本文主要是介绍Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL——论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TACO 2024 Paper CXL论文阅读笔记整理
背景
RDMA:RDMA是一系列协议,允许一台机器通过网络直接访问远程机器中的数据。RDMA协议通常固定在RDMA NIC(RNIC)上,具有高带宽(>10 GB/s)和微秒级延迟(~2μs),这些协议得到了InfiniBand、RoCE和OmniPath等公司的广泛支持[20, 47, 62]。RDMA基于两种类型的操作原语提供数据传输服务:单侧动词,包括RDMA READ、WRITE、ATOMIC(例如FAA、CAS);双侧动词,包括RDMA SEND、RECV。RDMA通信是通过队列对(QP)和完成队列(CQ)的消息队列模型来实现的。QP由发送队列(SQ)和接收队列(RQ)组成。发送方将请求发布到SQ(单侧或双侧动词),RQ用于在双侧动词中排队RDMA RECV请求,CQ与指定的QP相关联。同一个SQ中的请求按顺序执行,通过门铃批处理[47,64],可以将多个RDMA操作合并到一个请求中。这些请求随后由RNIC读取,异步地从远程存储器写入或读取数据。当发送器的请求完成时,RNIC将完成条目写入CQ,以便发送器可以通过轮询CQ来知道它。
CXL:CXL是一种基于PCIe的开放式行业标准,用于处理器、加速器和内存之间的高速通信,采用load/store语义的缓存方式。CXL包含三个独立的协议,包括:CXL.io、CXL.cache和CXL.mem。CXL.mem允许CPU直接通过PCIe总线(FlexBus)访问底层内存,而不涉及页故障或DMA。因此,CXL可以提供字节可寻址内存(CXL内存),并允许透明的内存分配。目前大多数论文中使用的CXL原型的访问延迟约为170至250 ns[30,32,49]。
