本文主要是介绍3D 论文阅读 PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding简记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding
- 摘要
- PointContrast Pre-training
- 实验结果
摘要
简单记一下Charles R. Qi的新作 PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding。点云的无监督的对比学习作为预训练以提升下游任务的性能。文章使用 连体的网络结构、原始数据和预训练对比损失。6个不同的数据集(室内外,分割、检测,真实、合成)上都表现出学习的特征表示可以跨域泛化。
在2D图像方面,在大尺度的数据集(ImageNet)上进行预训练能够增强模型的表达能力。近年来,无监督的预训练也显示出接近甚至超越监督预训练的性能。3D方面存在的问题的原因是:
1)三维数据更难采集,标签标注更加困难,以及各种传感设备可能引入较大的域差异;
2)没有统一的backbone
3)没有更全面的数据集和更高阶的任务评估。
因此,需要做的主要工作包括:1)选择一个大的数据集进行预训练,2)明确一个backbone,3)无监督的损失函数,4)下游任务的评估方案。
PointContrast Pre-training

之所以效果不好的原因是:ShapeNet合成单目标点云模型和S3DIS之间存在较大的域差异性;实例级的预训练用在场景上效果也不会好。
本文的主要思路可以为:

使用FCGF作为backbone, 一个点云生成两个视角的子点云,计算他们的匹配图(具有相同的实际坐标),将子点云进行刚性变换,网络获取两个子点云每个点的特征向量。对匹配上的点计算匹配损失。
损失函数:
Hardest-Contrastive Loss,(匹配点特征之间的距离应该小,非匹配点之间距离尽可能大。)
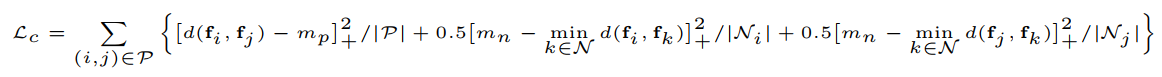
Hardest-Contrastive Loss比较难训练,PointInfoNCE:将对比损失转化为分类损失,本文认为至少存在一个匹配,将除了当前匹配点的集合作为负样本集,没有考虑增加额外的非匹配的点作为负样本。
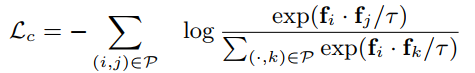
实验结果
Sparse Residual U-Net (SR-UNet) architecture和 在ScanNet基础上构造数据集预训练模型,然后迁移下游任务作为网络初始值进行fine-turning。







这篇关于3D 论文阅读 PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding简记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









