本文主要是介绍论文分享 Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations wi,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:
卷积网络(ConvNet)在各种具有挑战性的视觉任务中取得了巨大的成功。 然而,当遇到域偏移时,ConvNet的性能会降低。 领域自适应在生物医学图像分析领域具有更大的意义,同时在生物医学图像分析领域具有挑战性,其中跨模态数据具有很大的不同分布。 鉴于注释医疗数据是特别昂贵的,有监督的迁移学习方法并不是很理想。 本文提出了一种用于跨模态生物医学图像分割的具有对抗性学习的无监督域自适应框架。 具体来说,我们的模型是基于一个扩展的完全卷积网络进行像素预测。 此外,我们还构建了一个即插即用领域适应模块(DAM) 将目标输入映射到与源域特征空间对齐的特征。 为了区分两个域的特征空间,建立了一个域评分模块(DCM)。 我们在不使用任何目标域标签的情况下,通过对抗性损失优化了DAM和DCM。 我们提出的方法是通过将经MRI图像训练的ConvNet适应到未配对的心脏CT数据的分割来验证的,并取得了非常有希望的结果。
方法
1. ConvNet Segmenter Architecture

ConvNet 利用源域标记数据,通过最小化由多类交叉熵损失和Dice共同损失组成的混合损失Lseg进行了优化, 源域分割器损失函数如下:
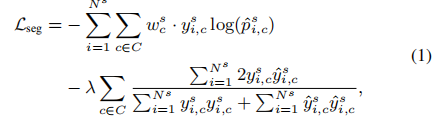
其中第一项是像素分类的交叉熵损失, w c s w_c^s wcs是处理类不平衡问题的加权因子。 在实践中,我们也尝试只使用一种类型的损失,但性能不是很高。
2. Plug-and-Play Domain Adaptation Module
当在源域上学习ConvNet时,我们的目标是将其推广到目标域。 在迁移学习中,网络的最后几层通常通过新的标签空间微调为一个新的任务。理论支持是,网络中的早期层提取低层次的特征(如边缘滤波器和彩色斑点),这些特征是视觉任务中常见的特征。 顶层是更具体的任务,如学习分类器的高层次特征。
在这种情况下,需要从目标域标记数据来监督学习过程。 不同的是,我们使用来自目标域的未标记数据,因为标记数据集既耗时又昂贵。 这在放射科医生的临床实践中是至关重要的 ,他们更愿意以尽可能少的额外注释成本,在交叉模态数据上执行图像计算。 因此,我们建议将ConvNet与无监督学习相适应。
在我们的分割器中,源域映射 M s M_s Ms是由 m l 1 s , . . . , m l n s {m^s_{l1},...,m^s_{ln}} ml1s,...,mlns的叠加变换组成的分层特征提取器,l表示网络层索引。 形式上,对源域的预测是:
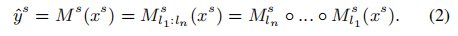
对于域适应,源域和目标域的标签空间是相同的,我们的假设是,交叉模态域之间的分布变化主要是低级特征(例如灰度值),而不是高级特征(例如几何结构)。 较高的层(如 m l n s m^s_{ln} mlns)与可以跨不同域共享的类标签密切相关, 在这方面,我们建议重用在ConvNet的更高层中学习的特征提取器, 而早期的层被更新以在特征空间中进行分布映射,以便我们的无监督域自适应。
对于目标域 x t x^t xt的输入,我们提出了一个由 M \mathscr{M} M表示的域自适应模块,该模块将 x t x^t xt映射到源域的特征空间。 我们用d表示适应深度,即在处理目标域图像时,将早于ld和包括ld的层替换成DAM。 同时,源模型的顶层在域自适应学习过程中被冻结,并重用于目标推理中。形式上,对目标域的预测是:
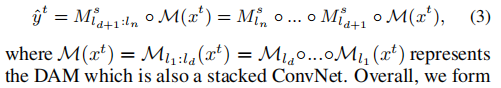
在测试推理过程中,DAM直接替换了在源域上训练的模型的早期d层。通过DAM对目标域的图像进行处理并映射到源域的深度学习特征空间。这些适应的特征对跨模态域移位具有鲁棒性,并且可以使用在源域上建立的高级层映射到标签空间。
在实践中,DAM的ConvNet配置与 m l 1 s , . . . , m l d s {m^s_{l1},...,m^s_{ld}} ml1s,...,mlds相同。 我们用经过训练的源域模型初始化DAM,并以无监督的方式通过对抗性损失对参数进行微调。
3. Learning with Adversarial Loss
我们建议通过无监督学习来训练我们的领域适应框架。对抗训练的精神源于GAN,在GAN中,一个生成器模型和一个鉴别器模型形成了一个极小极大两人游戏。生成器学习捕捉真实的数据分布;鉴别器估计样本来自真实训练数据而不是生成数据的概率。这两个模型交替优化,相互竞争,直到发生器可以产生鉴别器无法区分的真实样本。对于我们的问题,我们训练了DAM,旨在使ConvNet能够从目标输入中生成类似源的特征图。因此,从GAN的角度来看,ConvNet相当于一个生成器。
给定 ( M A ( x t ) , F H ( X T ) ) ∼ P g (M_A(x^t),F_H(X^T))∼Pg (MA(xt),FH(XT))∼Pg和 ( M A s ( x s ) , F H ( x s ) ) ∼ P s (M^s_A(x^s),F_H(x^s))∼Ps (MAs(xs),FH(xs))∼Ps的分布,这两个域分布之间需要最小化的距离表示为W(Ps,Pg)。 F H ( . ) F_H(.) FH(.)其中H={k,…q}是所选层索引的集合。类似地,我们用 M A ( . ) M_A(.) MA(.)来表示DAM的所选特征图,其中A是所选的图层集。
为了稳定训练,我们采用两个分布之间的Wassertein距离,如下所示:
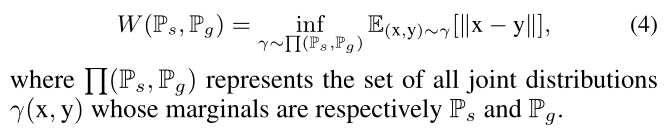
在无监督学习中,我们通过对抗损失联合优化生成器和鉴别器。

