本文主要是介绍论文解读:(CAVPT)Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
v1文章名字:Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
v2文章名字:Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model
文章汇总
对该文的改进:论文解读:(VPT)Visual Prompt Tuning_vpt 代码实现-CSDN博客
存在的问题

比如对于第一张图,图像编码器提取对象的所有视觉特征,即Zero-Shot CLIP和CoOp(看b图)的注意图同时突出了人和摩托车。然而,下游任务要求输出类标签为“motorbike”
解决办法
将任务相关信息和视觉实例信息同时编码到视觉提示中,类感知的视觉提示是通过文本提示特征和视觉图像补丁嵌入之间的交叉关注来动态生成的。
流程解读

文本提示
Text Encoder g(·)的输入为其中
为类别token。为了将我们的CAVPT生成器的计算复杂性降低为常数,我们借助Zero-Shot CLIP Inference模块从Text Encoder 生成的Text Prompts Features(图的右侧)选择
(me:与类别相似度最高的
个文本)文本提示特征。
视觉提示
这与VPT一样,采用的是VPT-deep。
训练过程如下
![]()
分别为CLS,视觉提示,图像编码
CAVPT Generator
结构如下:
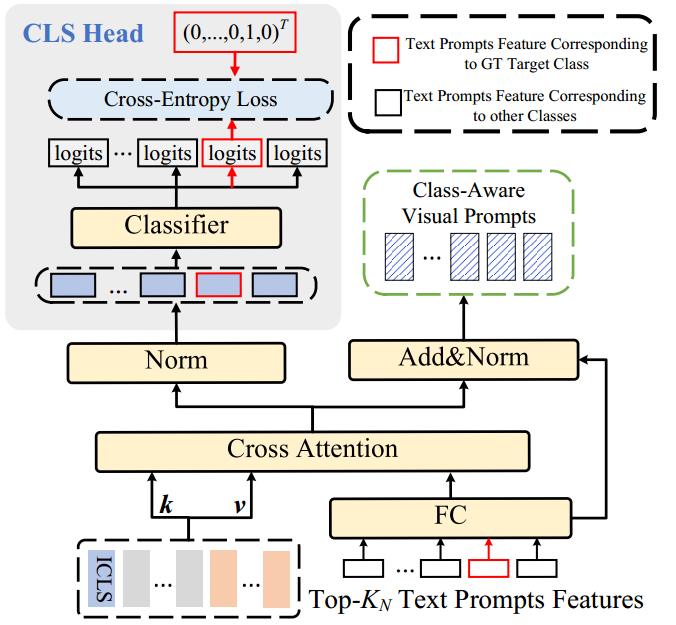
me:核心就是将包含视觉提示的视觉输入与Top-Kn Text Prompts Features 进行Cross Attention,最终与文本视觉相关联的 Class-Aware Visual Prompts,之后Class-Aware Visual Prompts与
一起通过transformer进行训练。
损失函数的设计
总损失如下:为超参数
![]()
下面的是来自CAVPT Generator的损失
摘要
随着大型预训练视觉语言模型(如CLIP)的出现,可转移表征可以通过及时调整适应广泛的下游任务。从存储在预训练模型中的一般知识中,提示调优探测下游任务的有益信息。最近提出了一种名为上下文优化(CoOp)的方法,该方法从语言方面引入了一组可学习向量作为文本提示。然而,单独调整文本提示符只能调整合成的“分类器”,而不能影响图像编码器的计算视觉特征,从而导致次优解。在本文中,我们提出了一种新的双模态提示调谐(DPT)范式,通过同时学习文本和视觉提示。为了使最终的图像特征更集中于目标视觉概念,我们在DPT中进一步提出了类感知视觉提示调优(CAVPT)方案。在该方案中,通过文本提示特征和图像补丁令牌嵌入之间的交叉关注,动态生成类感知的视觉提示,对下游任务相关信息和视觉实例信息进行编码。在11个数据集上的大量实验结果证明了该方法的有效性和泛化能力。我们的代码可在GitHub - fanrena/DPT: The official implementation of paper Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model. If you find our code or paper useful, please give us a citation.中获得。
