byte专题
![Java实现将byte[]转换为File对象](/front/images/it_default.jpg)
Java实现将byte[]转换为File对象
《Java实现将byte[]转换为File对象》这篇文章将通过一个简单的例子为大家演示Java如何实现byte[]转换为File对象,并将其上传到外部服务器,感兴趣的小伙伴可以跟随小编一起学习一下... 目录前言1. 问题背景2. 环境准备3. 实现步骤3.1 从 URL 获取图片字节数据3.2 将字节数组
自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词

Python基础知识:bit(比特)与Byte(字节)的区别与关系
1.bit:位 (小写b) 也称比特 是英文 binary digit的缩写 二进制数系统中,每个0或1就是一个位(bit) 位是数据存储(计算机中信息)的最小单位 计算机中的CPU位数指的是CPU一次能处理的最大位数。例如32位计算机的CPU一次最多能处理32位数据 2.Byte:字节(大写B) 8bit就称为一个字节(Byte), 1Byte=8bit 记为Byte或B,是计算机中信息的
![关于数字存储和byte[]数组的一些心得](https://i-blog.csdnimg.cn/direct/f14fb6d2546a424b9b1608bb2c6a159c.png)
关于数字存储和byte[]数组的一些心得
前言 最近做项目,发现一些规律,比如数字的存储和字符串的存储,先说数字吧,最常见的整数,就涉及反码和补码,根据这些规则,甚至我们自己也能造一种数据存储结构,比如1个字节8bit,在byte里面就是一半正数一半负数,但是在二进制却是我们不理解的一种方式。计算机存储都是字节存储,字符实际上也是字节,那么byte[]数组在很多时候就很关键,比如grpc算法那一期:grpc Java demo与Spri

解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128
1.问题描述:一个在Django框架下使用Python编写的定时更新项目,在Windows系统下测试无误,在Linux系统下测试,报如下错误: ascii codec can't decode byte 0xe8 in position 0:ordinal not in range(128) 2.原因分析:字符问题。在Windows系统转Linux系统时,字符问题很容易出现。 3.解决办
_csv.Error: line contains NULL byte
_csv.Error: line contains NULL byte 原因是表格保存时扩展名为 xls,而我们将其改为csv文件通常是重命名; 解决方法只需把它另存为 csv 文件。 posted @ 2017-12-19 16:53 酸奶加绿茶 阅读( ...) 评论( ...) 编辑 收藏

为什么在java中(byte)128输出是-128?
因为java中的自动转型,因此System.out.println((byte)128) 输出为-128。 在java中默认整型是int类型,int类型是4字节,32位。而byte类型是1字节,8位 而java中的二进制都是采用补码形式存储:⑴一个数为正,则它的原码、反码、补码相同⑵一个数为负,则符号位为1,其余各位是对原码取反,然后整个数加1 就int类型的128而言,: 原码为:000

