trained专题

How to leverage pre-trained multimodal model?
However, embodied experience is limited inreal world and robot. How to leverage pre-trained multimodal model? https://come-robot.github.io/

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA

【Reading List】【20190510】预训练(pre-trained)语言模型
RNN,seq2seq,Attention: https://www.leiphone.com/news/201709/8tDpwklrKubaecTa.html 图解transformer : https://blog.csdn.net/qq_41664845/article/details/84969266 Attentinon: https://blog.csdn.net/male
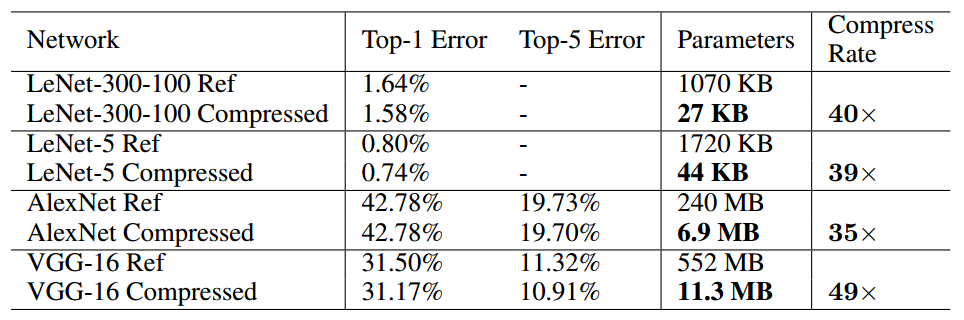
Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding
本次介绍的方法为“深度压缩”,文章来自2016ICLR最佳论文 《Deep Compression: Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding 转自:http://blog.csdn.net/shuzfan/article/details/51383809 (内含多
论文解读:(CAVPT)Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
v1文章名字:Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model v2文章名字:Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model 文章汇总 对该文的改进:论文解读:(VPT)Visual Prompt Tuning_vpt

Windows下运行Discriminatively Trained Deformable Part Models代码 Version 4
Windows下运行Discriminatively Trained Deformable Part Models代码 Version 4 Felzenszwalb的Discriminatively Trained Deformable Part Models URL:http://www.cs.brown.edu/~pff/latent/ 这是目前最好的object detect

【论文阅读】CodeBERT: A Pre-Trained Model for Programming and Natural Languages
目录 一、简介二、方法1. 输入输出表示2. 预训练数据3. 预训练MLMRTD 4. 微调natural language code searchcode-to-text generation 三、实验1. Natural Language Code Search2. NL-PL Probing3. Code Documentation Generation4. 泛化实验

AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——GPT 0. 前言1. GPT 简介2. 葡萄酒评论数据集3. 注意力机制3.1 查询、键和值3.2 多头注意力3.3 因果掩码 4. Transformer4.1 Transformer 块4.2 位置编码 5. 训练GPT6. GPT 分析6.1 生成文本6.2 注意力分数 小结系列链接 0. 前言 注意力机制能够用于构建先进的文本生成模型,Transfor

论文阅读——A Pre-trained Sequential Recommendation Framework Popularity Dynamics for Zero-shot Transfer
论文阅读——A Pre-trained Sequential Recommendation Framework: Popularity Dynamics for Zero-shot Transfer ’一个预训练的顺序推荐框架:零样本迁移的流行动态‘ 摘要: 在在线应用的成功中,如电子商务、视频流媒体和社交媒体,顺序推荐系统是至关重要的。虽然模型架构不断改进,但对于每个新的应用领域,我们仍然需