介绍
近年来,大规模视觉语言模型(VLM)的研究,如CLIP[1]和ALIGN[2],在表示学习方面取得了显著进展[3]-[5]。得益于大量的图像-文本数据,预训练的大规模视觉语言模型能够学习由自然语言生成的开放集视觉概念,从而进一步实现向下游任务的零样本转移。具体来说,视觉语言模型由图像编码器和文本编码器两部分组成。当出现新的分类任务时,可以通过将类的自然语言描述输入文本来作为文本编码器。然后,计算“分类器”与图像编码器生成的图像特征之间的相似度。
然而,将这些预训练的大规模视觉语言模型有效地应用于下游任务本身就存在挑战。最近的研究表明,“提示”是一种简单有效的方法[1],而设计一个合适的提示是一项非常重要的任务。它总是需要广泛的领域专业知识,并且需要大量的时间进行手动单词调优。通常,即使进行了大量调优,我们也不能保证获得的提示符对于下游任务来说是最优的。
最近关于视觉表征的提示学习的研究主要受到自然语言处理(NLP)中的一些提示调优方法的启发[6]-[8],例如具有代表性的CoOp[9]。这些方法提出了在提示中使用连续表示建模可学习上下文,然后在保持预训练参数固定的情况下,使用这些可学习提示以端到端方式训练模型。虽然这些方法取得了很大的成功,并显示出良好的性能,但它们只是为文本编码器学习提示。
从传统视觉识别的角度来看,典型的视觉模型大致可以分为特征提取模块和分类器模块。同样,将文本提示输入文本编码器的过程可以看作是分类器的综合,并且用图像编码器提取图像特征。 我们认为大规模预训练的视觉语言模型已经捕获了下游任务的大部分一般知识(视觉概念)。提示机制的作用是从预训练的模型中查询到适合下游任务的信息。如图1所示,对于具有多个视觉对象(概念)的输入图像,例如第一种情况包含一个人和一辆摩托车,图像编码器提取对象的所有视觉特征,即Zero-Shot CLIP和CoOp的注意图同时突出了人和摩托车。然而,下游任务要求输出类标签为“motorbike”——ground-truth注释。CoOp试图在保持给定的高亮“人”和“摩托车”视觉特征不变的情况下,通过单独调整“分类器”使模型输出“摩托车”。在视觉社区中有一个共识,那就是功能很重要[10]!因此,我们认为仅对文本编码器进行即时调整,而直接使用固定图像编码器进行下游任务是次优的。在本文中,我们在图像输入空间中引入了视觉提示,并提出了一种双模态提示调整(DPT)范式,通过同时学习文本和图像编码器的文本提示和视觉提示,从而通过调整“分类器”和“视觉特征”使预训练模型适应下游任务。
图1所示。图像编码器的注意图的可视化。(a)原始图像。(b)零射击CLIP/CoOp。(c)我们的DPT。图片选自牛津宠物和加州理工大学101。GT注释对象用红色框标记。
