本文主要是介绍Black-box Prompt Learning for Pre-trained Language Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接![]() https://arxiv.org/pdf/2201.08531.pdf
https://arxiv.org/pdf/2201.08531.pdf
Abstract
近年来,针对大型预训练模型的特定领域微调策略受到了广泛关注。在之前研究的设置中,模型架构和参数是可调的,或者至少是可见的,我们称之为白盒设置。这项工作考虑了一个新的场景,在这个场景中,除了给定输入的输出,我们无法访问预先训练的模型,我们称这个问题为黑盒微调。为了说明我们的方法,我们首先在文本分类中正式引入黑盒设置,其中预训练的模型不仅是冻结的,而且是不可见的。然后,我们提出了解决方案BLACKBOX prompt,这是PrompLearning家族中的一种新技术,它可以利用预训练模型从预训练语料库中学习到的知识。我们的实验表明,该方法在八个数据集上达到了最先进的性能。对不同人类设计目标、提示长度和直观解释的进一步分析证明了我们方法的鲁棒性和灵活性。
Introduction
大型预训练语言模型(PLM)在自然语言处理(NLP)方面取得了巨大成功,预训练和微调方法已成为一种标准范例。PLMs在自然语言理解(NLU)(Devlin等人,2019年;Liu等人,2019年)和自然语言生成(NLG)(Lewis等人,2020年;Zhang等人,2020年;Yang等人,2020年)的各种应用场景中显示出巨大的优势。在本文中,我们关注文本分类任务,这是NLU中一项探索性很强但很重要的任务,旨在识别给定句子的类别。之前的研究基于标准实践,即给定一个输入句子,使用标记的数据集(finetune)对预先训练的语言模型进行微调。然而,对大型PLM进行微调需要时间和能源消耗,这是许多研究人员无法做到的。例如,GPT-3(Brown等人,2020年)有1750亿个参数,在微调时会导致内存不足问题。更糟糕的是,我们需要为每个不同的下游任务微调一个模型,并将它们保存在磁盘上,这不仅笨拙,而且在我们有成千上万个不同的任务时也不可行。
因此,最近提出了一种新的方法,称为基于提示的学习(高等人,2021;刘等人,2021 b;Schick和Schu Zuz,2021;李和梁,2021;刘等人,2021 A),减轻了上述问题,并有几个好处。首先,我们只需要调整一小部分参数,而不是整个PLM,这更具成本效益。其次,可以设计基于即时的目标,以消除培训前任务和下游任务之间的差距。第三,使用很少的可调参数,它可以实现与微调方法相当的性能。目前大多数基于prompt的研究都集中在prompt的设计上,即prompt工程。所提出的方法是在白盒设置下进行的,在白盒设置下,预先训练的模型是可调的或至少是可见的,以便梯度可以反向传播以更新提示。白盒设置有几个问题。首先,不能在所有情况下都看到预先训练好的模型的参数。例如,研究人员无法获得一些商业产品,因此我们无法进行微调或白盒优化。即使我们可以访问预先训练过的模型,它也可能太大,无法将其(例如GPT-3)加载到资源有限的研究人员和组织的内存中。其次,在许多实际应用场景中,预先训练的模型部署在云中,而梯度计算不可用。因此,我们提出了一种称为“黑箱提示学习”的新设置,在该设置中,预先训练的模型既不可见也不可调整。唯一可调的权重是新添加的分类层和提示。为了解决这个问题,我们设计了一种黑盒快速学习方法,可以在不访问预训练模型参数的情况下使用。在两类数据集上的实验结果,即没有域转移的数据集和有域转移的数据集,证明了所提出的黑盒快速学习的有效性,与一般的预训练模型相比,该方法显著提高了性能,并且在八个数据集上优于所有基线模型。研究结果证实,对于预训练的模型,采用黑盒激励是一种有效的PLM自适应解决方案。我们还通过调查不同目标和提示长度的影响,提出了进一步的分析。我们的分析证明了该方法的鲁棒性和灵活性。
