vision专题

复盘高质量Vision Pro沉浸式视频的制作流程与工具
在探索虚拟现实(VR)和增强现实(AR)技术的过程中,高质量的沉浸式体验是至关重要的。最近,国外开发者Dreamwieber在其作品中展示了如何使用一系列工具和技术,创造出令人震撼的Vision Pro沉浸式视频。本文将详细复盘Dreamwieber的工作流,希望能为从事相关领域的开发者们提供有价值的参考。 一、步骤和工作流 构建基础原型 目的:快速搭建起一个基本的模型,以便在设备

一键部署Phi 3.5 mini+vision!多模态阅读基准数据集MRR-Benchmark上线,含550个问答对
小模型又又又卷起来了!微软开源三连发!一口气发布了 Phi 3.5 针对不同任务的 3 个模型,并在多个基准上超越了其他同类模型。 其中 Phi-3.5-mini-instruct 专为内存或算力受限的设备推出,小参数也能展现出强大的推理能力,代码生成、多语言理解等任务信手拈来。而 Phi-3.5-vision-instruct 则是多模态领域的翘楚,能同时处理文本和视觉信息,图像理解、视频摘要

HOW DO VISION TRANSFORMERS WORK
HOW DO VISION TRANSFORMERS WORK Namuk Park1,2, Songkuk Kim1 1Yonsei University, 2NAVER AI Lab{namuk.park,songkuk}@yonsei.ac.kr 总结 MSA 改善模型泛化能力: MSA 不仅提高了模型的准确性,还通过平滑损失景观来提高泛化能力。损失景观的平坦化使得模型更容易优化,表现

在Vision Pro上实现360度全景视频播放:HLS360VideoMaterial框架介绍
随着Apple Vision Pro的推出,空间计算技术正在变得越来越普及,而360度全景视频则是其中一种令人兴奋的应用形式。对于希望在visionOS平台上集成360度视频流的开发者而言,找到合适的工具和框架至关重要。今天,我们要介绍的正是这样一个框架——HLS360VideoMaterial,它可以帮助你在Vision Pro上轻松实现360度全景视频的播放,并支持二次开发,让你的应用更上一层

Vision Transformer (ViT) + 代码【详解】
文章目录 1、Vision Transformer (ViT) 介绍2、patch embedding3、代码3.1 class embedding + Positional Embedding3.2 Transformer Encoder3.3 classifier3.4 ViT总代码 1、Vision Transformer (ViT) 介绍 VIT论文的摘要如下,谷歌
![【课程笔记】谭平计算机视觉(Computer Vision)[5]:反射和光照 - Reflectance Lighting](https://i-blog.csdnimg.cn/blog_migrate/605975d30e1d112f02269197ccfca1e1.png)
【课程笔记】谭平计算机视觉(Computer Vision)[5]:反射和光照 - Reflectance Lighting
课程链接(5-1): 课程链接(5-2): radiance的影响因素(辐射强度) 光源 材质、反射 局部形状 反射 计算机视觉中主要考虑反射 BRDF(Bi-directional reflectance distribution function) BRDF假设(local assumption):反射只和此点接收到的光有关,忽略了半透明、荧光等 这个假设导致依靠BRDF模型建立的人皮
![【课程笔记】谭平计算机视觉(Computer Vision)[4]:辐射校准高动态范围图像 - Radiometric Calibration HDR](https://i-blog.csdnimg.cn/blog_migrate/7972a564ea1c037d7366163813d67ddb.png)
【课程笔记】谭平计算机视觉(Computer Vision)[4]:辐射校准高动态范围图像 - Radiometric Calibration HDR
视频地址链接 预备知识 radiance:单位面积单位时间单位方向角发出去的能量 irradiance:单位:功率/平方米;单位面积单位时间接收的能量 ISP: image signal processor 白平衡:人眼会自动滤过白炽灯、日光灯、节能灯下对物体的附加颜色,然而相机没有此功能,因此相机具有矫正功能。 vignetting:对于白墙拍照,一般是中间亮周边暗。边缘上光线散开的效果,

【王树森】Vision Transformer (ViT) 用于图片分类(个人向笔记)
图片分类任务 给定一张图片,现在要求神经网络能够输出它对这个图片的分类结果。下图表示神经网络有40%的信心认定这个图片是狗 ResNet(CNN)曾经是是图像分类的最好模型在有足够大数据做预训练的情况下,ViT要强于ResNetViT 就是Transformer Encoder网络 Split Image into Patches 在划分图片的时候,需要指定两个超参数 patch siz

