本文主要是介绍RDMA (2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
iWARP(RDMA)怎么工作的
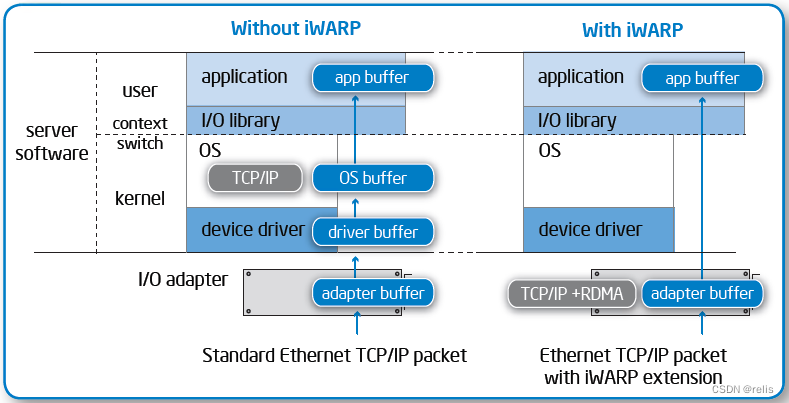
招式1:bypass内核

非iWARP时,当应用向网络适配器发出读或者写命令时,命令穿过用户空间以及内核空间,因此需要在用户空间和内核空间间进行切换。
iWARP使用RDMA,让应用直接将命令送达到网络适配器。这规避了对内核的调用,减少了开销和延迟。
招式2:直接放置数据
这篇关于RDMA (2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