在M和D的交替更新期间,DCM输出来自两个域的特征空间分布之间的W(Ps,Pg)的更精确估计。更新后的DAM更有效地生成源域特征图,用于进行跨模态域自适应。
4. Training Strategies
在我们的设置中,源域是生物医学心脏磁共振成像图像,目标域是计算机断层扫描数据。所有体积的磁共振成像和计算机断层扫描图像被重新采样到1×1×1 mm3的体素间距,并被裁剪成以心脏区域为中心的256×256×256的尺寸。在预处理中,我们分别对每个域进行了强度标准化,旋转、缩放和仿射变换的增强被用来对抗过拟合。为了利用体积数据中存在的空间信息,我们沿着冠状面对连续的三个切片进行采样,并将它们输入三个通道。当训练2D网络时,中间切片的标签被用作GT。
我们首先用随机梯度下降的监督方式对源域数据进行训练。Adam优化器的参数为批量5,学习率1×10-3,每1500次迭代的步进衰减率0.95。在此之后,我们交替地优化了DAM和DCM,使其在无监督的领域适应中具有对抗损失。遵循训练WGAN的启发式规则[Arjovsky等人,2017],当更新DCM时,我们每20次迭代更新一次DAM。在对抗性学习中,我们使用了RMSProp优化器,其学习率为3×10-4,每100次联合更新的步进衰减率为0.98,鉴别器的权重裁剪为0.03。
实验
数据集
MICCAI 2017 Multi-Modality Whole Heart Segmentation [Zhuang and Shen, 2016].
该数据集由来自40名患者的不成对的20幅磁共振成像和20幅计算机断层扫描图像组成。磁共振成像和计算机断层扫描数据是在不同的临床中心获得的。影像的心脏结构由放射科医师手动为核磁共振成像和计算机断层扫描图像进行注释。我们的ConvNet分割器旨在自动分割四个心脏结构,包括升主动脉、左心房血腔、左心室血腔和左心室心肌(AA, LA-blood, LV-blood and LV-myo)。对于每种模式,我们将数据集随机分为训练集(16名受试者)和测试集(4名受试者),它们在所有实验中都是固定的。
结果
我们设计了几个实验设置:
1)在源域上训练和测试ConvNet分割器;
2)在注释的目标域数据上从头开始训练分割器(称为Seg-CT);
3)用带注释的目标域数据微调源域分割器,即监督转移学习(称为Seg-CT-STL);
4)在目标域数据上直接测试源域分割器;
5)我们提出的无监督域自适应方法。
我们还比较了以前使用ConvNets的最先进的心脏分割方法[Payer等人,2017]。最后但同样重要的是,我们进行了消融研究,以观察适应深度将如何影响性能。

图3:不同的计算机断层图像分割方法的结果。每一行从左到右呈现一个典型的例子:(a)原始的CT切片,(b)基本的真值标签,©有监督的迁移学习,(d)从零开始训练的ConvNets,(e)直接对CT数据应用磁共振图像分割,(f)我们的无监督的跨模态域自适应结果。AA, LA-blood, LV-blood and LV-myo的结构分别用黄色、红色、绿色和蓝色表示(最好用颜色表示)。
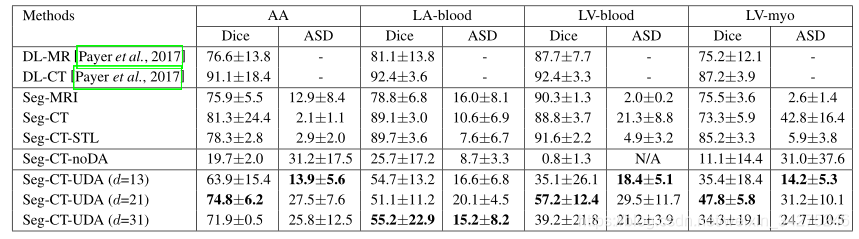
表1:不同方法对心脏结构分割性能的定量比较。

这篇关于论文分享 Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations wi的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