论文泛读: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
文章目录 TransNeXt: Robust Foveal Visual Perception for Vision Transformers论文中的知识补充非QKV注意力变体仿生视觉建模 动机现状问题 贡献方法 TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文链接: https://o
VLM 系列——phi3.5-Vision——论文解读
一、概述 1、是什么 论文全称《Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone》 是一系列大型语言模型(LLM) & 多模态大型语言模型(MLLM)。其中LLM包括phi-3-mini 3.8B、phi-3-small 7B、phi-3-medium 14B,phi-3-mini

探讨Vision Pro的成本优化与设计改进之路
随着Apple Vision Pro的发布,这款革命性的头戴式显示设备凭借其创新技术和用户体验吸引了大量关注。然而,高昂的价格成为了一个不可忽视的问题,阻碍了它的普及。为了让更多消费者能够负担得起这款产品,Apple需要探索各种方法来降低成本而不牺牲用户体验。本文将总结一些关于如何降低Vision Pro成本和优化设计的讨论点。 一、潜在的成本削减措施 **材质更换:**采用聚碳酸

LaViT:Less-Attention Vision Transformer的特性与优点
引言 https://arxiv.org/pdf/2406.00427 随着计算机视觉领域的发展,视觉Transformer(ViTs)逐渐成为一项重要技术。尽管ViTs在捕捉图像中的长距离依赖关系方面表现出色,但其沉重的计算负担和潜在的注意力饱和问题一直是实际应用的障碍。为解决这些问题,微软提出了Less-Attention Vision Transformer(LaViT),旨在通过引入一种

全局上下文视觉转换器(Global Context Vision Transformers)
摘要 https://arxiv.org/pdf/2206.09959 我们提出了全局上下文视觉转换器(GC ViT),这是一种新颖的架构,旨在提高计算机视觉中的参数和计算利用率。我们的方法利用全局上下文自注意力模块与标准的局部自注意力相结合,以有效且高效的方式对长程和短程空间交互进行建模,而无需执行昂贵的操作,如计算注意力掩码或移动局部窗口。此外,我们还解决了ViT中归纳偏差缺失的问题,并提出

Vision Pro在B端市场的应用前景及行业分析
苹果公司推出的Vision Pro是一款开创性的头戴式显示设备,旨在将虚拟现实(VR)和增强现实(AR)技术融入日常生活。然而,对于企业用户而言,该设备的应用前景如何?本文将基于一组调研数据,探讨Vision Pro在B端市场的应用潜力,并为创业者提供行业建议。 一、总体市场反应 根据IDC的最新调查报告,目前只有35%的企业对Vision Pro表现出“非常感兴趣”或“有些感兴趣”的态度
![[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割](https://i-blog.csdnimg.cn/direct/d32a0be7130540f293c4066cc9f1ccf5.png#pic_center)
[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割
[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割’ 论文地址 - https://arxiv.org/pdf/2310.07781 0. 摘要 医学图像分割在推进医疗保健系统的疾病诊断和治疗计划中起着至关重要的作用。U 形架构,俗称 U-Net,已被证明在各种医学图像分割任务中非常成功。然而,U-Net 基于卷积的操作本身限制了其有效建模

