本文主要是介绍研究生论文阅读方法(包含泛读、略读、精读、深读),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
已经好久没有更新博客了,前段时间忙着复现高翔的博客教程(一起来做RGBD),SLAM十四讲也已经看完了一遍(新手还是有点懵)。现在开始看论文,突然没有了方向感。导师在实验室论坛上的论文阅读要求给了我很大的启发,分享给各位,希望大家研究生学习都能充满方向感!
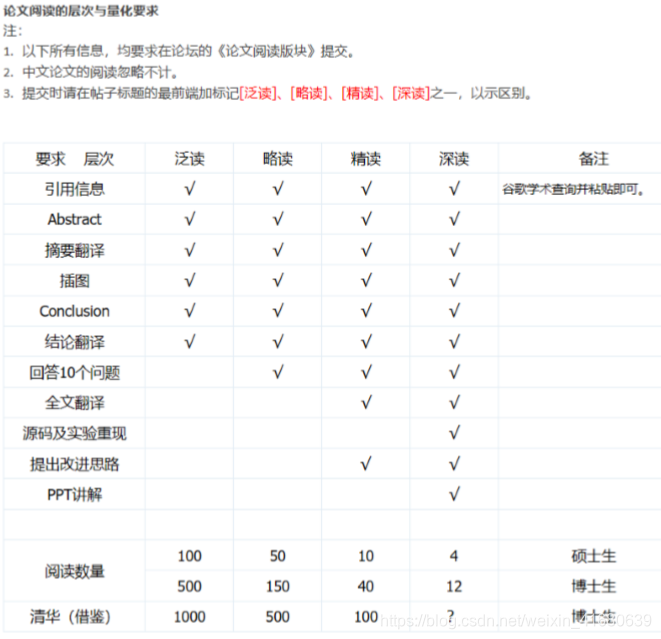
对于其中的十个问题,主要是

文献阅读按照先综述后细化的步骤展开~
这篇关于研究生论文阅读方法(包含泛读、略读、精读、深读)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