【持续学习系列(九)】《Continual Learning with Pre-Trained Models: A Survey》
一、论文信息 1 标题 Continual Learning with Pre-Trained Models: A Survey 2 作者 Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan 3 研究机构 National Key Laboratory for Novel Software Technolo
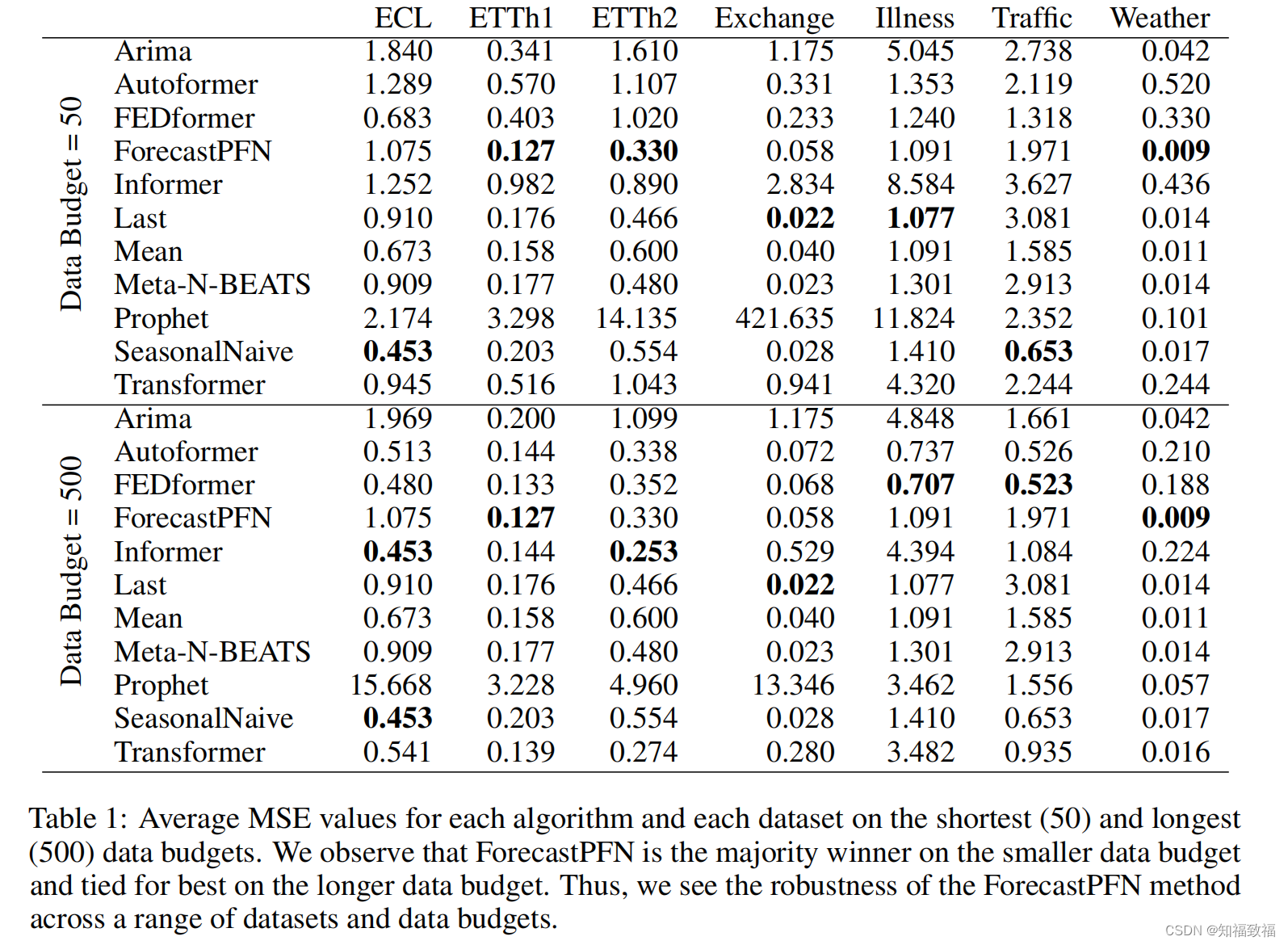
ForecastPFN: Synthetically-Trained Zero-Shot Forecasting
ForecastPFN: Synthetically-Trained Zero-Shot Forecasting 2023.11.3 arxiv 论文下载 源码 ForecastPFN(Prior-data Fitted Networks)是zero-shot场景的:经过初始预训练后,它可以对一个全新的数据集进行预测,而没有来自该数据集的训练数据。 这个文章比较偏统计,可能涉及到先验、贝叶斯相关

