本文主要是介绍基于Pytorch框架的深度学习Vision Transformer神经网络蝴蝶分类识别系统源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一步:准备数据
6种蝴蝶数据:self.class_indict = ["曙凤蝶", "麝凤蝶", "多姿麝凤蝶", "旖凤蝶", "红珠凤蝶", "热斑凤蝶"],总共有900张图片,每个文件夹单独放一种数据

第二步:搭建模型
本文选择一个Vision Transformer网络,其原理介绍如下:
Vision Transformer(ViT)是一种基于Transformer架构的深度学习模型,用于图像识别和计算机视觉任务。与传统的卷积神经网络(CNN)不同,ViT直接将图像视为一个序列化的输入,并利用自注意力机制来处理图像中的像素关系。
ViT通过将图像分成一系列的图块(patches),并将每个图块转换为向量表示作为输入序列。然后,这些向量将通过多层的Transformer编码器进行处理,其中包含了自注意力机制和前馈神经网络层。这样可以捕捉到图像中不同位置的上下文依赖关系。最后,通过对Transformer编码器输出进行分类或回归,可以完成特定的视觉任务。
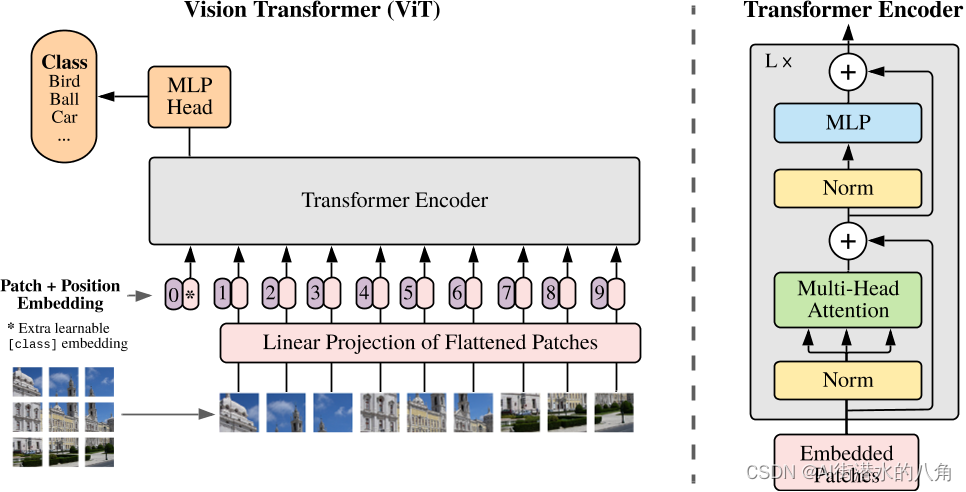
Vit model结构图
Vit的模型结构如下图所示。vit是将图像块应用于transformer。CNN是以滑窗的思想用卷积核在图像上进行卷积得到特征图。为了可以使图像仿照NLP的输入序列,我们可以先将图像分成块(patch),再将这些图像块进行平铺后输入到网络中(这样就变成了图像序列),然后通过transformer进行特征提取,最后再通过MLP对这些特征进行分类【其实就可以理解为在以往的CNN分类任务中,将backbone替换为transformer】。
第三步:训练代码
1)损失函数为:交叉熵损失函数
2)训练代码:
import os
import math
import argparseimport torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsfrom my_dataset import MyDataSet
from vit_model import vit_base_patch16_224_in21k as create_model
from utils import read_split_data, train_one_epoch, evaluatedef main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")if os.path.exists("./weights") is False:os.makedirs("./weights")tb_writer = SummaryWriter()train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),"val": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}# 实例化训练数据集train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"])# 实例化验证数据集val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"])batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=batch_size,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)model = create_model(num_classes=args.num_classes, has_logits=False).to(device)if args.weights != "":assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)weights_dict = torch.load(args.weights, map_location=device)# 删除不需要的权重del_keys = ['head.weight', 'head.bias'] if model.has_logits \else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias']for k in del_keys:del weights_dict[k]print(model.load_state_dict(weights_dict, strict=False))if args.freeze_layers:for