net core中byte数组如何高效转换为16进制字符串
在 .NET Core 中,如何把 byte[] 转换为 16 进制字符串?你能想到哪些方法?什么方式性能最好?今天和大家分享几种转换方式。 往往在处理字符串性能问题时,首先应该想到的是怎么想办法减少内存分配,怎么优化字符串构建。 下面就通过递进的方式介绍几种实现方式。 1. 使用 StringBuilder 在需要做大量字符串拼接的场景中,我们首先就会想到StringBuilder,相比
int和byte[]之间的转换
有时候和C的程序通信的时候,我们在封装协议时,可能需要将Java里的int值,转换成byte[]后用socket发送。所以我们需要将32位的int值放到4字节的byte[]里。 /** * int值转成4字节的byte数组 * @param num * @return */ public static byte[] int2byteArray(int num) { byte[] res
Java中字符和byte数组之间的相互转换
Java与其他语言编写的程序进行TCP/IP Socket通讯时,通讯内容一般都转换成byte数组型。 1.将字符转换成byte数组 String str = “傻逼”; byte[] sb = str.getBytes(); 2.将byte数组转换成字符 byte[] b={(byte)0xB8,(byte)0xDF,(byte)0xCB,(byte)0xD9}; String st
[转]Java中byte数组转换int时为何与0xff进行与运算
在剖析该问题前请看如下代码 public static String bytes2HexString(byte[] b) { String ret = ""; for (int i = 0; i < b.length; i++) { String hex = Integer.toHexString(b[ i ] & 0xFF); if (hex.length() == 1) {
golang string和[]byte零内存拷贝互转换
好久以前忘记在哪看到的了,最近要用到想了好久才想起来怎么写,记录以下,免得后面要用又要想很久 func bytes2Str(slice []byte) string {return *(*string)(unsafe.Pointer(&slice)
【转】bit、Byte、bps、Bps、pps、Gbps的单位详细说明及换算
百科 比特率 bps(bits per second),即比特率、比特/秒、位/秒、每秒传送位数,数据传输速率的常用单位。详见Mbps。 比特(bit)是信息技术中的最小单位。文件大小(例如文本或图像文件)通常以字节(Byte)为单位。一字节对应八比特。在数据传输中,数据通常是串行传输的,即一个比特接一个比特地传输。数据速率的单位是比特每秒(bps),含义是每秒串行通过的位数。 Bps (
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 167
在用urllib.request库的时候一部小心就会碰到 url = "http://money.163.com/special/pinglun/"data_byte = urllib.request.urlopen(url).read()data = data_byte.decode('UTF-8')print(data) 报错: UnicodeDecodeError: 'utf-
面试题:byte b = 130;有没有问题?
byte b = 130;有没有问题?,(有)。如果我想让赋值正确,可以怎么做(强制类型转换,截取最低一个字节)?结果是多少呢? 源代码: class Test {public static void main(String[] args) {// 因为byte的范围是:-128到127。(-2^7--2^7-1)// 而130不在此范围内,所以报错。// byte b = 130;//
(VB.Net)Integer转 Byte数组
1、Integer转单个字节 Public Function iByte(ByVal i As Integer) As ByteDim b() As Byte = BitConverter.GetBytes(i)Return b(0)End Function 2、Integer转双字节 '低字节在前,高字节在后Public Function iByte2(ByVal i As Integ
byte short int long