此外,我们还模拟了一个实际设置,其中有N个域(边缘设备),每个域都有黑盒提示。同时,在云端部署了一个预先训练好的模型,该模型是不可见且不可调整的。通过在四个选定的目标数据集上实现良好的性能,我们的方法在这种情况下被证明是有效的。这项工作的贡献可以总结如下:
我们提出了一种新的黑盒快速学习设置,我们只需要访问预先训练的模型的输入和输出,而不需要访问模型参数或模型梯度<\/br>
•我们提出了一种新的黑盒快速学习方法来解决这个新提出的问题,并证明了它在处理各种任务的领域转移方面的有效性<\/br>
•黑匣子提示经过优化,无需调整预先训练的模型,节省了微调成本。此外,与以前的方法相比,我们可以在更广泛的应用程序中执行微调,例如,当模型只能通过典型商业产品中的预测API访问时,或者在设备和云协作的设置中进行模型个性化。

Related Work
Prompts for Pre-trained Models
大型预训练语言模型非常重要,标准范例是在大型未标记语料库上预训练语言模型,然后在不同的监督任务上微调预训练模型。这种方法在很多下游任务上都有很大的改进,但这种方法有几个问题:
(1)微调需要更改模型的所有参数,这会导致计算成本的金钱和时间。
(2) 它必须为不同的任务微调模型,并分别保存它们,这既笨拙又耗费资源。因此,我们迫切需要一种不需要调整大模型的方法,即基于promptbased的学习。根据提示的格式,基于提示的学习可分为两类:离散提示(江等人,2020;Yunn等人,2021;Havviv等人,2021;华勒斯等人,2019;Sin等人,2020;高等人,2021;Ben David等人,2021;Daveon等人,2019)和连续提示。(锺等,2021;秦和艾斯纳,2021;HabBaldZuMayin等人,2021;刘等人,2021b;Hand et al.,2021)。离散提示通常是一系列标记或自然语言短语,而连续提示被设计为一系列向量(嵌入)。然而,所有这些研究都局限于白盒环境,需要查看预训练模型的所有参数,以便梯度可以反向传播。因此,我们的方法“黑盒提示学习”扩展了这些研究,并提供了一个黑盒解决方案,它可以在不访问预先训练的模型的情况下优化提示。
Black-box Optimization
黑盒优化的一个应用是基于分数的黑盒对抗攻击(Ilyas等人,2018a,b;Huang and Zhang,2019;Andriushchenko等人,2020;Cheng等人,2019;Guo等人,2019),攻击者也看不到这些模型。这些研究使用零阶优化方法,如自然进化策略(NES)(Wierstra et al.,2014)来优化输入并增加损失,从而愚弄模型。我们的工作不是恶化模型在对抗性攻击中的性能,而是使用NES(自然进化策略(NES)是黑盒问题的一类数值优化算法。 与进化策略的精神相似,它们通过遵循自然梯度向更高的期望适应度迭代更新搜索分布的(连续的)参数 )来寻找更好的提示,并实现更高的准确性。这是黑盒优化方法的一个新应用。
The Approach
我们使用罗伯塔作为我们的骨架模型,输入是一个句子x= x1,x2···西···Xm,席席表示第i个令牌。n提示标记P=p1,p2。。,pn被预先挂接到输入语句来构造[P,X],其中X中每个标记的表示由ROBERTA的原始嵌入函数计算。p1,p2,…,的嵌入。。,pn是要学习的连续自由参数。整个方法分为两个阶段:白盒阶段和随后的黑盒阶段。整体架构如图2所示。我们首先设置白盒阶段以提供可靠的参数初始化,然后引入黑盒训练阶段,通过优化提示中的数十到数百个参数,我们可以进一步提高性能。
WHITE-BOX Optimization
在白盒阶段,我们冻结罗伯塔,而其他参数则通过反向传播进行调整。如Wierstra等人(2014)所示,当目标函数位于低维空间时,大多数黑盒算法是有效的,不适合直接优化维度与LMs的隐藏大小(例如768)一样大的提示。因此,我们跟随李和梁(2021)初始化pi∈ Rd,并使用投影层F将其调整为Rd:pi=F(pi),其中D是LMs的隐藏大小,D<<D。请注意,为了将参数数量限制在数千个以内,我们仅使用经典线性层来实现F。初始化和投影提示后,我们预挂P=p1,p2。。,pn和X构造[P,X],并通过以下方式训练模型:
