modality专题

Mini-Gemini Mining the Potential of Multi-modality Vision Language Models
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models TL; DR:本文构建了一个支持 text+image 多模态输入、text+image 多模态输出的真正的多模态大模型 Mini-Gemini。技术方面主要有三个要点:高效高分辨率的视觉 token 编码,高质量的数据,以及通过 VLM 引导的图
论文解读:(CAVPT)Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
v1文章名字:Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model v2文章名字:Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model 文章汇总 对该文的改进:论文解读:(VPT)Visual Prompt Tuning_vpt

Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models 相关链接:arxiv 关键字:Vision Language Models、Multi-modality、High-Resolution Visual Tokens、High-Quality Data、VLM-guided Generation

《InfMAE: A Foundation Model in Infrared Modality》CVPR2024
基础模型vs大模型:大模型,也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型 以后的研究中必须把大模型和基础模型耦合进来 总结:占坑 1. A+B 多光谱的基础模型 红外的基础模型 可见光的基础模型 整体架构差不多,不一样的地方值得研究,就可以考虑A+B 2. 利用跨模态的基础模型去做我们领域的基础研究

从rookie到基佬~017:BEIT-3基础概念解析-Modality experts
一天一个变弯小技巧 今日份洗脑: Modality experts概念解析 结论:Modality experts指专门处理特定类型数据(或称为"模态")的专家模型或专家网络 涉及研究内容: 原文:Wang W, Bao H, Dong L, et al. Image as a Foreign Language: BEiT Pretraining for All Vision and Vi
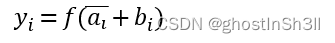
ImageBind-LLM: Multi-modality Instruction Tuning 论文阅读笔记