问题
内存分解是现代数据中心的一种很有前途的架构,它将计算和内存资源分离成由超快网络连接的独立池,提高内存利用率,降低成本,并实现计算和内存的弹性扩展,如图1。
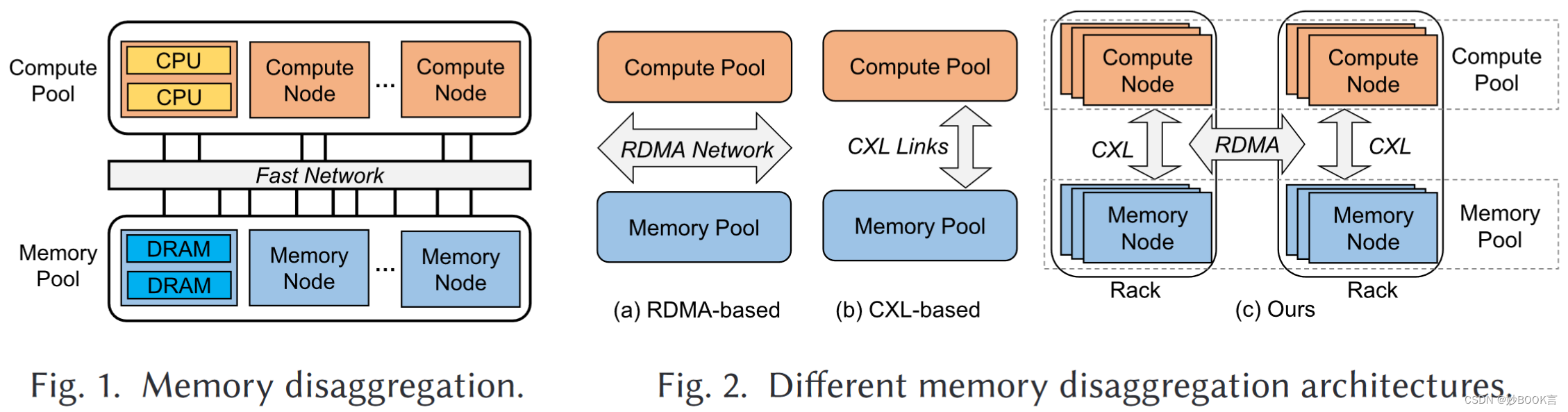
现有的基于远程直接内存访问(RDMA)的内存分解方案存在高延迟和额外开销。高延迟体现为,RDMA可以提供1.5∼3 μs的延迟,但DRAM延迟为80∼140 ns。额外开销包括页错误和代码重构,RDMA需要侵入性的代码修改和中断开销,基于RDMA的内存分解包括基于页和基于对象的方法,基于页的方法涉及页错误处理和读/写放大的额外开销[10,41],而基于对象的方法需要接口更改和源代码级别的修改,这会牺牲透明度[17,56]。
新兴的缓存一致互连(如CXL)提供了重建高性能内存分解的机会,CXL支持内存语义,并具有类似的多套接字NUMA访问延迟(约170~250 ns[21,45])。但是,现有的基于CXL的方法有物理距离限制,不能跨机架部署。
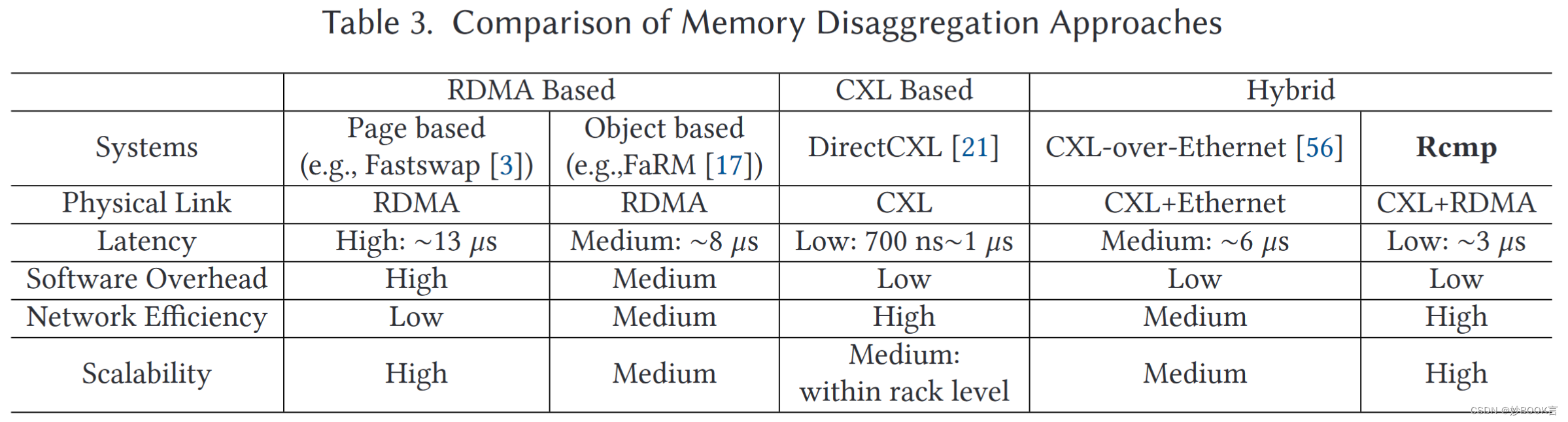
挑战
因为CXL和RDMA各自的限制,一种新的思路是在机架中构建基于CXL的小型存储器池,并使用RDMA来连接机架形成更大的内存池。但面临以下挑战:
-
粒度不匹配:基于CXL的方法支持缓存行粒度的缓存一致性,基于RDMA的方法的访问粒度是页面或对象,需要重新设计混合体系结构的内存管理和访问机制。
-
通信不匹配:RDMA通信依赖于RNIC和消息队列,而CXL则基于高速链路和缓存一致性协议。需要实现机架间和机架内通信的统一和高效的抽象。
-
性能不匹配:RDMA的延迟远大于CXL(约10倍),将导致不一致的访问模式(类似于NUMA架构)。访问本地机架中的内存比访问远程机架快得多,机架之间的RDMA通信成为主要的性能瓶颈。
本文方法
本文提出了基于RDMA和CXL的低延迟、高可扩展的内存池Rcmp,通过CXL提高了基于RDMA的系统的性能,并利用RDMA克服了CXL的距离限制。