byte1个字节 -128to127 short 两个字节 -32768to32767 int 四个字节 -2147483648to2147483647 long 八个字节 。。 一个字节8位, 2的8次方就是256一个字节的数
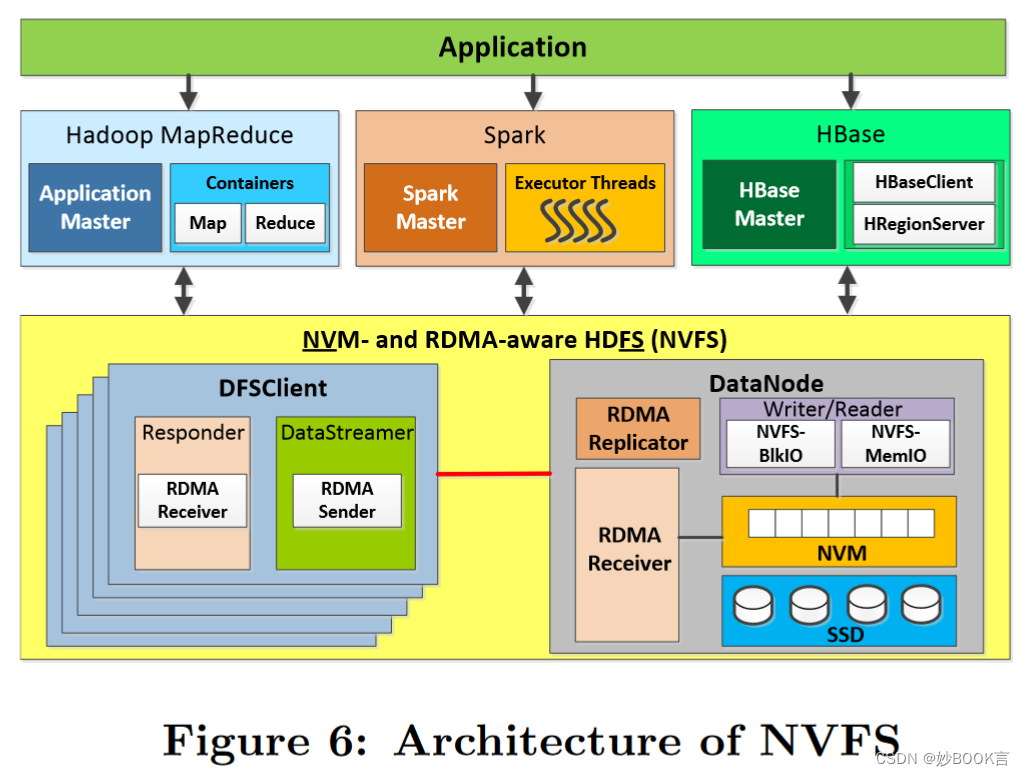
High Performance Design for HDFS with Byte-Addressability of NVM and RDMA——论文泛读
ICS 2016 Paper 分布式元数据论文阅读笔记整理 问题 非易失性存储器(NVM)提供字节寻址能力,具有类似DRAM的性能和持久性,提供了为数据密集型应用构建高通量存储系统的机会。HDFS(Hadoop分布式文件系统)是MapReduce、Spark和HBase的主要存储引擎。尽管HDFS最初是为商品硬件设计的,但它越来越多地被用于HPC(高性能计算)集群。HPC系统的性能要求使HDF
【Java】byte数组与流的相互转换
Java 中 字节流与Inputstream的互相转换 文章目录 Java 中 字节流与Inputstream的互相转换1. File/FileInputStream → byte[]2. byte[] → InputStream3. byte[] → File4. InputStream → OutputStream 1. File/FileInputStream → byt
Java Socket 如何接收byte和String
Java Socket 如何接收byte和String 一、发送byte[]与String 我们平时是怎么发送byte和String的呢?举例代码: String str = "hello world"+ "\n";byte[] bytes = 图片字节流;// 获取socket输出流OutputStream out = socket.getOutputStream();// 发送字
'ascii' codec can't decode byte 0xef in position 0:ordinal not in range(128)错误解决与原理分析
写python代码时出现’ascii’ codec can’t decode byte 0xef in position 0:ordinal not in range(128)的错误。 在解决错误之前,首先要了解unicode和utf-8的区别。 unicode指的是万国码,是一种“字码表”。而utf-8是这种字码表储存的编码方法。unicode不一定要由utf-8这种方式编成bytecode
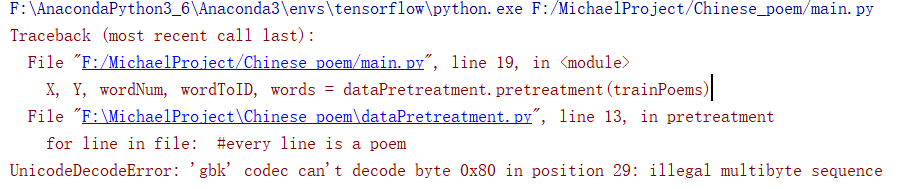
问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 29解决办法
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 python读文件: file = open(filename, "r") for line in file: #every line is a poem#print(line)title, poem = line.strip().
Gdiplus byte *数据转换为Bitmap类型图片
最近在mfc上显示缩略图那样显示采集到的图片,这个用CimageList和CListctrl就可以了,网上有很多这里不细说,但是别忘了初始化Gdiplus; 但是我的相机采集到的就是byte类型的数据,一开始显示的时候是先存到一个文件夹存为bmp又读取的。这样的话如果存的很多的话是不是读取慢呢,我说的多是指整个盘里东西很多。然后我就想着直接转换一下多好,但是在网上找了好久,试了不少方法都不行。
golang string的rune和byte
结论: range 作用于字符串,返回的k和v,v是rune类型,rune是uint32的等价类型。 对于中文字符,rune类型就是其Unicode编码。 而使用s[i]获取字符串,则是获取的byte类型,是UTF-8编码的字节。 对于中文字符,s[i]只是UTF-8编码的一部分。 例子1: s := "123abcd中国"for k, v := range s {fmt.Printf("

UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence
pycharm报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence 解决办法: 然后: 就好了!