ImageBind-LLM: Multi-modality Instruction Tuning 论文阅读笔记 Method 方法Bind NetworkRMSNorm的原理及与Layer Norm的对比 Related Word / Prior WorkLLaMA-Adapter 联系我们 本文主要基于LLaMA和ImageBind工作,结合多模态信息和文本指令来实现一系列任务
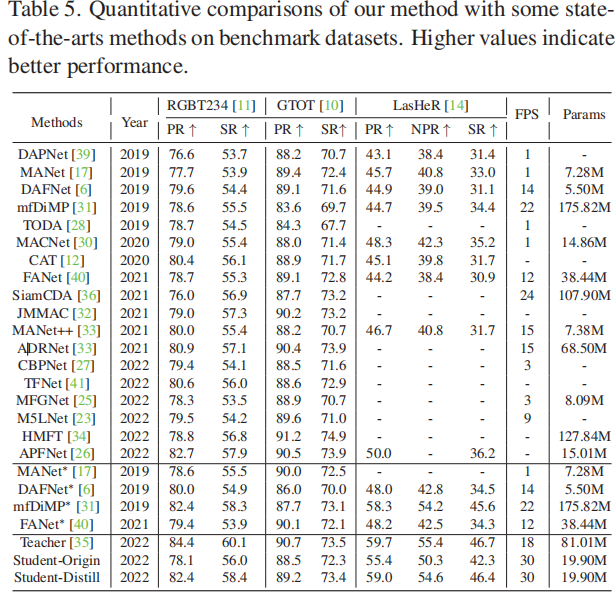
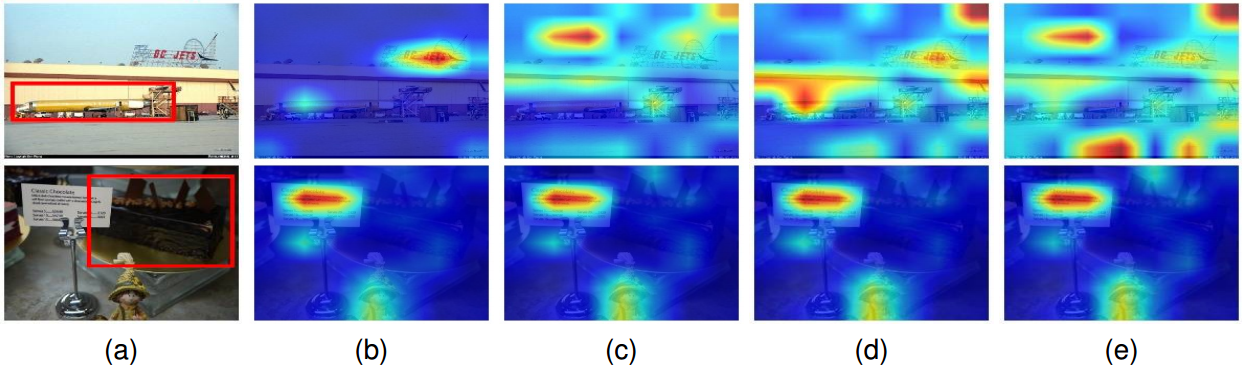
Efficient RGB-T Tracking via Cross-Modality Distillation
摘要 目前大多数RGB-T跟踪器采用双流结构来提取单个RGB和热红外特征,并采用复杂的融合策略来实现多模态特征融合,这需要大量的参数,阻碍了它们的实际应用。另一方面,一个紧凑的RGB-T跟踪器可能具有计算效率,但由于特征表示性能的减弱,会遇到不可忽视的性能下降。为了解决这种情况,提出了一种跨模态蒸馏框架来弥合紧凑跟踪器和强大跟踪器之间的性能差距。本文提出了一种特定公共特征蒸馏模块,将模态公共
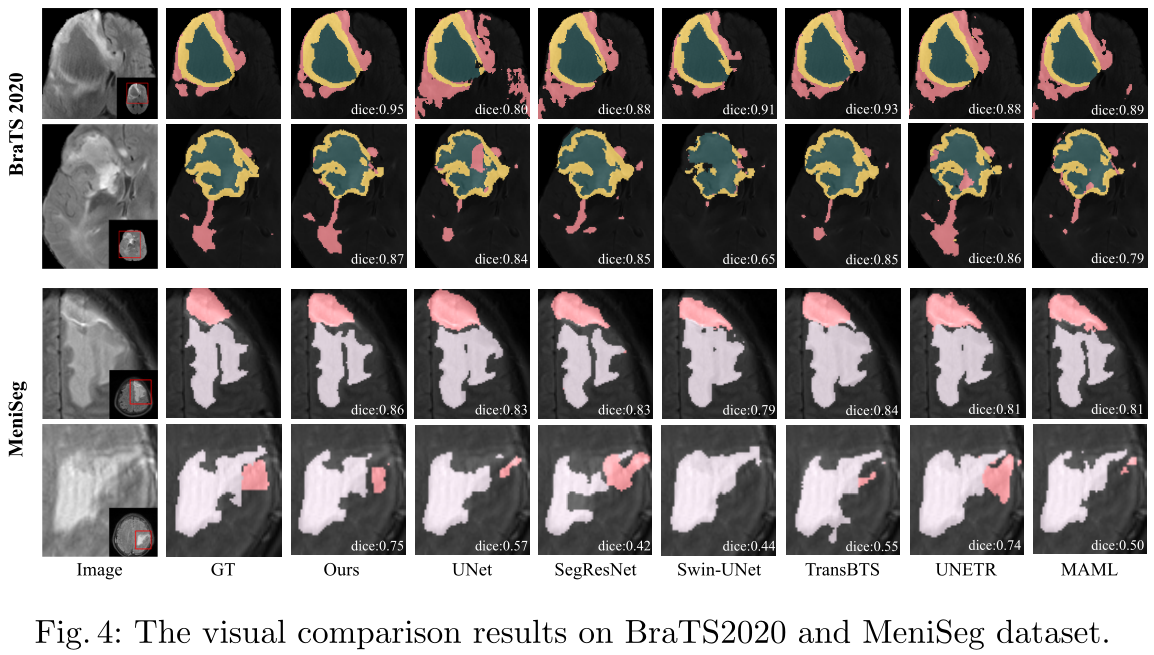
【论文笔记】NestedFormer: Nested Modality-Aware Transformer for Brain Tumor Segmentation
论文 标题:NestedFormer: Nested Modality-Aware Transformer for Brain Tumor Segmentation 收录:MICCAI 2022 paper:https://arxiv.org/abs/2208.14876 code:GitHub - 920232796/NestedFormer: NestedFormer: Neste
![[深度学习论文笔记]Cross-Modality Deep Feature Learning for Brain Tumor Segmentation](https://img-blog.csdnimg.cn/f3d61d1b3a4745cabcc5fad85faae917.png)
[深度学习论文笔记]Cross-Modality Deep Feature Learning for Brain Tumor Segmentation
Cross-Modality Deep Feature Learning for Brain Tumor Segmentation 跨通道深度特征学习在脑肿瘤分割中的应用 Published : Pattern Recognition 2021 论文:https://arxiv.org/abs/2201.02356 代码: 机器学习和数字医学图像的流行,为利用深度卷积神经网络解决具有挑战性的

