pre专题

Vue内置指令v-once、v-memo和v-pre提升性能?
前言 Vue的内置指令估计大家都用过不少,例如v-for、v-if之类的就是最常用的内置指令,但今天给大家介绍几个平时用的比较少的内置指令。毕竟这几个Vue内置指令可用可不用,不用的时候系统正常跑,但在对的地方用了却能提升系统性能,下面将结合示例进行详细说明。 一、v-once 作用:在标签上使用v-once能使元素或者表达式只渲染一次。首次渲染之后,后面数据再发生变化时使用了v-once的

How to leverage pre-trained multimodal model?
However, embodied experience is limited inreal world and robot. How to leverage pre-trained multimodal model? https://come-robot.github.io/

petalinux,Zynq UltraScale+ MPSoC;WARNING: Failed to load PMUFW, doesn't exist in pre-built.
petalinux-package --pmufw ./images/linux/pmufw.elf 这个参数貌似没有生效; 解决办法: cp images/linux/pmufw.elf ./pre-built/linux/images/

如果一个函数func定义在namespace sggk::test中,pre类定义在namespace sggk中,那么func能否调用类pre
在C++中,如果一个函数func定义在命名空间sggk::test中,而类pre定义在命名空间sggk中,那么func函数可以调用pre类,但需要通过适当的命名空间解析来访问它。 有几种方式可以实现这一点: 使用完全限定名:在func函数内部,你可以直接使用sggk::pre来引用pre类。这是最直接且明确的方式,因为它完全指定了pre类所在的命名空间。 cpp name

一文彻底搞懂Fine-tuning - 预训练和微调(Pre-training vs Fine-tuning)
Pre-training vs Fine-tuning 预训练(Pre-training)是预先在大量数据上训练模型以学习通用特征,而微调(Fine-tuning)是在特定任务的小数据集上微调预训练模型以优化性能。 Pre-training vs Fine-tuning 为什么需要预训练? 预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而

cookie-editor插件、Vue的内置指令(v-text、v-html、v-cloak、v-once、v-pre)、自定义指令
目录 1. cookie-editor插件2. v-text3. v-html4. v-cloak5. v-once6. v-pre7. 自定义指令7.1 简单自定义指令7.2 复杂自定义指令 1. cookie-editor插件 可以在谷歌浏览器和火狐浏览器安装cookie-editor插件 在谷歌浏览器,点击Export就可以将谷歌浏览器的所有Cookie复制到粘贴板

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA

ajax返回Json数据中带有<pre>标签去除
某个文件上传ajax取值出问题就很纳闷 于是打印了返回的信息发现json被 <pre style="word-wrap: break-word; white-space: pre-wrap;">{json}</pre> 完完整整的包裹着,不出错才奇怪。 于是为了解决这问题尝试了网上说的一些办法,几乎都没效果,最后还是正则解决了。 记录下吧,可能每个人的情况不一样。 1.将返回的类型从a
8.20 pre day bug
pre-bug1 分号省略 这些语句的分隔规则会导致一些意想不到的情形,如以下的一个示例; let m = n + f(b+c).toString() 但该语句最终会被解析为: let m = n + f(a+b).toString(); returntrue 一定会被解析成 return;true; pre-bug2 Math.random()与Math.fl
8.19 day pre-bug
pre-bug 实在没bug了,只能改成prevent-bug,预防bug 今天复习了很多sql的部分,还有很多没POST上来,果真是 Periodic Table Database ALTER TABLE properties RENAME COLUMN weight TO atomic_mass; ALTER TABLE properties RENAME COLUMN meltin

Vue指令:v-cloak、v-once、v-pre 指令
1、v-cloak 指令 v-cloak 指令可以隐藏未编译的 Mustache 标签直到实例准备完毕,否则在渲染页面时,有可能用户会先看到 Mustache 标签,然后看到编译后的数据。 (1)设置CSS样式 display:none <style type="text/css">[v-cloak] {display: none !important;}</style> (2)使用 v
返回Json数据浏览器带上pre/pre标签解决方法
问题: 当后台获取到前台传来的文件时(例如上传功能, 导入功能), 返回类型为application/json, 这个时候响应到前端的JSON格式的数据格式可能是: <pre style="word-wrap: break-word; white-space: pre-wrap;">{"JsonKey":"JsonValue"}</pre> 这个是不同浏览器对返回数据处理的问题。 主要是在
Editable Email Notification 插件Pre-send Script获取构建的常用的属性和方法
Pre-send Script Editable Email Notification 插件的 build 对象中 result 属性是一个常见的属性,但具体的属性会根据不同的插件和实现而有所不同。以下是一些可能的属性列表,以帮助你了解 build 对象的完整属性: 常见属性 result: status: 构建的状态(如成功、失败、取消等)。number: 构建的编号。url: 构建的 UR
自动化打包上传至 fir.im 蒲公英 pre.im
http://www.jianshu.com/p/b2337700b9be http://www.jianshu.com/p/b2337700b9be http://www.jianshu.com/p/b2337700b9be 自动化打包上传至 fir.im 蒲公英 pre.im 字数439 阅读167 评论0 喜欢1 蒲公英平台请移步http:/
【Reading List】【20190510】预训练(pre-trained)语言模型
RNN,seq2seq,Attention: https://www.leiphone.com/news/201709/8tDpwklrKubaecTa.html 图解transformer : https://blog.csdn.net/qq_41664845/article/details/84969266 Attentinon: https://blog.csdn.net/male
HTML中的<br>、<hr>和<pre>标签使用指南
HTML提供了多种标签来控制文本的显示方式和页面布局。<br>、<hr>和<pre>是其中三种常用的标签,分别用于创建换行、水平线和预格式化文本。以下是这些标签的介绍和使用示例。 <br>标签:换行 <br>标签用于在文本中创建换行,它是自闭合标签,不需要结束标签。 示例:使用<br>创建换行 <p>这是第一行文本<br>这是第二行文本</p> 在上面的例子中,<br>标签使得文本在两

