convnets专题
《Towards Good Practices for Very Deep Two-Stream ConvNets》阅读笔记
作者信息:Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, 摘要 深度卷积神经网络在静止图像的目标识别取得了巨大的成功,但是在视频的行为识别领域,深度学习提升的效果并不是很显著,主要的原因有两点: 相对于图像识别,视频的行为识别所使用的卷积网络结构深度太浅,因此模型的拟合能力因为深度受到限制。第二点可能更为重要,主要是用于行为识别的视频数据集规模相对

Shift-ConvNets:具有大核效应的小卷积核
摘要 https://arxiv.org/pdf/2401.12736.pdf 最近的研究表明,Vision transformers (ViTs)的卓越性能得益于大的感受野。因此,大型卷积核设计成为使卷积神经网络(CNNs)再次变得出色的理想解决方案。然而,典型的大的卷积核被证明是对硬件不友好的操作,导致与各种硬件平台的兼容性降低。因此,简单地增大卷积核的大小是不明智的。在本文中,我们揭示了小

RepVGG:使VGG样式的ConvNets再次出色
重振VGG雄风!主体仅使用3×3卷积和ReLU!据作者称,在ImageNet上,RepVGG的top-1准确性达到80%以上,这是基础模型的首次实现!综合性能超越ResNet、EfficientNet等,部分代码刚刚开源! 注1:文末附【计算机视觉细分垂直方向】交流群(含检测、分割、跟踪、医疗、GAN、Transformer等) 注2:欢迎点赞,支持分享! RepVGG RepVGG: M
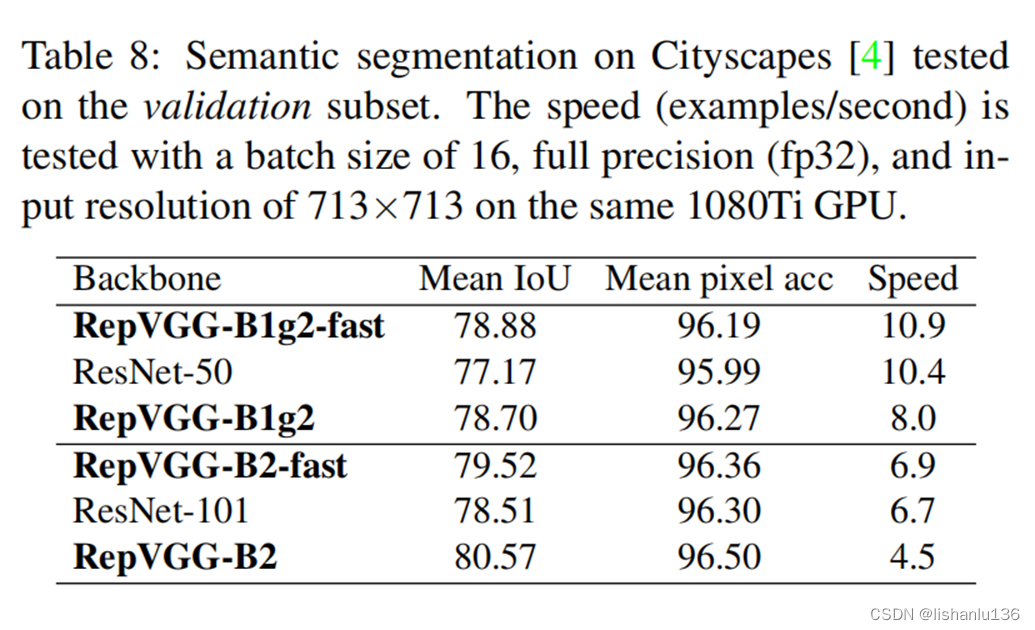
RepVGG,结构重参数化让VGG风格的ConvNets再次强大起来
论文:RepVGG Making VGG-style ConvNets Great Again 链接:https://arxiv.org/abs/2101.03697 代码链接:https://github.com/DingXiaoH/RepVGG 发表刊物:cvpr2021 作者:Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Gu
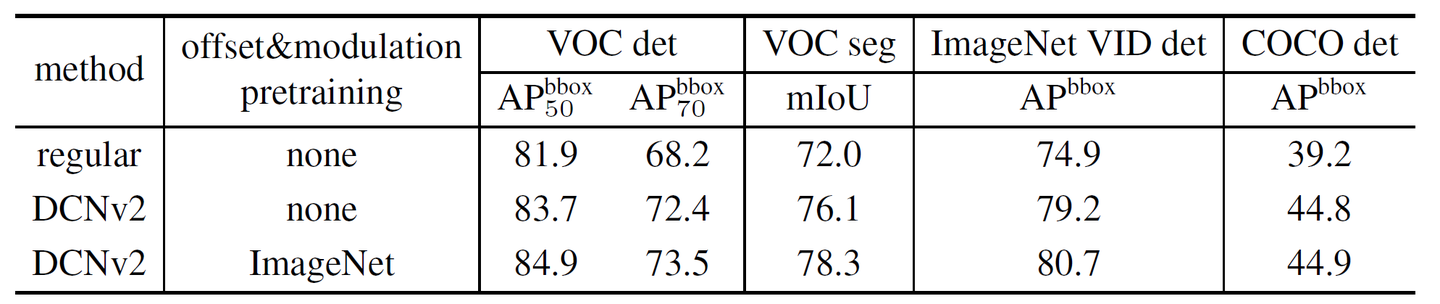
论文阅读——Deformable ConvNets v2
论文:https://arxiv.org/pdf/1811.11168.pdf 代码:https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch 1. 介绍 可变形卷积能够很好地学习到发生形变的物体,但是论文观察到当尽管比普通卷积网络能够更适应物体形变,可变形卷积网络却可能扩展到感兴趣区域之外从而使得不相关的区域影响网
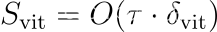
ConvNets 与 Vision Transformers:数学深入探讨
一、说明 我目睹了关于 Vision Transformer 的争论,讨论它们如何与 CNN 一样好或更好。我想知道我们是否也同样争论菠萝比西瓜好!或者马比海豚更好?其中许多讨论往往缺乏具体性,有时可能会歪曲上下文。 作为背景,在快速发展的深度学习领域,有两种架构在图像“分类”任务中脱颖而出:卷积神经网络(ConvNets)