name, para in model.named_parameters():# 除head, pre_logits外,其他权重全部冻结if "head" not in name and "pre_logits" not in name:para.requires_grad_(False)else:print("training {}".format(name))pg = [p for p in model.parameters() if p.requires_grad]optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=5E-5)# Scheduler https://arxiv.org/pdf/1812.01187.pdflf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosinescheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)for epoch in range(args.epochs):# traintrain_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch)scheduler.step()# validateval_loss, val_acc = evaluate(model=model,data_loader=val_loader,device=device,epoch=epoch)tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]tb_writer.add_scalar(tags[0], train_loss, epoch)tb_writer.add_scalar(tags[1], train_acc, epoch)tb_writer.add_scalar(tags[2], val_loss, epoch)tb_writer.add_scalar(tags[3], val_acc, epoch)tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=6)parser.add_argument('--epochs', type=int, default=100)parser.add_argument('--batch-size', type=int, default=4)parser.add_argument('--lr', type=float, default=0.001)parser.add_argument('--lrf', type=float, default=0.01)# 数据集所在根目录# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgzparser.add_argument('--data-path', type=str,default=r"G:\demo\data\Butterfly20")parser.add_argument('--model-name', default='', help='create model name')# 预训练权重路径,如果不想载入就设置为空字符parser.add_argument('--weights', type=str, default='./vit_base_patch16_224_in21k.pth',help='initial weights path')# 是否冻结权重parser.add_argument('--freeze-layers', type=bool, default=True)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()main(opt)
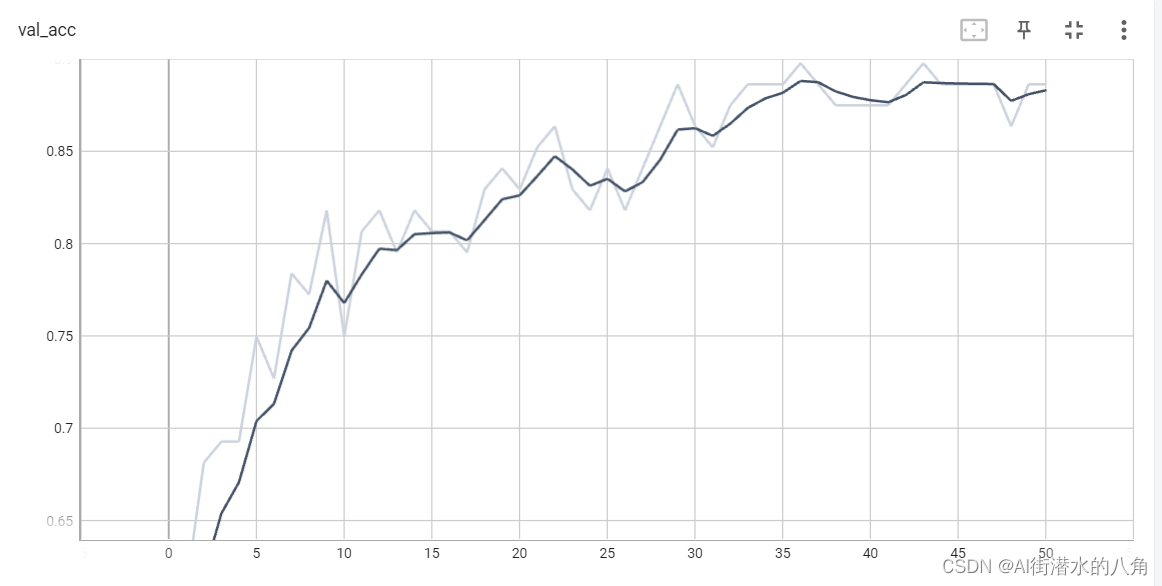
第四步:统计正确率
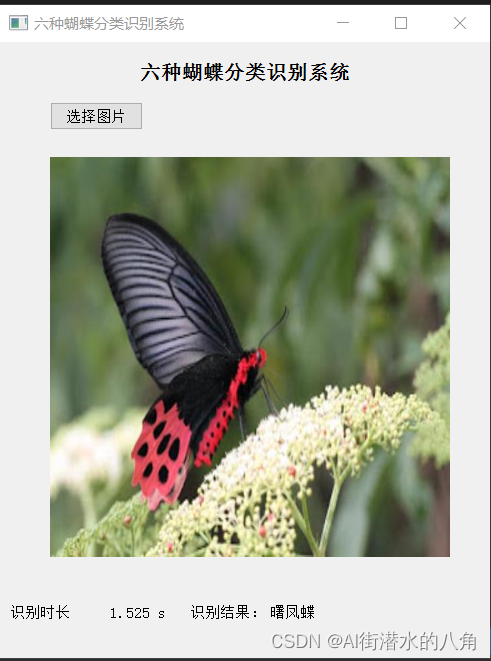
第五步:搭建GUI界面

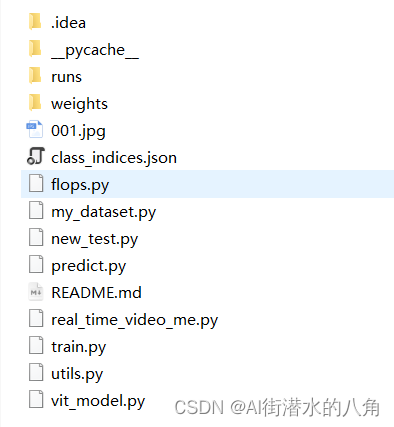
第六步:整个工程的内容
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码
代码的下载路径(新窗口打开链接):基于Pytorch框架的深度学习Vision Transformer神经网络蝴蝶分类识别系统源码

有问题可以私信或者留言,有问必答
这篇关于基于Pytorch框架的深度学习Vision Transformer神经网络蝴蝶分类识别系统源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