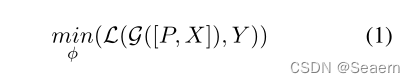
BLACK-BOX Optimization
在进行黑盒训练时,我们冻结了分类器和F,只进一步优化了由白盒训练初始化的提示。我们采用自然进化策略(NES)(Wierstra et al.,2014)算法来完成黑盒训练。在黑盒阶段,渐变不能再反向传播到提示,这意味着不再可能通过计算来直接更新提示∇L(G([p,x],y)),其中x和y分别是输入和标签,p表示提示。NES使用以下迭代更新p:

其中η是提示的学习率,I是样本量,wi是从高斯分布N(pt,σ2)初始化的样本。如Huang和Zhang(2019)所示,1 I=1 Mi提供了梯度的近似值。
这里我们介绍了使用NES算法更新提示的详细过程。假设输入数据被分成T个批次,每个批次bt执行I次迭代。在第t批和第i次迭代中,我们首先从N(pt,σ2)中随机采样微扰wi,并使用投影层F将其映射到Rn×D。获得wi后,我们将其等待到bt的嵌入,并将[wi,bt]馈送到G,G表示由ROBERTA和分类层组成的主模型,然后我们用损失函数L来计算损失。Mi由lossi·(wi)计算− pt)\/σ。最后,通过平均所有Mi计算最终估计的梯度,提示pt由pt+1=pt更新− η·(1 I PI I=1 Mi)。算法1显示了我们提出的更新方法的训练过程。

Experimental Settings
在本节中,我们首先介绍数据集(§4.1),然后介绍基线模型(§4.2)和评估指标(§4.3)。最后,我们描述了实施细节(§4.4)。
Datasets
为了探索模型在常规分类任务和领域特定分类任务中的能力,我们包括GLUE benchmark的四个数据集(Wang等人,2018年)和Gururangan等人(2020年)之后的计算机科学、评论和新闻等特定领域的四个数据集;刁等人(2021年)。这些数据集的统计数据如表1所示。

Baselines
在我们的实验中,我们使用以下三个模型作为基线。
ROBERTA:一个现成的罗伯塔基础模型,重量冻结。对于下游任务,只更新新添加的分类层(分类器)。
ROBERTA+白盒提示(WP):一款现成的ROBERTA基本型号,重量冻结。对于下游任务,只更新新添加的分类层(分类器)和提示。我们遵循PrompTuning Lester等人(2021)的方法,其中n个提示标记p1、p2、。。,pn被预先挂起到输入,p1,p2,…,的嵌入。。,我们都学会了。
ROBERTA+白盒提示+投影(WP.P):一款现成的ROBERTAbase模型,重量冻结。初始化pi的嵌入∈ Rd和投影函数,即线性层或MLP,用于将pi投影到Rd中。提示p1、p2、。。,学习了投影函数和分类器的参数。
Evaluation Metrics
对于GLUE基准测试中的任务,我们采用Matthews相关系数表示COLA,F1score表示MRPC,RTE和WNLI按照其原始度量选择的准确性表示。继Diao等人(2021年)之后,我们采用macro-F1对亚马逊、引文意图、SCIERC和超级党派进行评估。
Implementation
对于所有实验,我们实现了ROBERTAbase架构,并通过Huggingface的Transformers library2使用预先训练好的权重对其进行初始化。培训和评估的批量大小分别设置为16和32。我们以5×10的学习率对我们模型的基线模型和白盒阶段进行了30个阶段的训练−4.采用的优化器是AdamW(Loshchilov and Hutter,2019)。对于ROBERTA+WP基线,我们遵循Lester等人(2021)的实施,提示的长度为6。对于白盒阶段,我们随机初始化提示符,其维度在{4,8,16,32}中,然后将其投影到一个带有线性层的768-d向量中。提示的尺寸与ROBERTA的隐藏尺寸相同。对于黑盒阶段,我们重新加载保存的模型,该模型在白盒阶段的开发集上获得最高分数,并通过优化提示对其进行训练。我们模型中包含的其他参数见附录。
Experimental Results
Overall Performance