豆包模型能力大幅提升,中国版Vision Pro正式发布!今年大模型市场份额第一还会是百度吗?|AI日报
文章推荐 上线一天销售额超15亿!《黑神话:悟空》火爆全网的技术秘诀! 昆仑万维推出全球首款AI短剧平台SkyReels!中国首个接入大模型Linux开源操作系统正式发布!|AI日报 今日热点 IDC首次发布大模型平台及应用市场份额报告,百度、商汤、智谱排名前三 国际数据公司(IDC)于8月21日首次发布了《中国大模型平台市场份额,2023:大模型元年 —— 初局》。 数据显示,202
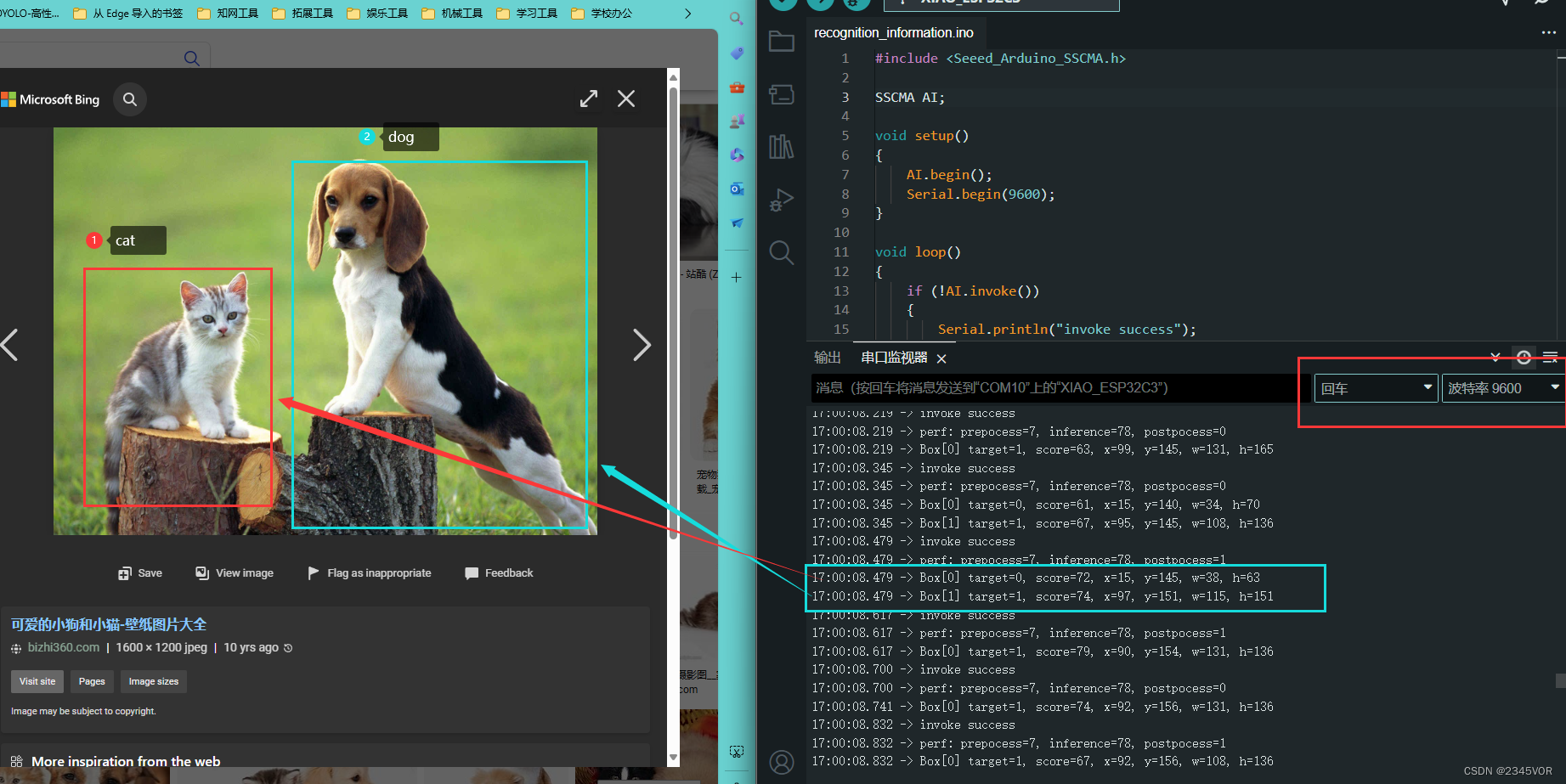
【Vision AI v2开箱之SenseCraft AI猫狗识别Arduino教程】
【Vision AI v2开箱之SenseCraft AI猫狗识别Arduino教程】 1. 前言2. 实验材料2.1 Grove Vision AI Module V22.1.1 特征2.1.2 硬件概述2.1.3 启动/重置/程序2.1.4 驱动 2.2 ESP32C32.2.1 引脚图2.2.2 组件概述2.2.3 电源引脚 2.3 SenseCraft AI Model Assist