【HTML】格式化文本 pre 标签
文章目录 <pre> 元素中的文本以等宽字体显示,文本保留空格和换行符。 <pre> 元素支持 HTML 中的全局属性和事件属性。 示例: <pre>pre 元素中的文本以等宽字体显示,并且同时保留空格 和换行符。</pre> 效果图: pre 元素中的文本以等宽字体显示,并且同时保留空格 和换行符。

3D 论文阅读 PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding简记
PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding 摘要PointContrast Pre-training实验结果 摘要 简单记一下Charles R. Qi的新作 PointContrast: Unsupervised Pre-training for 3D Point Clou
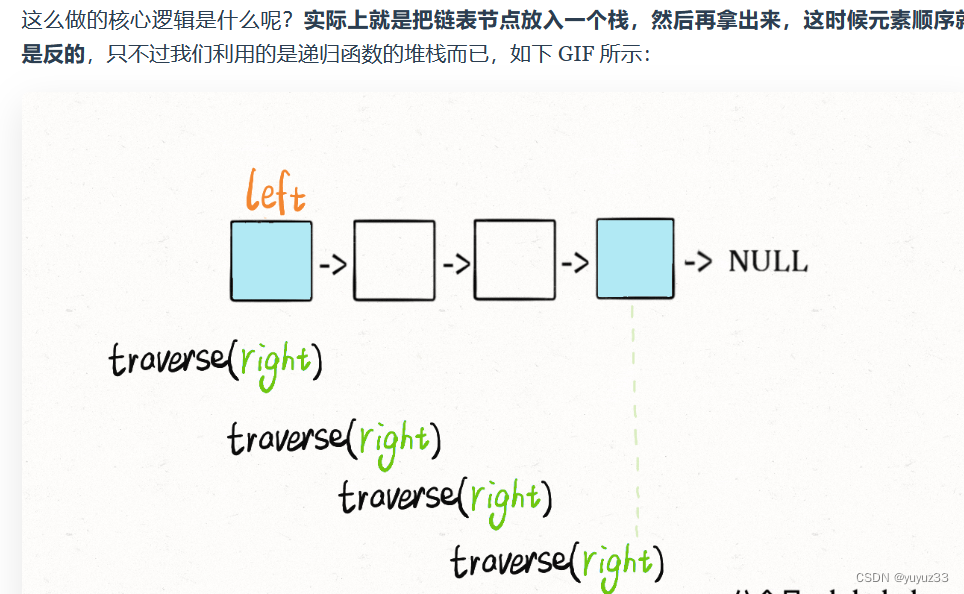
链表翻转,写法和交换类似,但是需要pre cur 还有一个临时变量nxt记录下一个结点
递归反转单链表(头插法反转部分链表 要弄pre cur 还有nxt(临时变量保存下一个结点 P0指到需要修改的链表的前一个结点 class Solution {public ListNode reverseBetween(ListNode head, int left, int right) {ListNode dummy=new ListNode(-1,head);ListNode p0=
Bootstrapping Vision-Language Learning with Decoupled Language Pre-training
我们可以使用以下这六个标准,旨在全面分类视觉语言 (VL) 研究: 学习范式: 该标准区分模型的训练方式。 特定任务学习是一种传统方法,其中模型从头开始针对特定任务(例如视觉问答)进行训练。这种方法很简单,但可能无法很好地泛化到其他任务。端到端预训练涉及在特定任务上微调模型之前,先在大型图像文本数据集上对其进行训练。这利用了从大型数据集中学到的知识,通常会带来更好的性能。基于冻结 LLM 的方
Git如何将pre-commit也提交到仓库
我一开始准备将pre-commit提交到仓库进行备份的,但是却发现提交不了,即使我使用强制提交都不行。 (main)$ git add ./.git/hooks/pre-commit(main)$ git statusOn branch mainnothing to commit, working tree clean# 强制提交(main)$ git add -f ./.git/h
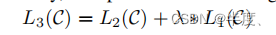
【论文速读】GPT-1:Improving Language Understanding by Generative Pre-Training
摘要 自然语言理解包括广泛的不同的任务,如文本隐含、问题回答、语义相似性评估和文档分类。虽然大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据非常稀缺,这使得经过区别训练的模型要充分执行任务具有挑战性。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调,可以实现这些任务上的巨大收益。 构架 我们的训练过程包括两个阶段。第一阶段是
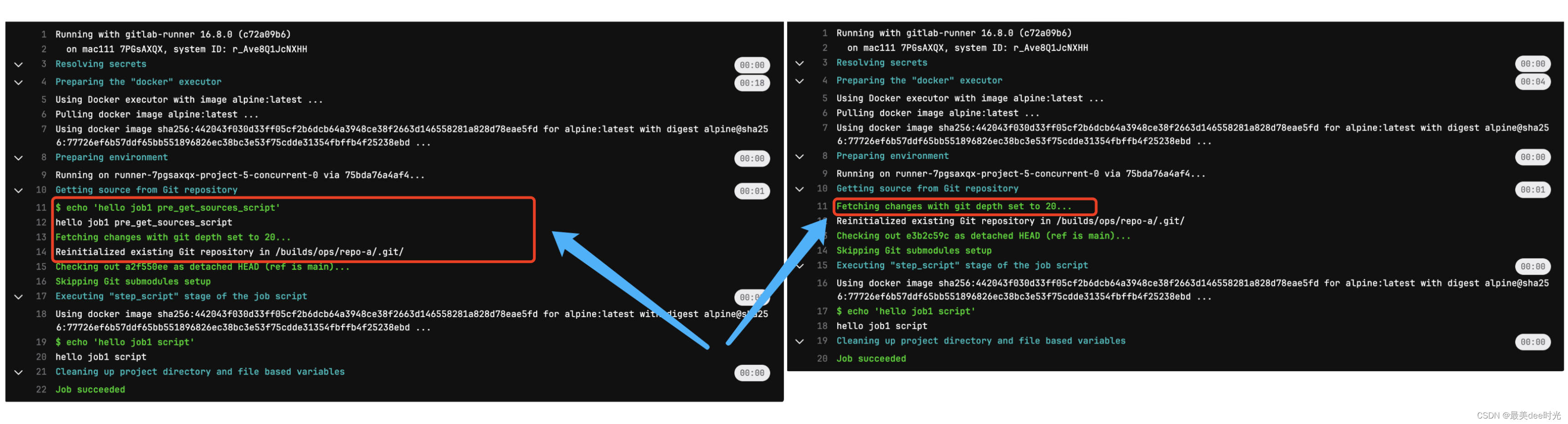
在gitlab CICD中 小试 hooks:pre_get_sources_script 功能
参考链接: hooks:pre_get_sources_script 功能简介 hooks:pre_get_sources_script 是gitlab CICD中的一个功能,该功能可以指定在克隆 Git 仓库和任何子模块之前要在执行器上执行的某些命令。例如: 调整 Git 配置导出跟踪变量 下来简单给大家演示下,看下细节过程。 ci配置 job1:hooks:pre_get_sou