具体来说,对于基于vit的图像编码器中的视觉提示调谐,我们在保持预训练图像编码器固定的同时,在transformer的输入中引入少量可训练参数。插入可视提示可以直接调整图像补丁令牌嵌入。图像特征,通过自关注权值和吸收提示衍生的值向量。为了使预训练模型更好地转移到下游任务,我们进一步在DPT框架中引入了类感知视觉提示调谐(CAVPT)机制,以帮助最终获得的图像特征更集中于目标视觉概念。因此,我们的目标是将任务相关信息和视觉实例信息同时编码到视觉提示中,类感知的视觉提示是通过文本提示特征和视觉图像补丁嵌入之间的交叉关注来动态生成的,有望包含目标视觉对象更丰富的语义特征。因此,通过吸收图像补丁嵌入和我们的类件可视化提示信息来计算最终获得的图像特征,可以更专注于下游任务对应的类。最后,建议的总体DPT范例是通过文本提示、视觉提示和类感知的视觉提示同时学习的。如图1所示,使用我们的DPT调优预训练模型显示了一个更集中的任务感知视觉注意区域。
•提出的方法展示了一种新的双模态提示调整范式,通过同时从文本和图像编码器的末端学习视觉和文本提示来调整大型预训练的视觉语言模型。
•为了鼓励可视化提示显式地包含与下游任务相关的信息,我们进一步在DPT中引入了类感知的可视化提示。它是通过在文本提示功能和视觉标记嵌入之间执行交叉注意来动态生成的。
•在11个数据集上的大量实验结果证明了所提出方法的有效性,并显示了其与其他提示调优方法的巨大优势,以及其泛化能力。
本文的其余部分组织如下。第二部分介绍了相关工作。第三节详细阐述了我们提出的方法。在第四节中,我们报告了在11个数据集上进行的综合实验结果,证明了我们的方法的有效性。最后,第五节对我们的工作进行了总结。
3.方法
在本节中,我们首先回顾CLIP模型。然后,我们详细阐述了所提出的双模态提示调优(DPT)范式的每个组件,包括文本提示、视觉提示和类感知视觉提示。我们提议的DPT的框架如图2所示。最后,我们给出了DPT的损失函数和预热策略来加速训练过程。
A.对比语言图像预训练(CLIP)模型
CLIP模型旨在对齐图像特征空间和文本特征空间,使模型具有向下游任务的零射击转移的能力。CLIP由两个编码器组成:一个是为图像设计的,另一个是为文本设计的。文本编码器采用变压器[51]对文本信息进行编码,图像编码器可以是CNN模型,如ResNet[5],也可以是视觉变压器,如ViT[52]。在我们的方法中,为了兼容[23]中的视觉提示,我们选择了ViT作为图像编码器。
CLIP拥有4亿对图像文本样本,在对比学习框架下进行训练,其中将关联的图像和文本作为正样本,而将非关联样本作为负样本。之后,预训练的CLIP模型的所有参数被冻结,用于下游任务,不进行任何微调。在下游任务中,通过嵌入目标数据集的类名,将手工制作的提示输入文本端,以合成零射击线性分类器。
以分类任务为例,“[CLASS]”令牌可以先通过模板进行扩展,如“一张[CLASS]的照片”。然后,将该句子视为提示符,并由文本编码器进行编码,以导出权重向量,其中K为类别的总数。同时,图像编码器获得图像特征x。预测概率可由

其中sim(·,·)表示余弦相似度的计算,τ为CLIP
B.文本提示和视觉提示