Vision Pro的3D跟踪能力:B端应用的工作流、使用教程和经验总结
Vision Pro的最新3D跟踪能力为工业、文博、营销等多个B端领域带来了革命性的交互体验。本文将详细介绍这一功能的工作流、使用教程,并结合实际经验进行总结。 第一部分:工作流详解 一、对象扫描 使用Reality Composer iPhone应用程序对目标对象进行3D扫描,如吉他或雕塑,生成精确的3D模型。 二、模型训练 工具:CreateML训练数据:以Reality
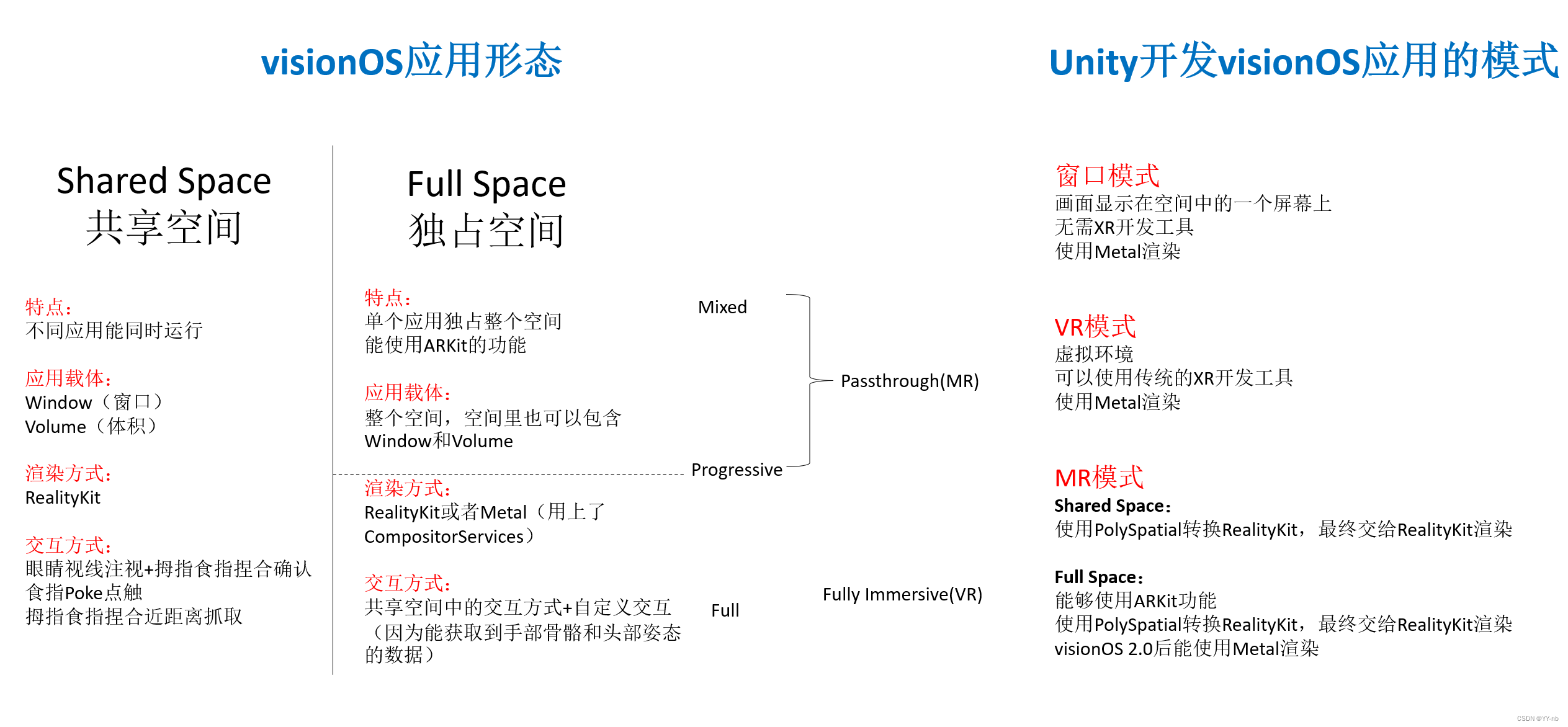
Unity Apple Vision Pro 开发(三):visionOS 应用形态
文章目录 📕教程说明📕常用名词解释📕visionOS 空间类型⭐Shared Space 共享空间⭐Full Space/Immersive Space 独占空间 📕visionOS 渲染框架📕Unity 开发 visionOS 应用的不同模式⭐**窗口模式**⭐VR 模式⭐MR 模式 📕总结 此教程相关的详细教案,文档,思维导图和工程文件会放入 Spatial XR

基于Pytorch框架的深度学习Vision Transformer神经网络蝴蝶分类识别系统源码
第一步:准备数据 6种蝴蝶数据:self.class_indict = ["曙凤蝶", "麝凤蝶", "多姿麝凤蝶", "旖凤蝶", "红珠凤蝶", "热斑凤蝶"],总共有900张图片,每个文件夹单独放一种数据 第二步:搭建模型 本文选择一个Vision Transformer网络,其原理介绍如下: Vision Transformer(ViT)是一种基于Transformer架