18-Rethinking-ImageNet-Pre-training
what 在目标检测和实例分割两个领域,我们使用随机初始化方法训练的模型,在 COCO 数据集上取得了非常鲁棒的结果。其结果并不比使用了 ImageNet 预训练的方法差,即使那些方法使用了 MaskR-CNN 系列基准的超参数。在以下三种情况,得到的结果仍然没有降低: 仅使用 10% 的训练数据;使用更深和更宽的模型使用多个任务和指标。 ImageNet 预训练模型并非必须,ImageNe
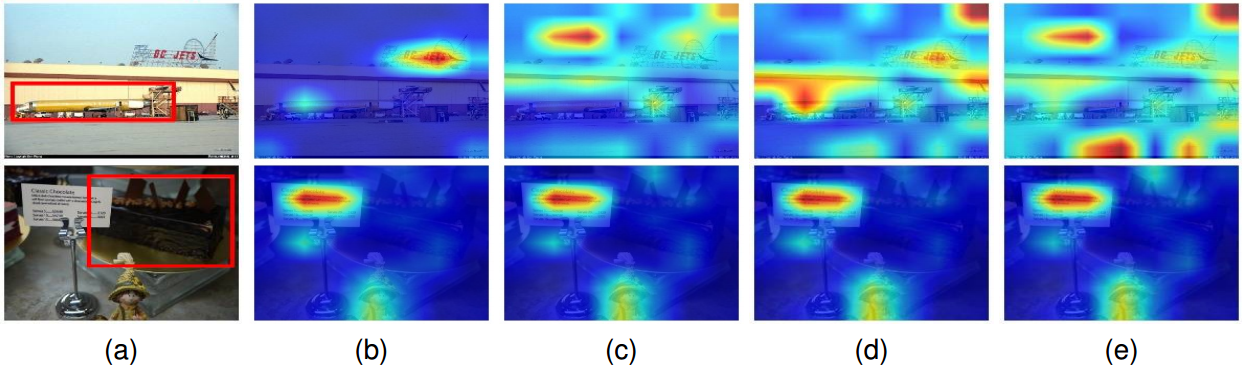
论文解读:(CAVPT)Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
v1文章名字:Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model v2文章名字:Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model 文章汇总 对该文的改进:论文解读:(VPT)Visual Prompt Tuning_vpt