文本提示
众所周知,为CLIP模型手工制作提示可能需要相当长的时间,并且需要专业的单词调优,因为措辞上的细微变化可能会导致显著的性能下降。CoOp[9]受NLP模型的提示调优的启发,引入了一组可调词嵌入向量来学习对文本端的机器有利的提示,我们称之为文本提示。设表示M个可学习的上下文向量,文本类令牌的词嵌入用
;然后是第i类别的提示可以表示为
。通过将
转发到文本编码器g(·)中,我们可以得到第i个视觉概念的分类权向量。相应的预测概率可由
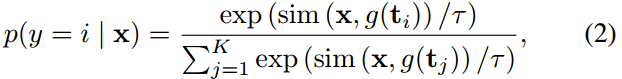
式中,x表示提取的图像特征,g(·)表示文本编码器。
视觉提示
对于视觉语言模型,有两个用于视觉和语言模态的编码器。仅调优文本提示不足以缩小预训练任务和下游任务之间的差距,从而导致次优结果。受视觉提示微调(visual prompt tuning, VPT)[23]的启发,我们在CLIP模型的图像编码器中引入了视觉提示。首先将图像patch嵌入到d维潜在空间中,如下所示:
![]()
设分别表示第i个transformer层的图像贴片嵌入集合和视觉提示集合。假设
是图像编码器中的可学习类令牌,与文本提示中使用的文本类令牌不同,后者是与类别相关的词嵌入。在[23]中有两种版本的视觉提示,VPT-Shallow和VPT-Deep。我们从经验上发现,VPT-Deep可以获得更好的性能(见表1),因此我们在第四节中将VPT-Deep纳入我们的实现中。

每个transformer层都引入了视觉提示,即:
![]()
一般来说,表现与提示深度呈正相关。因此,我们在模型中使用了VPT-Deep。然后用线性投影层LP对进行投影,得到最终的图像特征。为简单起见,图像特征提取的整个过程可以表示为
![]()
式中f(·)为图像编码器。
需要注意的是,图像编码器的计算过程,即ViT模型,可以看作是一个全局场景推理的过程,它将图像patch嵌入中的视觉概念逐层池化。借助视觉提示,通过各变压器层的自关注操作,可以在sl中进一步突出下游任务对应的目标视觉概念。通过在每个变压器层中插入视觉提示,可以通过两种方式影响的自注意操作,因为键和值都是通过视觉提示预先添加的:1)可以影响注意权重,使sl更多地集中在包含目标概念的图像补丁嵌入上;2)视觉提示也是自注意操作的价值向量,因此sl可能会吸收视觉提示学习到的额外信息。
然而,朴素的视觉提示被设计为无约束的可学习向量,它们只能通过对下游任务数据集的提示进行调优来隐式地学习一些下游任务相关的信息。在这项工作中,我们提出了类感知视觉提示调优(CAVPT),通过利用来自文本端的任务相关信息和来自视觉端的实例相关信息来生成视觉提示。
C.类感知视觉提示调优
类感知的视觉提示旨在显式地编码与任务相关的信息。我们的CAVPT生成器接受两方面的输入,即来自视觉方面的实例信息和来自文本方面的任务相关信息。文本编码器使用所有文本类令牌计算出的文本提示特性很好地表示了与任务相关的信息。