详解HDR的三个标准——HLG/HDR10/Dolby Vision
HDR的三大标准:HLG(Hybrid Log Gamma);HDR10;Dolby Vision HLG:HLG的全称是Hybrid Log Gamma,它是由英国BBC和日本NHK电视台联合开发的高动态范围HDR的一个标准。HLG不需要元数据,能后向兼容SDR,相比HDR10,它的画面即使在现有的SDR显示设备上,也能呈现得更加艳丽动人 HDR 10:HDR10,2015年8月27

AI生图提示词收集,/MJ/SD/DALL-E/VISION...
#摄影构图与角度Prompt关键词参考来源: https://www.studiobinder.com/blog/ultimate-guide-to-camera-shots/ https://ehowton.livejournal.com/933195.html 距离相关提示词 • extreme close-up(极近景)• close-up(近景)• medium close-up(

京东618 :AI总裁数字人、京东Apple Vision Pro版亮相
2004年6月18日,刚刚转型电商才半年的京东,用最互联网的方式为忠实粉丝打造了一场价格降到“难以置信”的店庆促销活动,这场促销活动还有一个很具有当年网络小说特质的名字——“月黑风高”。 2024年京东618,早已成为一场亿万消费者、千百万品牌和商家共同参与的年中经济盛事。20年来,京东通过供应链技术创新,帮助品牌和商家持续优化成本和效率,让用户体验到极致的“又便宜又好”,始终是这场经济盛事不变
Vision Transformer with Sparse Scan Prior
