本文主要是介绍[姿态预测] Flowing ConvNets for Human Pose Estimation in Videos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ICCV 2015 code available
http://www.robots.ox.ac.uk/~vgg/software/cnn_heatmap/
本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。
网络框架如下:
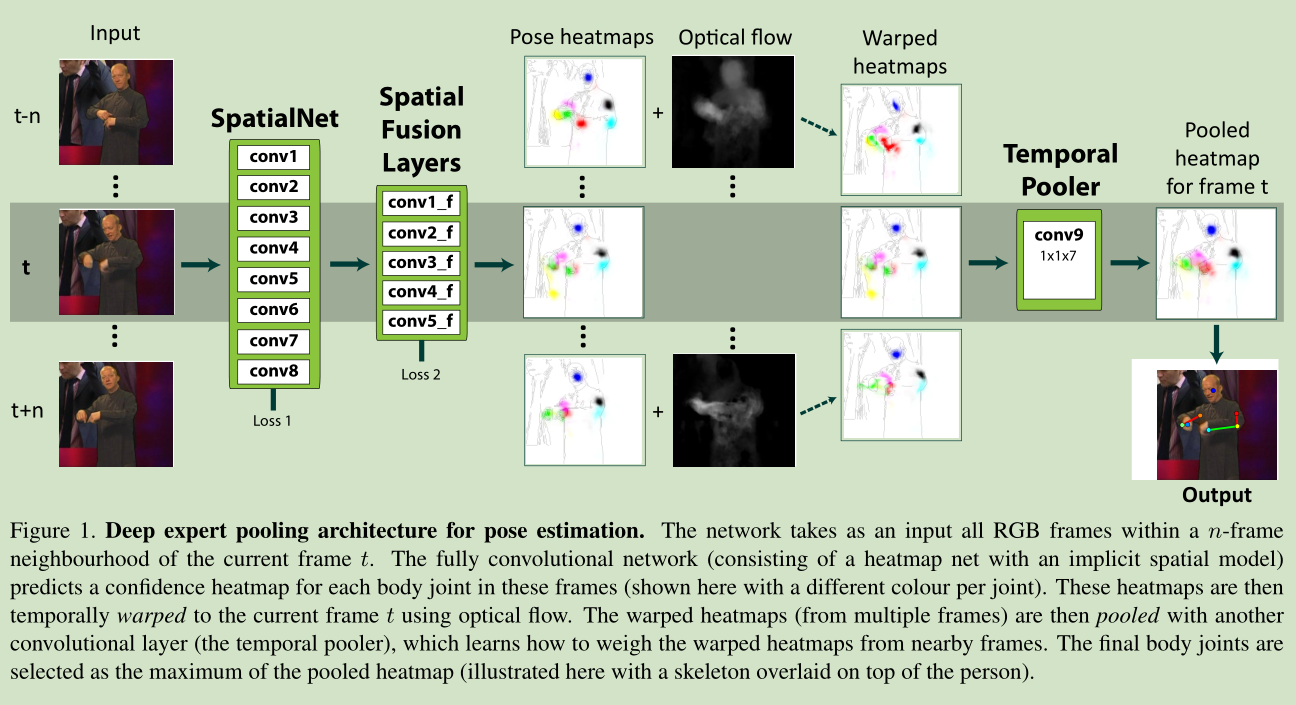
本文对于关节位置的估计提出了一个 heatmap概念,而不是一个坐标的回归。这样做可以提高关节定位的鲁棒性。
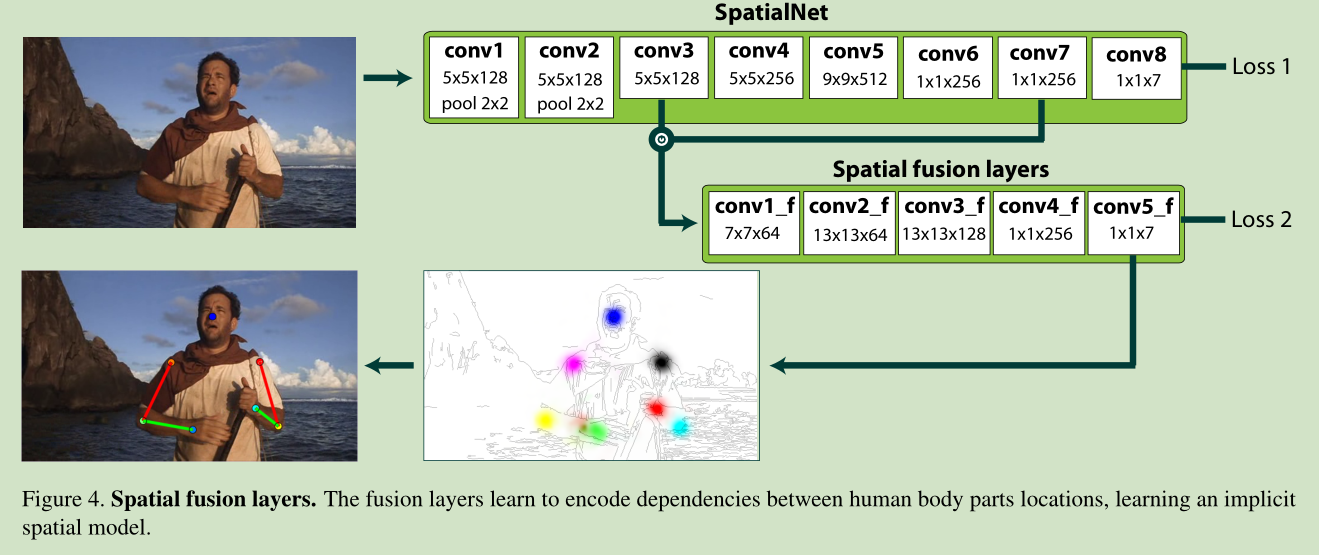
Spatial fusion layers 这主要是用来提取关节之间内在联系的。
learn dependencies between the human body parts locations represented by
these activations
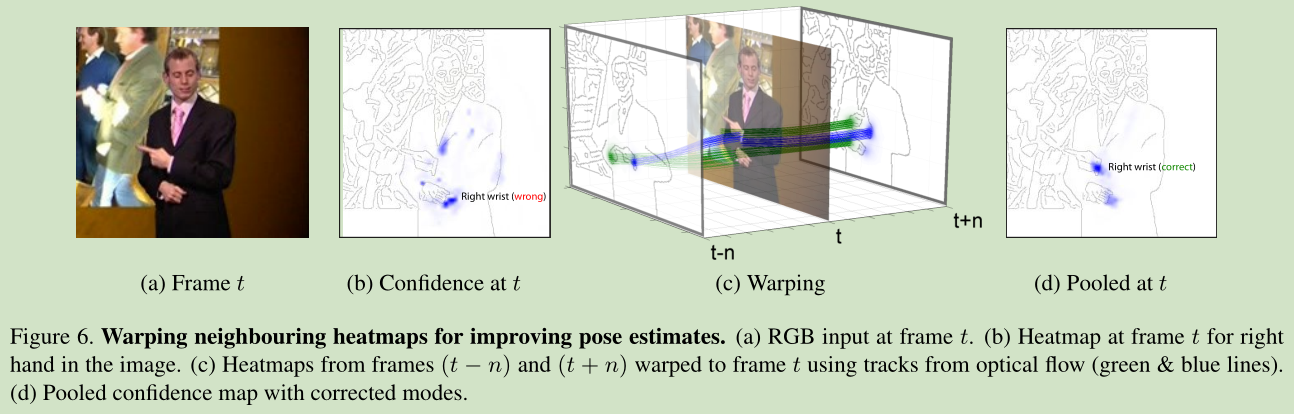