然而,当我们将带有所有文本类令牌的文本提示特征输入到CAVPT生成器中时,CAVPT生成器的计算复杂度随着每个下游任务上的类数量线性增加。为了将我们的CAVPT生成器的计算复杂性降低为常数,我们借助Zero-Shot CLIP Inference模块(图2的右侧)选择文本提示特征。请注意,最终性能对
不敏感,当设置不同的
时,最终性能仅波动0.1% ~ 0.2%。然后,将
文本类令牌[class]的文本提示输入文本编码器,生成
特征向量,即
,其中编码任务相关信息。
图2所示。我们提出的DPT方法的总体体系结构。它由三个可学习的组件组成:文本提示、视觉提示和由类感知视觉提示调优(CAVPT)生成器模块生成的类感知视觉提示,其详细架构如图3所示。
通过在来自文本端的文本提示特性和来自可视端的变压器块的输入之间执行交叉关注,动态地生成一个类感知的可视提示,如图3所示。
图3所示。所建议的类感知可视化提示调优(CAVPT)生成器模块的详细体系结构。
对全连通层进行映射后,可得到查询向量
。关键向量和值向量
均来自于相应的视觉变换层的输入,包括图像patch嵌入、图像类令牌嵌入、视觉提示(n为其总数)。我们提出的第l层的类感知视觉提示符
计算为
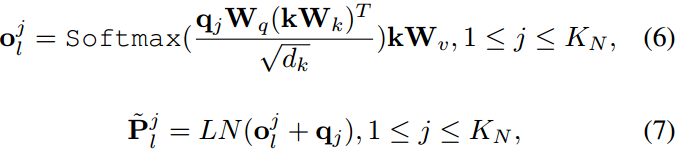
式中LN(·)表示层归一化。为交叉关注参数。
为了保证类感知视觉提示的效果,我们在LN层的KN输出上额外引入K-way分类器,并对K-way logits进行交叉熵损失,如下所示:
其中为
分类的第i个logit, K为类数,y为对真目标类的one-hot编码。注意,只有从
派生的
(对应于ground-truth目标类)将被分类。
由于嵌入更深层次的图像类令牌通常包含更多与任务相关的语义信息,因此在我们的实现中,类感知视觉提示仅应用于图像编码器的最后几层。
D.DPT的训练
采用交叉熵损失最小化ground-truth注释与式(2)计算的预测概率之间的距离。
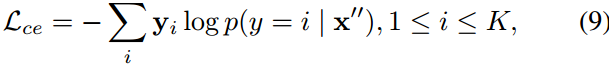
式中,y为真值标注,为式(2)的预测概率,x”为最终得到的图像特征,
![]()
总损失函数将两个交叉熵损失与一个平衡超参数α结合如下:
![]()
E.温和策略
为了加速训练过程,我们在训练的前几个阶段采用了一般知识引导的热身策略。考虑到CLIP模型存储了一般知识,我们训练我们的模型学习零样本CLIP。我们在前几个epoch使用的损失函数可以描述如下:
![]()
其中是用于CoOp训练的损失函数,
是用于VPT训练的损失函数,
是用于VLP训练的损失函数。β是一个平衡超参数。对于
,我们使用交叉熵损失来最小化ground-truth注释与由式(2)计算的预测概率之间的距离。
![]()
对于,预测概率由式(1)代替式(2)计算。
![]()
通过将训练前几次的损失函数转化为式(12),我们利用一般知识指导热身过程。在训练过程中,本文提出的DPT在对文本提示、视觉提示和生成类感知视觉提示的参数进行优化的同时,保持图像和文本编码器的整个参数不变。
F.关于CAVPT的讨论