文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models
文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models 1. 文章简介2. 具体方法介绍 1. SoRA具体结构2. 阈值选取考察 3. 实验 & 结论 1. 基础实验 1. 实验设置2. 结果分析 2. 细节讨论 1. 稀疏度分析2. rank分析3. 参数位置分析4. 效率考察 4. 总结 & 思考 文献链接:https
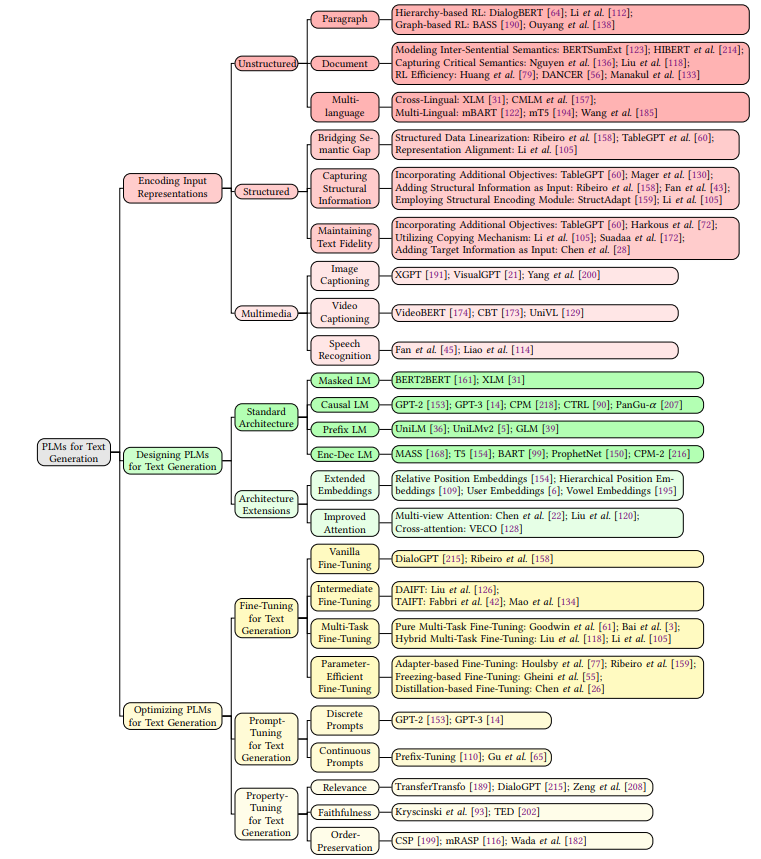
Pre-trained Language Models for Text Generation: A Survey
文章目录 一、简介二、准备工作2.1文本生成2.2 预训练语言模型2.3 基于PLMs的文本生成 三、编码输入表征3.1 非结构化输入3.1.1 段落表征学习3.1.2 文档表征学习3.1.3 多语言表征学习 3.2 结构化输入3.2.1 缩小语义鸿沟3.2.2 捕获结构信息3.2.3 保留文本真实度 3.3 多模态输入 四、设计文本生成的PLMs4.1 标准结构4.1.1 掩码语言模型(M
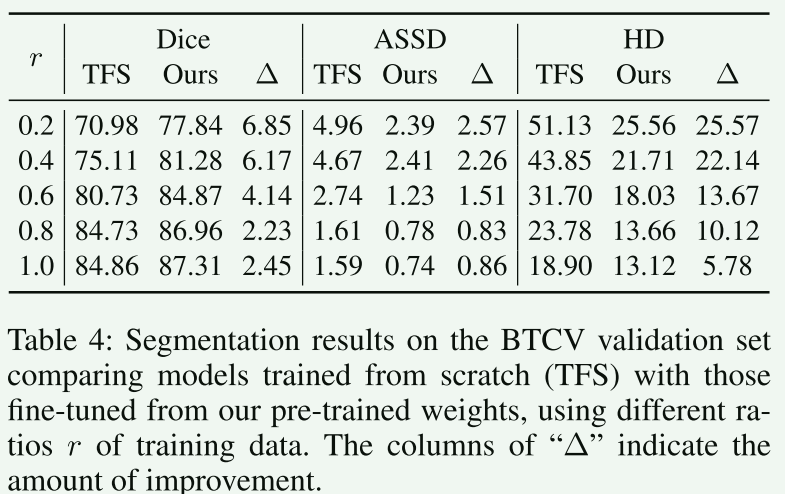
【论文阅读笔记】Pre-trained Universal Medical Image Transformer
Luo L, Chen X, Tang B, et al. Pre-trained Universal Medical Image Transformer[J]. arXiv preprint arXiv:2312.07630, 2023.【代码开源】 【论文概述】 本文介绍了一种名为“预训练通用医学图像变换器(Pre-trained Universal Medical Image Trans
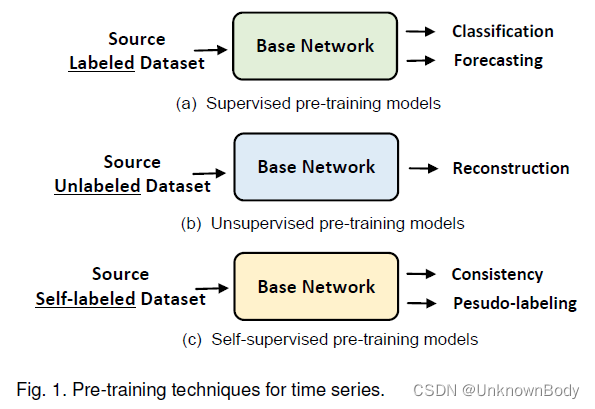
A Survey on Time-Series Pre-Trained Models
本文是LLM系列的文章,针对《A Survey on Time-Series Pre-Trained Models》的翻译。 时间序列预训练模型综述 摘要1 引言2 背景2.1 时间序列挖掘任务2.1.1 时间序列分类2.1.2 时间序列预测2.1.3 时间序列聚类2.1.4 时间序列异常检测2.1.5 时间序列推测 2.2 深度学习模型用于时间序列2.2.1 循环神经网络2.2.2 卷积神
SemEval等数据集SOTA又刷新啦!! Downstream Model Design of Pre-trained language Model for Relation Extraction
《Downstream Model Design of Pre-trained language Model for Relation Extraction》该论文是华为在2020自然语言处理顶会ACL上发表的一片文章。论文所提出的REDN模型在SemEval 2010 task 8、NYT以及WebNLG上完成SOTA结果。个人认为该篇论文的创新点还是比较好的,构思非常的巧妙。 目
CODEFUSION: A Pre-trained Diffusion Model for Code Generation
本文是LLM系列文章,针对《CODEFUSION: A Pre-trained Diffusion Model for Code Generation》的翻译。 CODEFUSION:预训练扩散模型用于代码生成 摘要1 引言2 相关工作3 方法4 评估设置5 评估6 结论7 局限性 摘要 想象一下,一个开发人员只能更改他们的最后一行代码——他们需要多久从零开始编写一个函数才能正确