摘要 https://arxiv.org/pdf/2405.13335v1 In recent years, Transformers have achieved remarkable progress in computer vision tasks. However, their global modeling often comes with substantial computation
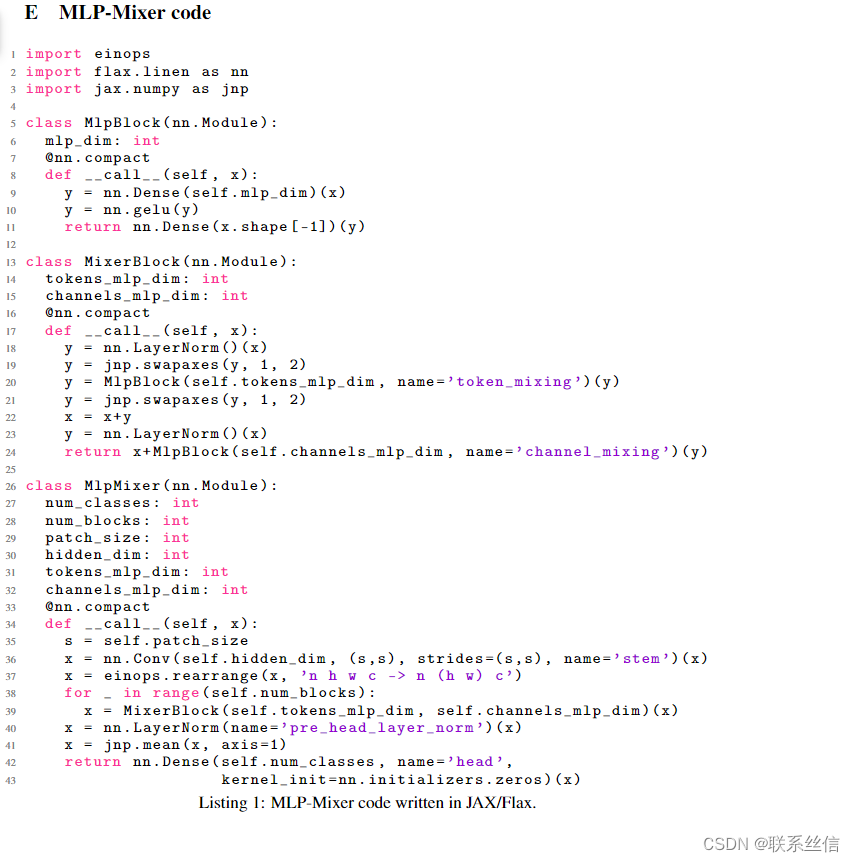
【模块缝合】【NIPS 2021】MLP-Mixer: An all-MLP Architecture for Vision
文章目录 简介代码,from:https://github.com/huggingface/pytorch-image-models【多看看成熟仓库的代码】MixerBlock paper and code: https://paperswithcode.com/paper/mlp-mixer-an-all-mlp-architecture-for-vision#code 简
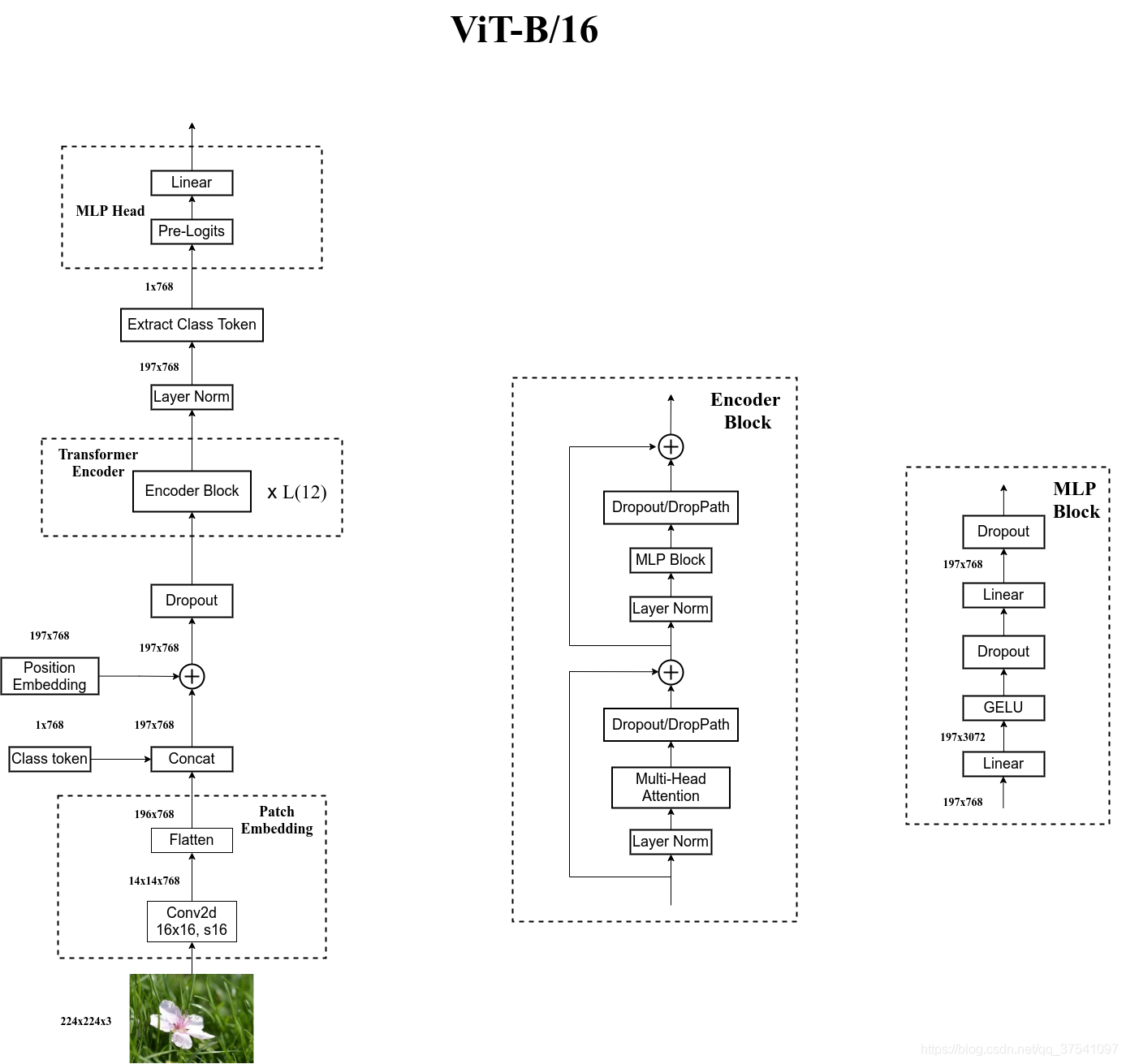
【深度学习】解析Vision Transformer (ViT): 从基础到实现与训练
之前介绍: https://qq742971636.blog.csdn.net/article/details/132061304 文章目录 背景实现代码示例解释 训练数据准备模型定义训练和评估总结 Vision Transformer(ViT)是一种基于transformer架构的视觉模型,它最初是由谷歌研究团队在论文《An Image is Worth 16x