图3给出了所提出的类感知可视化提示的详细计算过程。如图3所示,CAVPT生成器接受两种类型的输入。来自文本端的文本提示功能包括任务相关信息,而来自图像端的图像补丁嵌入表示可视化实例信息。首先,CAVPT生成器在文本提示特征和图像补丁嵌入之间进行交叉关注,其中从文本提示特征映射查询向量,而从图像补丁嵌入派生键和值。通过交叉注意操作,那些包含更多语义信息的图像补丁嵌入将更加突出,这些图像补丁嵌入属于下游任务类的对象。因此,交叉注意的输出将包含更多的ground-truth对象的特征。然后,我们的类感知的可视化提示被进一步生成,附带一个类似于典型转换器层的“添加和规范”操作。由于我们的类感知视觉提示包含了更丰富的ground-truth目标对象的语义特征,因此通过吸收图像补丁嵌入和我们的类感知视觉提示的信息计算得到的最终图像特征可以更集中于下游任务对应的类。
4.实验
A.数据集和实现细节
为了评估我们方法的有效性,我们在11个分类数据集上进行了实验,分别是EuroSAT[53]、Caltech101[54]、OxfordFlowers[55]、Food101[56]、fgvc - aircraft[57]、DTD[58]、OxfordPets[59]、StanfordCars[60]、ImageNet1K[61]、Sun397[62]和UCF101[63],如[1]、[9]所示。这些数据集涵盖了广泛的计算机视觉任务,包括通用对象的图像分类,细粒度分类,卫星,纹理,场景理解和动作识别图像。
遵循CLIP中常用的少枪评估方案[1],我们也采用1、2、4、8和16枪进行模型训练,并在完整的测试数据集上进行测试。为了公平比较,报告的结果是三次运行的平均值。
所有实验均采用viti - base /32作为骨干网。所有实验均基于CoOp[9]和CLIP[1]的官方发布代码进行。对于VPT,每层网络的提示符长度设置为10,初始化方式与CoOp中的文本提示符相同[9]。在模型训练过程中,我们采用SGD优化方法,学习率采用余弦规则衰减。VPT的最大历元与CoOp相同[9]。在前10个epoch采用热身技术,在VPT上固定学习率为10−5。首先在{0.01,0.001,0.0001,0.00001}中搜索VPT的学习率,所有实验的视觉提示保持不变。对于文本提示,我们遵循CoOp[9],上下文长度为16。
对于我们提出的VLP和DPT方法,除了DPT中的Caltech101和OxfordPets,在16/8/4/2次拍摄时,最大epoch数设置为100,1次拍摄时最大epoch数设置为60 (ImageNet的最大epoch数设置为20),DPT中的Caltech101和OxfordPets在16次拍摄时设置为60。预热技术与CoOp和VPT中相同(两端ImageNet的预热epoch设置为1)。KN设置为10。将CAVPT插入到图像编码器的最后一层。
平衡α设为0.3,β设为0.1。对于VLP和DPT的早期训练,使用一般知识作为前30个epoch (ImageNet为10个epoch)的指导。
B.与现有方法的比较
现有具有代表性的提示调优方法包括著名的CoOp方法[9],以及用于零弹分类的CLIP模型[1]本身(即zero-shot CLIP)。因此,我们采用这两种模型作为我们的主要比较方法。