Pre-trained Language Models Can be Fully Zero-Shot Learners
本文是LLM系列文章,针对《Pre-trained Language Models Can be Fully Zero-Shot Learners》的翻译。 预训练语言模型可以是完全零样本的学习者 摘要1 引言2 相关工作3 背景:PLMs基于提示的调整4 提出的方法:NPPrompt5 实验6 讨论7 结论局限性 摘要 在没有标记或额外的未标记数据的情况下,我们如何将预先训练的
Pruning Pre-trained Language Models Without Fine-Tuning
本文是LLM系列文章,针对《Pruning Pre-trained Language Models Without Fine-Tuning》的翻译。 修剪未微调的预训练语言模型 摘要1 引言2 相关工作3 背景4 静态模型剪枝5 实验6 分析7 结论8 局限性 摘要 为了克服预训练语言模型(PLMs)中的过度参数化问题,剪枝作为一种简单直接的压缩方法被广泛使用,它直接去除不重要的

CPM:A large-scale generative chinese pre-trained lanuage model
GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成)Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成) - GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese t

Black-box Prompt Learning for Pre-trained Language Models
论文链接https://arxiv.org/pdf/2201.08531.pdf Abstract 近年来,针对大型预训练模型的特定领域微调策略受到了广泛关注。在之前研究的设置中,模型架构和参数是可调的,或者至少是可见的,我们称之为白盒设置。这项工作考虑了一个新的场景,在这个场景中,除了给定输入的输出,我们无法访问预先训练的模型,我们称这个问题为黑盒微调。为了说明我们的方法,我们首先在文本分类

【文献阅读与想法笔记13】Pre-Trained Image Processing Transformer
任务目标 low-level computer vision task denoising(30,50)super-resolution(X2,X3,X4)deraining 贡献与创新(个人认为有价值的部分) IPT模型采用多头多尾共享的变压器体,用于图像超分辨率和去噪等不同的图像处理任务。 为了最大限度地挖掘Transformer结构在各种任务上的性能,探索了一个合成的ImageN

BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning-基于自监督学习预训练编码器的后门攻击
BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning 摘要 本文提出了 BadEncoder,这是针对自监督学习的第一个后门攻击方法。用 BadEncoder 将后门注入到预训练的图像编码器中,基于该编码器进行微调的不同下游任务会继承该后门行为。我们将 BadEncoder 描述为一个优
【论文阅读】CodeBERT: A Pre-Trained Model for Programming and Natural Languages
目录 一、简介二、方法1. 输入输出表示2. 预训练数据3. 预训练MLMRTD 4. 微调natural language code searchcode-to-text generation 三、实验1. Natural Language Code Search2. NL-PL Probing3. Code Documentation Generation4. 泛化实验
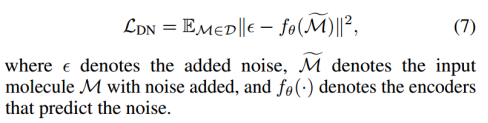
IJCAI2023 | A Systematic Survey of Chemical Pre-trained Models(化学小分子预训练模型综述)
IJCAI_A Systematic Survey of Chemical Pre-trained Models 综述资料汇总(更新中,原文提供):GitHub - junxia97/awesome-pretrain-on-molecules: [IJCAI 2023 survey track]A curated list of resources for chemical pre-traine