在白盒和黑盒设置下,我们将ROBERTA模型与基于Prompt的ROBERTA进行比较。表2中报告了八个数据集的总体结果。首先,具有即时调优的模型的性能优于没有即时调优的模型,这表明即时调优在所有八项任务上都是有效的。具体来说,两个白盒提示学习模型ROBERTA+WP和ROBERTA+WP。P八个数据集的平均改善率分别为9.04%和10.57%。这一观察与先前的快速学习研究一致(李和梁,2021;Schick和Schu uz,2020;刘等人,2021 b)。其次,与白盒优化模型相比,黑盒优化在白盒优化的基础上带来了进一步的收益。黑盒优化有助于将性能平均提高约2.22%,这表明黑盒优化与白盒优化具有协同作用。在八项任务中,我们观察到,在域转移数据集上的黑盒优化与在一般域中的数据集一样有效。虽然众所周知,领域转移对于模型来说更难处理,但黑盒优化为特定领域的数据集提供了一个有效的解决方案。我们提供了黑匣子培训带来的绩效进一步提升的两个主要原因。首先,由于时间和资源的限制,白盒培训通常是不够的。其次,从技术上讲,不可能为每个数据集找到最佳的超参数集。因此,白盒训练的实际性能可能低于理论假设,为黑盒训练留下未来的优化空间。
总之,我们提出的两阶段优化(即白盒和黑盒)是调整大型预训练模型的有效解决方案。与ROBERTA相比,最终模型(白盒+黑盒)的性能平均提高了约12.79%,说明了在一般数据集和特定领域数据集上的有效性。
Performance in Transfer Learning
在本节中,我们在四个情绪分析数据集(即IMDB、CR、MR、MPQA)上进行实验,以验证黑盒训练在迁移学习中的能力。首先,我们使用SST-2作为Vu等人(2021年)之后的源数据集,并对其进行白盒训练。在白盒阶段之后,我们冻结主模型,并对每个目标任务执行黑盒训练,以仅更新提示。继Wang等人(2021年)之后,对于CR、MR和MPQA,我们随机抽取2000个实例作为测试集,并使用其余实例作为训练集。对于IMDB,为了减少训练数据的大小,我们遵循Diao等人(2021)的方法,对10%的训练集进行随机抽样。我们在两个基线模型上进行实验。第一个是直接在每个目标任务的训练集上训练分类层,第二个基线是训练分类层并在源数据集上进行提示,然后在每个目标任务的测试集上进行测试。
结果如表4所示。据观察,黑匣子训练的表现优于ROBERTA和ROBERTA+WP。P,这表明我们的黑盒方法在迁移学习环境下是稳健的。实验结果显示了我们的服务器设备部署方法的扩展潜力。在应用场景中,预先训练的大型模型太大,无法保存在设备上(例如手机),因此它们被部署在云端。为了根据用户的习惯调整模型,我们需要在设备上部署一个微型模型,并使用云端的渐变进行更新。通过我们提出的黑盒提示,我们节省了在云和设备之间传输梯度的成本,并且仍然实现了出色的性能。这实际上是一种很有前途的应用方法,尤其是当云上部署了N个边缘设备(域)和一个大型、不可见且不可调整的预训练模型时。我们可以简单地维护和更新每个设备的黑盒提示。
Conclusion
本文提出了一种新的文本分类设置,即黑盒提示学习,其中一个大的预训练模型是不可见的,因此梯度不能反向传播以更新提示。与标准的pretrain-then-fine-tune范例相比,我们的方法只需要更新很少的参数。与以前基于提示的方法相比,我们的方法不需要预先训练模型的可见性,因此在实际应用中提供了更大的灵活性。我们提出了一种黑盒提示学习方法,该方法使用NES算法来近似梯度,然后更新提示。实验结果表明,与基本方法相比,我们的方法在没有快速学习的情况下获得了很大的收益。与基于白盒提示的方法相比,我们的方法取得了进一步的改进,说明了黑盒优化的有效性。转移学习的实验显示了我们的方法在现实场景中的潜力,在现实场景中,预先训练的模型部署在云上,并且可以在每个设备上实现即时学习。此外,我们的方法不需要反向传播梯度,因此节省了计算和通信成本。
这篇关于Black-box Prompt Learning for Pre-trained Language Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