Optical flow for pose estimation: 使用光流法来增强 heatmaps,具体通过以下三个步骤来实现:
1) the confidences from nearby frames are aligned to the current frame using
dense optical flow
2) these confidences are then pooled into a composite confidence map using
an additional convolutional layer
3) the final upper body pose estimate for a frame is then simply the positions
of maximum confidence from the composite map
通过综合前后帧信息来提高鲁棒性。
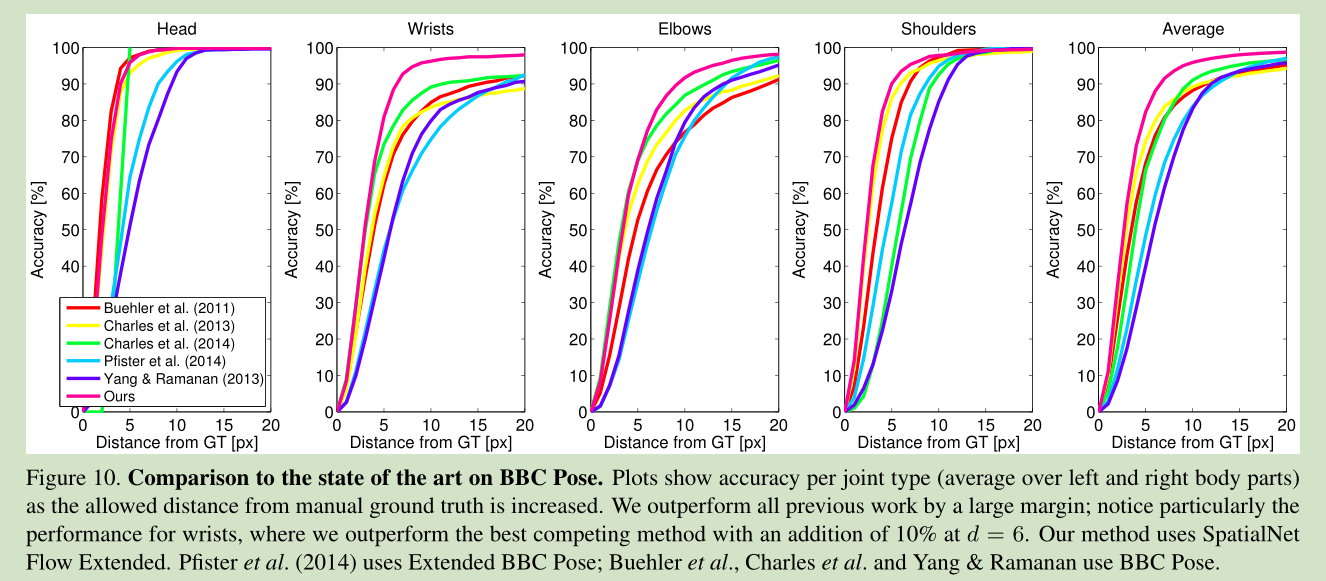
结果:
这篇关于[姿态预测] Flowing ConvNets for Human Pose Estimation in Videos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