-
提供了基于全局页面的内存空间管理,并实现了细粒度的数据访问,将数据移动大小(缓存行粒度)与内存分配大小(页粒度)解耦,避免IO放大。
-
设计了高效的机架内和机架间通信机制,以避免通信阻塞问题。
-
提出了热页识别和交换策略,以及具有同步机制的CXL内存缓存策略,以减少跨机架RDMA通信。
-
设计了RDMA感知的RPC框架来加速跨机架RDMA传输。
开源代码:GitHub - PDS-Lab/Rcmp: Rcmp: Reconstructing RDMA-based Memory Disaggregation via CXL
实现了Rcmp的原型,并通过使用微基准测试和YCSB来评估其性能。结果表明,与基于RDMA的系统相比,Rcmp可以降低5.2倍的延迟、提升3.8倍的吞吐量。还证明了Rcmp可以很好地随着节点数量的增加而扩展,而不会影响性能。
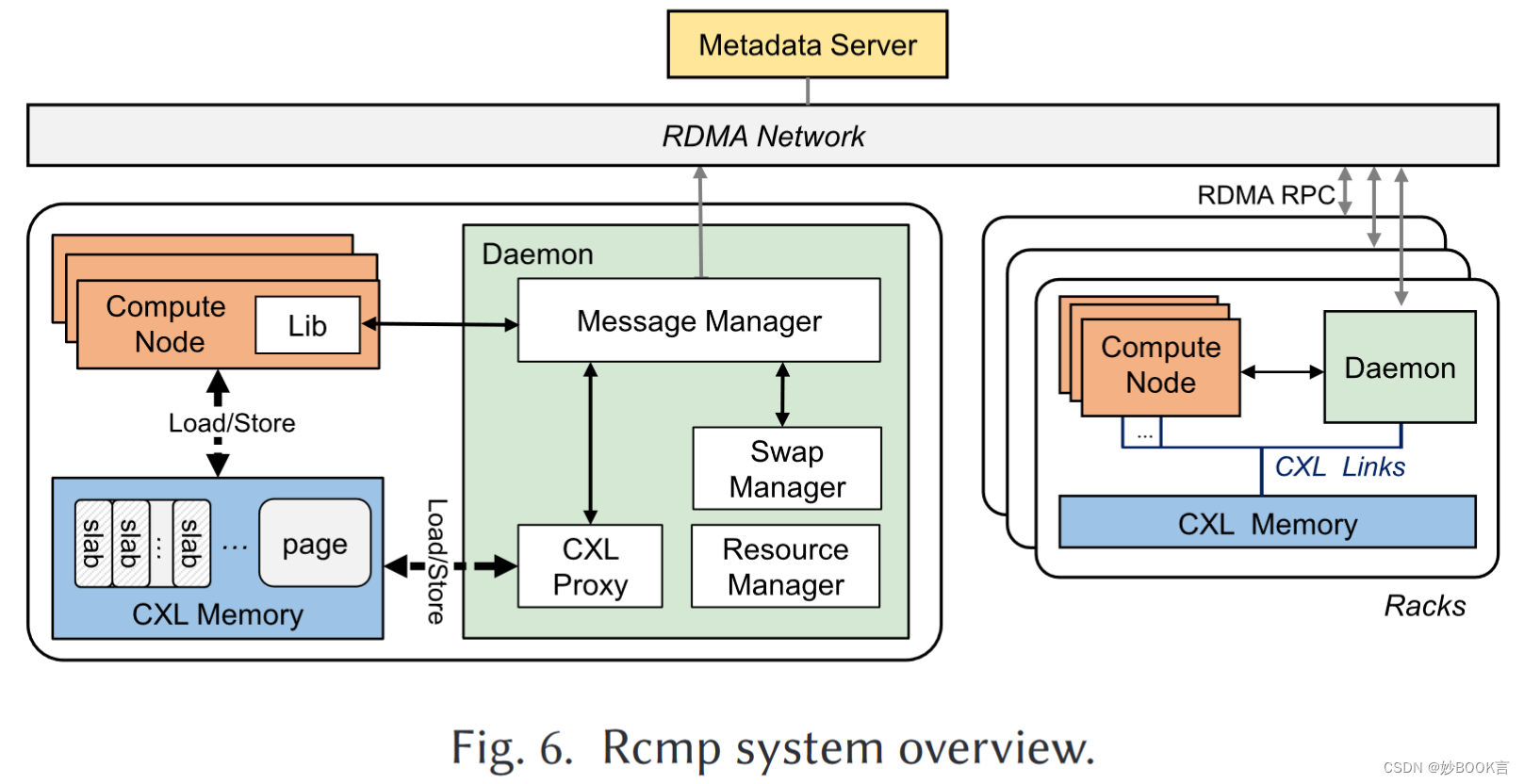
整体架构
全局内存管理:Rcmp通过基于页面的方法实现全局内存管理。页面管理方法易于采用,并且对所有用户应用程序都是透明的;与基于对象的方法相比,基于页面的方法更适合CXL的字节访问特性。为了进行细粒度管理,每个页面都被划分为许多块,并使用集中式元数据服务器(MS)来管理内存地址的分配和映射。Rcmp以缓存行粒度访问和移动数据,与内存页面大小解耦。由于CXL支持内存语义,Rcmp自然可以在机架内以缓存线粒度进行访问。对于远程机架访问,Rcmp通过使用直接访问模式(direct-I/O)而不是由页面故障触发的页面交换来避免性能下降。
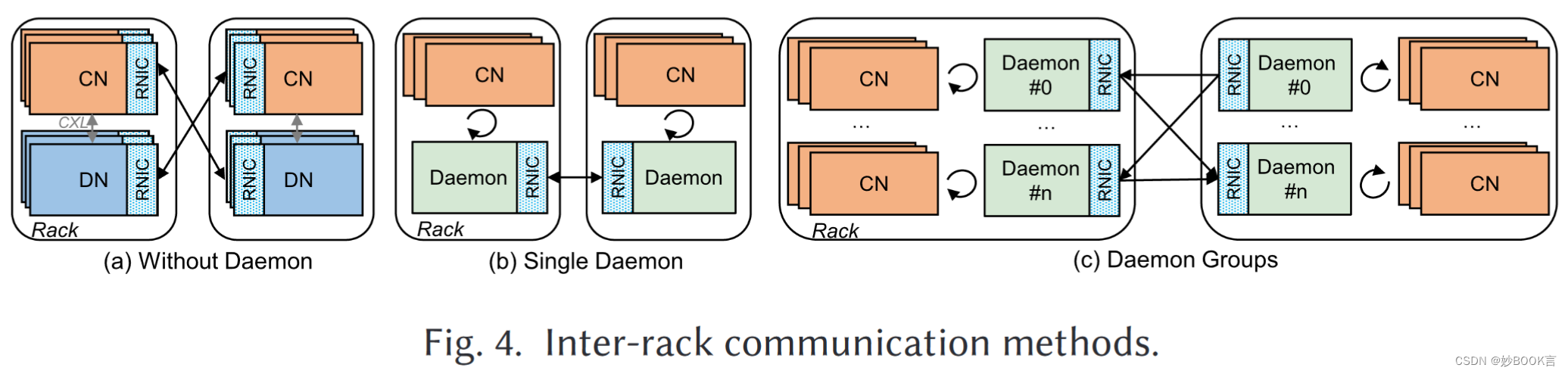