NestedFormer:Nested Modality-Aware Transformer for Brain Tumor Segmentation
NestedFormer: Nested Modality-Aware Transformer for Brain Tumor Segmentation NestedFormer:嵌套的模态感知transformer在脑肿瘤分割中的应用 MICCAI 2022 多模态磁共振成像通过提供丰富的互补信息,在临床实践中经常被用于诊断和研究脑肿瘤。以前的多模态MRI分割方法通常是在网络的早期/

跨模态行人重识别:Towards a Unified Middle Modality Learning forVisible-Infrared Person Re-Identification阅读笔记
目录 摘要 方法 结果 论文链接 摘要 提出了一种非线性中间模态生成器(MMG),它有助于减少模态差异。MMG 可以有效地将 VIS 和 IR 图像投影到统一的中间模态图像 (UMMI) 空间中,以生成中间模态 (M-modality) 图像。生成的 M 模态图像和原始图像被馈送到主干网络以减少模态差异。为了将 UMMI 空间中从 VIS 和 IR
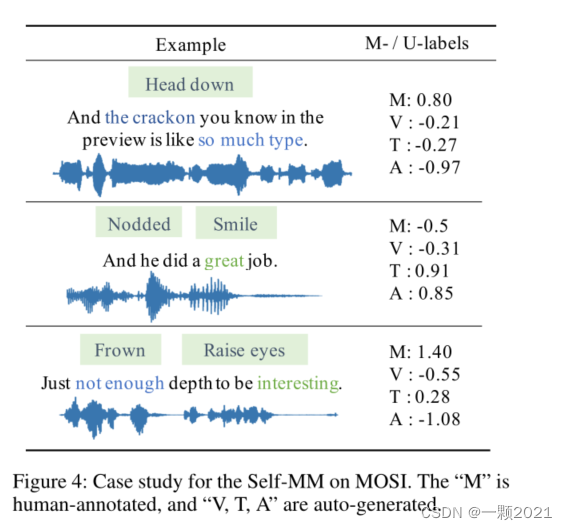
2021AAAI)Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for MSA
Self-MM 1. 动机: 根据表征学习中指导的不同,我们将现有的方法分为前向指导和后向指导两类。 在正向制导方法中,研究致力于设计用于捕获跨模态信息的交互(MFN之类)模块(Zadeh et al 2018a;Sun等2020;蔡等人2019;Rahman et al 2020)。然而,由于统一的多模态注释,它们很难捕获特定于模态的信息。在反向引导方法中,研究人员提出了附加的损失函数作为先

论文分享 Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations wi
摘要: 卷积网络(ConvNet)在各种具有挑战性的视觉任务中取得了巨大的成功。 然而,当遇到域偏移时,ConvNet的性能会降低。 领域自适应在生物医学图像分析领域具有更大的意义,同时在生物医学图像分析领域具有挑战性,其中跨模态数据具有很大的不同分布。 鉴于注释医疗数据是特别昂贵的,有监督的迁移学习方法并不是很理想。 本文提出了一种用于跨模态生物医学图像分割的具有对抗性学习的无监督域自适应框架
论文阅读25 | Exploring Modality-shared Appearance Features and Modality-invariant Relation Features reid
论文:Exploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification 1.创新点 本文的创新点在于,作者提出表观特征的不同通道关注着人体的不同部位,所以使用三维卷积寻找不同通道之间的关系,即人体部位