由于与CoOp中单独的文本提示相比,我们的DPT额外引入了视觉提示和类感知的视觉提示,为了揭示每种成分对性能改进的贡献,我们在DPT之外额外实现了VPT和VLP,具体如下:•VPT标准用于将单纯的视觉提示单独引入CLIP模型的视觉端[1]并手工制作文本端采用文字提示,例如“一张[班级]的照片”。
•VLP表示同时学习视觉(V)和文本(L)提示符的双模态提示调优范式,其中文本提示符的设计方式与CoOp[9]相同,视觉提示符与VPT[23]中的VPT- deep完全相同。
•DPT表示我们将CAVPT进一步集成到基于VLP的图像编码器中。
总体评估结果如图4所示,报告了所有few-shot设置下11个数据集的分类准确率。与基线方法相比,我们的DPT在11个数据集上的平均性能优于基线方法。图4和表1清楚地显示了以下内容:1)DPT大大优于CoOp和零射击CLIP。性能的提高基本上与射击次数成正比。具体来说,在11个数据集的16发射击设置下,DPT比零射击CLIP平均高出17.6%,比CoOp平均高出3.53%。结果验证了所提出的DPT范式的优越性。
2) VPT与CoOp的结果比较,VPT的平均效果优于CoOp。在16次射击设置下,VPT在所有11个数据集上平均可以获得1%的性能提升。结果表明,从图像端调优视觉提示而不是文本提示可以获得更有效的结果。值得注意的是,VPT和CoOp在不同的数据集上得到的结果不一致,这表明调优视觉提示和文本提示可能具有互补的效果。3)将VLP与VPT和CoOp的结果进行比较,VLP的效果优于VPT和CoOp,这表明对下游任务的双模态提示进行视觉和文本两端的调优明显优于对任何单模态提示进行调优。4)在类感知视觉提示的帮助下,我们的DPT的结果与VLP相比有明显的提高。具体而言,在16次射击设置下,DPT在11个数据集上平均比VLP获得1%的性能提升,这表明我们的CAVPT具有重要意义。

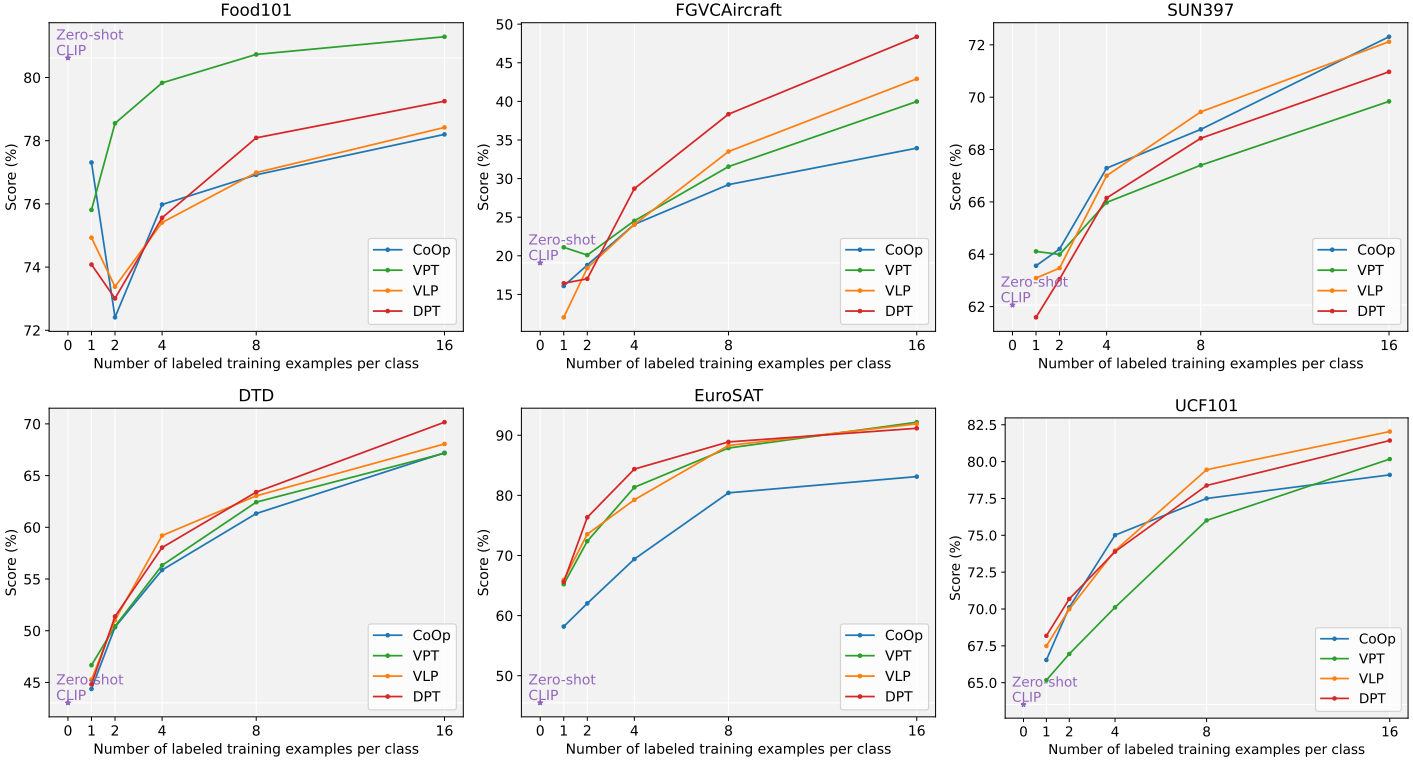
图4所示。1、2、4、8、16个镜头在11个数据集上的主要结果,vitb /32。注意,我们还将我们的方法与CPT[33]在平均准确率上进行了比较。
C.域泛化
在本节中,我们的目标是揭示与基线方法相比,我们的方法对分布位移的鲁棒性。
数据集
按照CoOp[9]中的设置,我们使用ImageNet作为源数据集。目标数据集为ImageNetV2[64]、ImageNet-Sketch[65]、ImageNet-A[66]、ImageNet-R[67]。
设置
我们选择CoOp和VPT作为我们的基准方法。三种方法均在源数据集上进行训练,每类训练1个样本,在目标数据集上进行零射击推理。
结果
如表三所示,我们的方法在ImageNet、ImageNetV2、ImageNetSketch和ImageNet- r上达到了最好的性能,而我们的方法在ImageNet- a上的效果较差,因为ImageNet- a包含自然的对抗性样例。这表明我们的方法比基线方法具有更强的鲁棒性,但与CoOp相比,在面对对抗性示例时往往更脆弱。相比之下,VPT模型在目标数据集上得到的结果较差,这表明VPT模型的鲁棒性不如CoOp和我们的方法。