高效通信机制:如图4所示,混合架构有三种可选的远程机架通信方法。在方法(a)中,每个CN通过其RNIC访问远程机架中的存储器池。但有一下确定:RNIC设备过多导致高成本;每个CN都有CXL链路和RDMA接口,导致高一致性维护开销;与有限的RNIC存储器的高争用导致频繁的缓存失效和更高的通信延迟[17,63]。在方法(b)中,在每个机架上使用一个守护程序服务器(配备RNIC)来管理对远程机架的访问请求。守护程序可以降低成本和一致性开销,但单个守护程序将导致RDMA带宽有限。在方法(c)中,使用哈希对CN进行分组,每个组对应于一个守护程序,以避免守护程序成为性能瓶颈。所有守护进程都构建在同一个CXL内存上,并且很容易保证一致性。Rcmp支持后两种方法,在小规模节点下默认采用方法(b)。
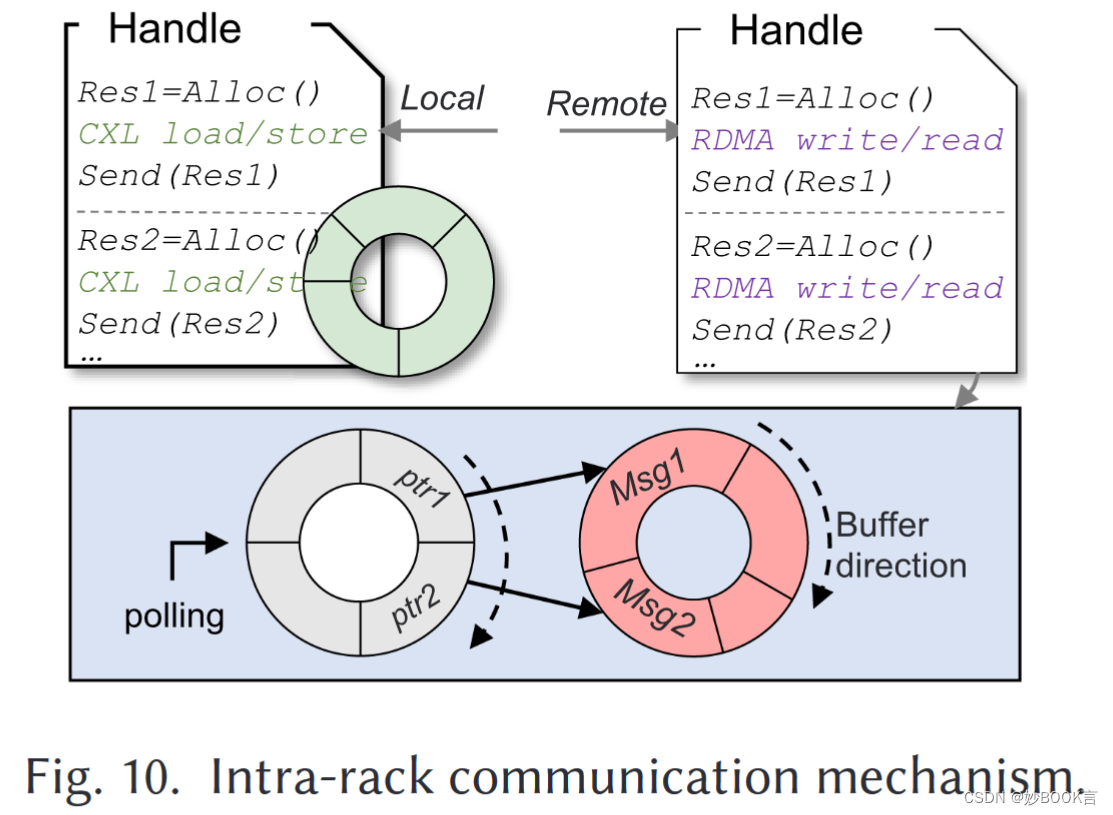
Rcmp使用无锁环形缓冲器来实现高效的机架内和机架间通信。CN需要与Daemon通信,以确定是本地访问还是远程访问,但这两种情况的访问延迟存在显著差异。为了防止通信阻塞,如本地访问排在远程访问之后导致阻塞,Rcmp为不同的访问场景使用了两个环形缓冲区结构,如图10所示。对于本地访问,使用普通环形缓冲区进行通信,图中的绿色缓冲区。由于所有访问都是超低延迟的(通过CXL),即使在高度冲突的情况下也不会发生阻塞。并基于Flock的方法[36],环缓冲区(和RDMA QP)在线程(一个CN)之间共享,以实现高并发性。对于远程访问,使用双层环形缓冲区。第一环形缓冲器(轮询缓冲器)存储消息元数据(例如,类型、大小)和指向存储消息数据的第二缓冲器(数据缓冲器)的指针。轮询缓冲区中的数据长度固定,而数据缓冲区中消息的长度可变。当数据缓冲区中的消息完成时,将请求添加到轮询缓冲区。守护线程轮询轮询缓冲区以处理当前指针指向的消息。例如,在图10中,首先填充数据缓冲区中的后一个Msg2,然后首先将请求添加到轮询缓冲区。因此,Msg2将首先被处理而不被阻塞。在实现中,使用无锁KFIFO队列[50]作为轮询缓冲区,数据缓冲区是正常的环形缓冲区。