论文分享 Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations wi
摘要: 卷积网络(ConvNet)在各种具有挑战性的视觉任务中取得了巨大的成功。 然而,当遇到域偏移时,ConvNet的性能会降低。 领域自适应在生物医学图像分析领域具有更大的意义,同时在生物医学图像分析领域具有挑战性,其中跨模态数据具有很大的不同分布。 鉴于注释医疗数据是特别昂贵的,有监督的迁移学习方法并不是很理想。 本文提出了一种用于跨模态生物医学图像分割的具有对抗性学习的无监督域自适应框架
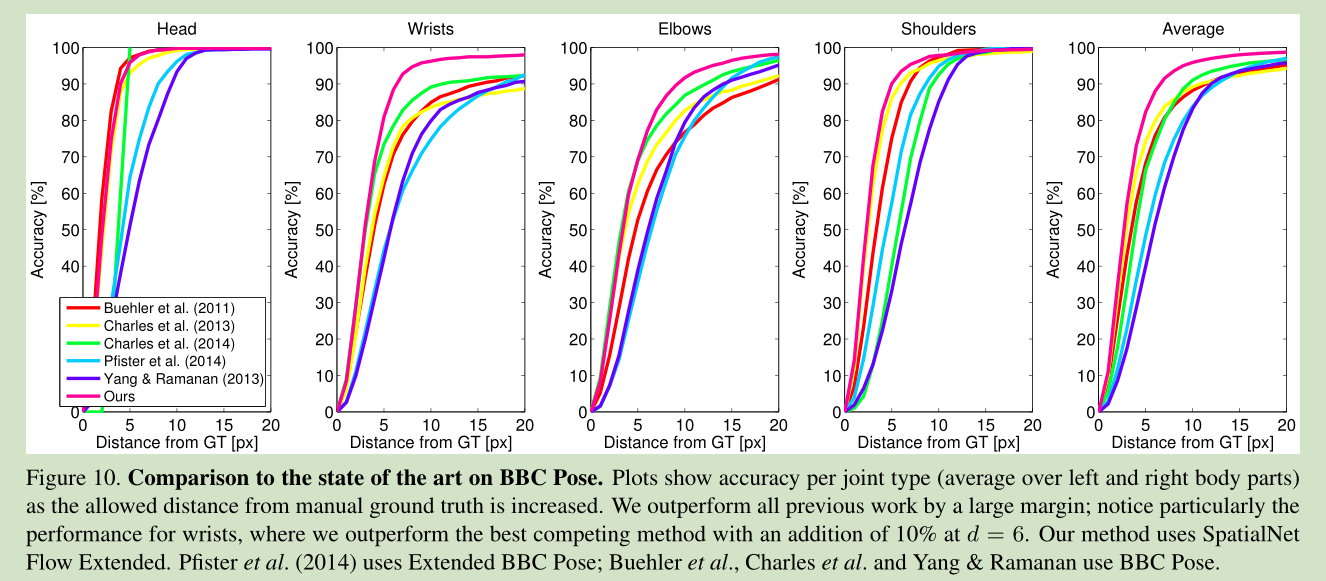
Flowing ConvNets for Human Pose Estimation in Videos
ICCV 2015 code available http://www.robots.ox.ac.uk/~vgg/software/cnn_heatmap/ 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。 网络框架如下: 本文对于关节位置的估计提出了一个 heatmap概念,而不是一个坐标的回归。这样做可以提高关节定位的鲁棒性。 Spatial fu
[姿态预测] Flowing ConvNets for Human Pose Estimation in Videos
ICCV 2015 code available http://www.robots.ox.ac.uk/~vgg/software/cnn_heatmap/ 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。 网络框架如下: 本文对于关节位置的估计提出了一个 heatmap概念,而不是一个坐标的回归。这样做可以提高关节定位的鲁棒性。 Spatial fusi

论文阅读:《Flowing ConvNets for Human Pose Estimation in Videos》ICCV 2015
概述 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。本文的四个贡献: 1. 提出了一个更深的CNN网络(相比于Alex-Net),不同于之前的回归坐标,而是回归heatmap,这样可以提高关节点定位的鲁棒性,并且更利于在训练过程中的可视化观察。 2. 提出一种空间融合层,用来学习隐式空间模型,即用来提取关节点之间的内在联系 3. 使用光流信息,用来对准