D.进一步分析
AVPT插入深度分析
CAVPT是一个即插即用模块,可用于ViT骨干的任意层。为了研究最适合CAVPT的层,我们在所有11个数据集上进行了自底向上和自顶向下两种不同深度值的综合实验,即自顶向下为{1→12,4→12,8→12,12},自下而上为{1,1→4,1→8,1→12},在VLP模型之上。另外,通过共享CAVPT参数,以自顶向下的方式进行了跨层共享CAVPT的实验设置。如图6所示,自顶向下方式的结果要比自底向上方式的结果好得多,并且Transformer的最后一层是最适合CAVPT的层,这表明CAVPT在更深的层中起着更重要的作用。此外,通过比较共享CAVPT和普通CAVPT,共享CAVPT可以在参数较少的情况下获得稍好的结果。
CAVPT长度分析
为了探讨合适的CAVPT长度,我们对不同长度的CAVPT进行了综合实验,即:{0,1,5,10,20,50,100}。长度为0表示该方法退化为VLP,但在ViT骨干的最后一层没有可视提示。对于一些数据集,以EuroSAT[53]为例,它只包含10个类,不足以获得10个以上的cavpt。因此,当所需的cavpt数量大于类的个数,我们将类的个数作为CAVPT的长度,得到相应的结果。如表5所示,将长度设置为10可以获得最佳精度。

E.注意图的可视化

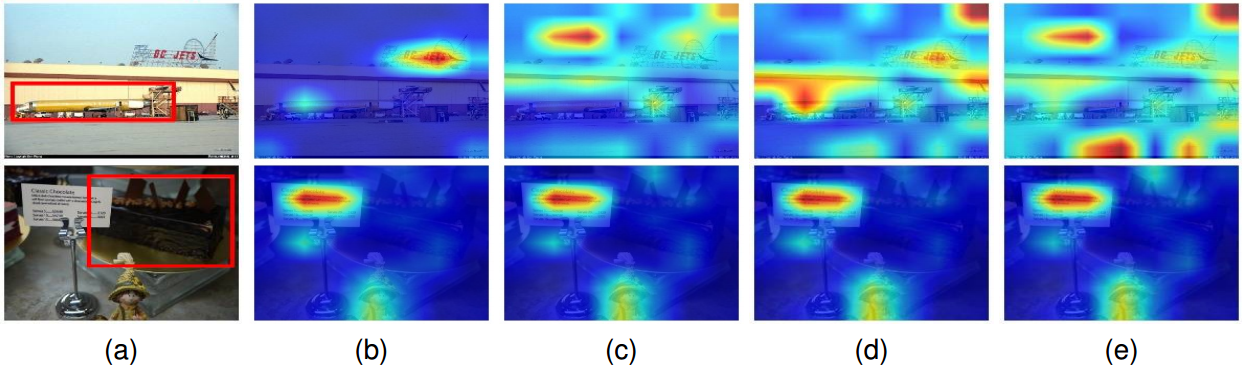
图7所示。不同注意图可视化方法的比较。(a)原始图像。(b)零射击CLIP/CoOp。(c) VPT-Deep。(d)车牌区域。DPT (e)。GT注释对象用红色框标记。最后两行是模型未能关注GT注释对象的失败情况。
结论
在本文中,我们提出了一种新的双模态提示调整范式,通过同时学习视觉和文本提示,将大型预训练的视觉语言模型调整到下游任务。为了使最终获得的图像特征更集中于目标视觉概念,我们进一步将下游任务相关信息和图像实例信息编码到视觉提示中,并提出了类感知的视觉提示,通过文本提示特征和图像标记嵌入之间的交叉关注动态生成。在11个数据集上的大量实验结果证明了该方法的有效性,并显示了其与其他快速调优方法的巨大优势。
参考资料
论文下载
https://arxiv.org/pdf/2208.08340.pdf
https://arxiv.org/pdf/2208.08340v2.pdf
https://arxiv.org/abs/2208.08340v4
代码地址
GitHub - fanrena/DPT: The official implementation of paper Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model. If you find our code or paper useful, please give us a citation.
这篇关于论文解读:(CAVPT)Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