远程机架访问优化:减少远程机架访问,Rcmp提出了一种基于页的热页识别和用户级热页交换方案,以将频繁访问的页迁移到本地机架,从而实现较少的远程机架访问。为了进一步利用时间和空间局部性,Rcmp将远程机架的细粒度访问缓存在CXL内存中,并将写入请求批处理到远程机架。加速RDMA通信,提出了一种具有混合传输模式和其他优化(例如,门铃批处理)的高性能RDMA RPC(RRPC)框架,以充分利用RDMA网络的高带宽。
实验
实验环境:五台服务器,每台服务器配备两个socket Intel Xeon Gold 5218R CPU@2.10 Ghz、128 GB DRAM、一个100 Gbps Mellanox ConnectX-5 RNIC。操作系统是Ubuntu 20.04和Linux 5.4.0-144-generic。NUMA节点0和节点1的互连延迟分别为138.5ns和141.1ns,节点内访问延迟分别为93ns和89.7ns。使用NUMA架构模拟CXL。
数据集:微基准测试、YCSB
实验对比:读写延迟、吞吐量
实验参数:数据大小、客户端数量、机架数量、消融实验
总结
针对RDMA和CXL结合的内存分解。本文提出基于RDMA和CXL的内存池Rcmp,通过CXL提高了基于RDMA的系统的性能,并利用RDMA克服了CXL的距离限制。包括4个创新点:(1)基于全局页面的内存空间管理,支持细粒度的数据访问,避免IO放大。(2)使用不同缓存区结构避免通信阻塞,机架内访问使用环形缓存区,机架间访问使用双层缓冲区,第一级存储已完成的访问避免阻塞,第二级使用环形缓存区,执行完时将请求添加到第一级缓冲区。(3)使用热页识别和交换策略,以及具有同步机制的CXL内存缓冲区,以减少跨机架RDMA通信。(4)设计了RDMA感知的RPC框架来加速跨机架RDMA传输。
这篇关于Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL——论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









