training专题

2014 Multi-University Training Contest 8小记
1002 计算几何 最大的速度才可能拥有无限的面积。 最大的速度的点 求凸包, 凸包上的点( 注意不是端点 ) 才拥有无限的面积 注意 : 凸包上如果有重点则不满足。 另外最大的速度为0也不行的。 int cmp(double x){if(fabs(x) < 1e-8) return 0 ;if(x > 0) return 1 ;return -1 ;}struct poin

2014 Multi-University Training Contest 7小记
1003 数学 , 先暴力再解方程。 在b进制下是个2 , 3 位数的 大概是10000进制以上 。这部分解方程 2-10000 直接暴力 typedef long long LL ;LL n ;int ok(int b){LL m = n ;int c ;while(m){c = m % b ;if(c == 3 || c == 4 || c == 5 ||
2014 Multi-University Training Contest 6小记
1003 贪心 对于111...10....000 这样的序列, a 为1的个数,b为0的个数,易得当 x= a / (a + b) 时 f最小。 讲串分成若干段 1..10..0 , 1..10..0 , 要满足x非递减 。 对于 xi > xi+1 这样的合并 即可。 const int maxn = 100008 ;struct Node{int

Post-Training有多重要?一文带你了解全部细节
1. 简介 随着LLM学界和工业界日新月异的发展,不仅预训练所用的算力和数据正在疯狂内卷,后训练(post-training)的对齐和微调方法也在不断更新。InstructGPT、WebGPT等较早发布的模型使用标准RLHF方法,其中的数据管理风格和规模似乎已经过时。近来,Meta、谷歌和英伟达等AI巨头纷纷发布开源模型,附带发布详尽的论文或报告,包括Llama 3.1、Nemotron 340
2015 Multi-University Training Contest 5 1009 MZL#39;s Border
MZL's Border Problem's Link: http://acm.hdu.edu.cn/showproblem.php?pid=5351 Mean: 给出一个类似斐波那契数列的字符串序列,要你求给出的f[n]字符串中截取前m位的字符串s中s[1...i] = s[s.size()-i+1....s.size()]的最大长度。 analyse: 过计算
![[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction](https://i-blog.csdnimg.cn/blog_migrate/a81ef8f36f1400d5367d93036bc14ef7.png)
[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction
论文地址:https://www.aclweb.org/anthology/D18-1125.pdf发表会议:EMNLP2019 本论文的主要任务是跨领域的关系抽取,具体来说,利用某个领域的数据训练好的关系抽取模型,很难去直接抽取另一个领域中的关系,比如我们拿某个领域训练好的模型,把另一个领域的数据直接输入整个模型,很难抽取出来正确的实体关系。这主要是因为源领域和目标领域特征表达的不同,在源

2014 Multi-University Training Contest 1/HDU4861_Couple doubi(数论/规律)
解题报告 两人轮流取球,大的人赢,,, 贴官方题解,,,反正我看不懂,,,先留着理解 关于费马小定理 关于原根 找规律找到的,,,sad,,, 很容易找到循环节为p-1,每一个循环节中有一个非零的球,所以只要判断有多少完整循环节,在判断奇偶,,, #include <iostream>#include <cstdio>#include <cstring>

一文彻底搞懂Fine-tuning - 预训练和微调(Pre-training vs Fine-tuning)
Pre-training vs Fine-tuning 预训练(Pre-training)是预先在大量数据上训练模型以学习通用特征,而微调(Fine-tuning)是在特定任务的小数据集上微调预训练模型以优化性能。 Pre-training vs Fine-tuning 为什么需要预训练? 预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而

poj 3735 Training little cats(构造矩阵)
http://poj.org/problem?id=3735 大致题意: 有n只猫,开始时每只猫有花生0颗,现有一组操作,由下面三个中的k个操作组成: 1. g i 给i只猫一颗花生米 2. e i 让第i只猫吃掉它拥有的所有花生米 3. s i j 将猫i与猫j的拥有的花生米交换 现将上述一组操作循环m次后,问每只猫有多少颗花生? 很明显,要先构造矩阵,构造一个(n+1)

论文速览【LLM】 —— 【ORLM】Training Large Language Models for Optimization Modeling
标题:ORLM: Training Large Language Models for Optimization Modeling文章链接:ORLM: Training Large Language Models for Optimization Modeling代码:Cardinal-Operations/ORLM发表:2024领域:使用 LLM 解决运筹优化问题 摘要:得益于大型语言模型

ATSS论文要点总结(Adaptive Training Sample Selection)
“ATSS” 全称为 “Adaptive Training Sample Selection”,意为自适应训练样本选择,相关论文的主要内容如下: 核心观点:在目标检测中,anchor-based 和 anchor-free 检测器性能差异的关键在于正负样本的定义方式。如果训练过程中使用相同的正负样本定义,两者性能将无明显差异。基于此,作者提出 ATSS 方法,根据目标的统计特征自动选择正负样本,
BUPT-SUMMER-TRAINING-搜索
比赛地址 A - Sticks 剪枝: 1、 由于所有原始棒子等长,那么必有sumlen % Initlen==0; 2、 若能在[maxlen,sumlen-InitLen]找到最短的InitLen,该InitLen必也是[maxlen,sumlen]的最短;若不能在[maxlen,sumlen-InitLen]找到最短的InitLen,则必有InitLen=sum
Scaling SGD Batch Size to 32K for ImageNet Training
为了充分利用GPU计算,加快训练速度,通常采取的方法是增大batch size.然而增大batch size的同时,又要保证精度不下降,目前的state of the art 方法是等比例与batch size增加学习率,并采Sqrt Scaling Rule,Linear Scaling Rule,Warmup Schem等策略来更新学来率. 在训练过程中,通过控制学习率,便可以在训练的时候采
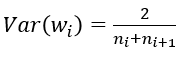
Understanding the difficulty of training deep feedforward neural networks (Xavier)
转自:http://blog.csdn.net/shuzfan/article/details/51338178 “Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文 《Understanding the difficulty of training deep feedforward neural networks》 可惜直到近两年,这个方法才逐渐得

Training Region-based Object Detectors with Online Hard Example Mining(CVPR2016 Oral)
转载自:http://zhangliliang.com/2016/04/13/paper-note-ohem/ Training Region-based Object Detectors with Online Hard Example Mining是CMU实验室和rbg大神合作的paper,cvpr16的oral,来源见这里:http://arxiv.org/pdf/1604.03540
2016 Multi-University Training Contest 2-1001---HDU 5734 Acperience
题目链接:HDU 5734题意:有一个向量: W=(w1,w2,...,wn) W=(w_1,w_2,...,w_n),求一个数 α(α≥0) \alpha(\alpha \ge 0)和一个 B=(b1,b2,...,bn) B=(b_1,b_2,...,b_n)向量,使得 ∥W−αB∥2 \left\| W - \alpha B \right\|^2的值最小。 注: ∥X∥=x21+⋯+x2n
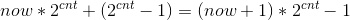
2016 Multi-University Training Contest 2-1005---HDU 5738 Eureka
题目链接:HDU 5738 题意: xjb推导一下可以知道best set一定是一些共线的点, 于是问题变成问有多少个点集共线. 题解: 最基本的想法是,两点确定一条直线,然后判断其他点是否在这条直线上,但是O(N^3)复杂度太高。 可以以一点为基本点,判断其他点与这个点的斜率,将斜率与其对应的点数用map存下来,斜率相等表示都与这个点共线共线。所有点都判断完成后计算与这个点共线的点集
2016 Multi-University Training Contest 1-1005---HDU 5727 Necklace(枚举+二分图匹配)
题目链接:HDU 5727 题意:有一些 宝石,分为阴阳两种,且数量相等,要串成一条项链,并且阴阳宝石不能相邻。同时,有一些阳宝石与特定的阴宝石相邻则会使得其变得暗淡无光。给出这些规则要求最少有多少个阳宝石会变得暗淡无光。 题解 : 其实就是一个阴阳宝石怎么交错摆放的问题,很容易想到通过DFS去搜索枚举,但是直接阴 阳交错搜索的话,时间复杂度太高。因此我们首先选取一种宝石(假设为阴),枚举所
2016 Multi-University Training Contest 1-1011---HDU 5733 tetrahedron(计算几何)
题目链接 HDU 5733题意: 给出一个四面体的四个点,求内切球的半径和圆心。题解: 设四面体的四个顶点分别为 A1 A_1, A2 A_2, A3 A_3, A4 A_4。 四面体内切球半径: 四面体的总体积: V=VPA2A3A4+VPA1A3A4+VPA1A2A4+VPA1A2A3 V=V_{PA_2 A_3A_4}+V_{PA_1A_3A_4}+V_{PA_1A
2016 Multi-University Training Contest 1-1004---HDU 5726 GCD
题目链接:HDU 5726 题意:给出一串数,对于每次区间查询输出这个区间的GCD,并且统计共有多少个区间的GCD等于这个GCD值。 题解: 区间GCD查询:线段树。 统计区间个数:首先,在统计某个区间的GCD值时,相当于统计最后一个数和前面所有数的 GCD 的GCD。 用一个map ans来记录全局的GCD区间个数,map中key为GCD值,value为等于这个值得区间个数。 枚举区
2016 Multi-University Training Contest 1-1001---HDU 5723 Abandoned country(DFS+最小生成树)
题目链接:HDU 5723 题意:给出一些点及其之间的一些边的权值,求最小生成树的总权值以及任意两点之间路径权值的期望。 题解:最小生成树用Kruskal算法求出。 求期望,先求出在每两点之间路径权值的总和,除以C(n,2)即可。 求总权值,在最小生成树中,每条边都可以将树分成两部分,也就是分成的两部分中的点之间的路径中必定包含该边,所以这条边的贡献度为边两边点数相乘然后乘以边的权值,即为

3D 论文阅读 PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding简记
PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding 摘要PointContrast Pre-training实验结果 摘要 简单记一下Charles R. Qi的新作 PointContrast: Unsupervised Pre-training for 3D Point Clou
2014 Multi-University Training Contest 解题报告
多校比赛解题报告: 2014 Multi-University Training Contest 9:多校第九场 2014 Multi-University Training Contest 8:多校第八场 2014 Multi-University Training Contest 7:多校第七场 2014 Multi-University Training Contest 6:多

USACO Training 4.2.3 Job Processing 工序安排 题解与分析
Job Processing 工序安排 IOI'96 描述 一家工厂的流水线正在生产一种产品,这需要两种操作:操作A和操作B。每个操作只有一些机器能够完成。 上图显示了按照下述方式工作的流水线的组织形式。A型机器从输入库接受工件,对其施加操作A,得到的中间产品存放在缓冲库。B型机器从缓冲库接受中间产品,对其施加操作B,得到的最终产品存放在输出库。所有的机器平行并且独立地工作,每个库的容量

USACO Training 3.3.3 Camelot 亚瑟王的宫殿 题解与分析
Camelot亚瑟王的宫殿 IOI 98 描述 很久以前,亚瑟王和他的骑士习惯每年元旦去庆祝他们的友谊。为了纪念上述事件,我们把这些是看作是一个有一人玩的棋盘游戏。有一个国王和若干个骑士被放置在一个由许多方格组成的棋盘上,没有两个骑士在同一个方格内。 这个例子是标准的8*8棋盘 国王可以移动到任何一个相邻的方格,从下图中黑子位置