本文主要是介绍【论文速读】GPT-1:Improving Language Understanding by Generative Pre-Training,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
自然语言理解包括广泛的不同的任务,如文本隐含、问题回答、语义相似性评估和文档分类。虽然大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据非常稀缺,这使得经过区别训练的模型要充分执行任务具有挑战性。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调,可以实现这些任务上的巨大收益。
构架
我们的训练过程包括两个阶段。第一阶段是在大型文本语料库上学习高容量语言模型。接下来是一个微调阶段,在那里我们使模型适应一个有标记数据的鉴别任务。
摘要
自然语言理解包括广泛的不同的任务,如文本隐含、问题回答、语义相似性评估和文档分类。虽然大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据非常稀缺,这使得经过区别训练的模型要充分执行任务具有挑战性。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调,可以实现这些任务上的巨大收益。
构架
我们的训练过程包括两个阶段。第一阶段是在大型文本语料库上学习高容量语言模型。接下来是一个微调阶段,在那里我们使模型适应一个有标记数据的鉴别任务。
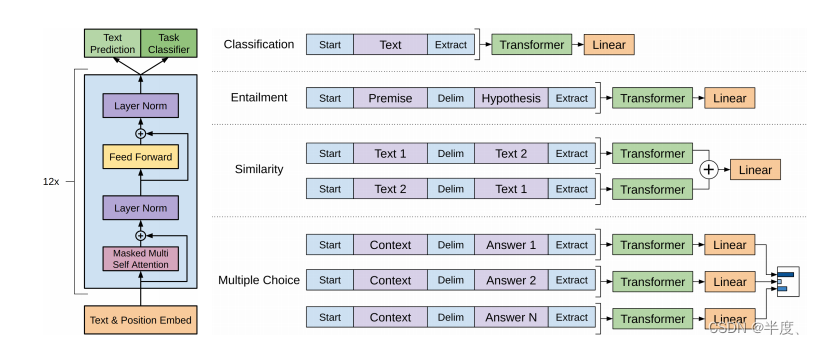
(左)本工作中使用的Transformer架构和训练目标。(右)用于对不同任务进行微调的输入转换。我们将所有结构化的输入转换为令牌序列,由我们的预训练模型进行处理,然后是一个linear+softmax层。
无监督预训练
给定一个无监督的标记语料库 U = { u 1 , … , u n } U = \{u_1,…,u_n\} U={u1,…,un}我们使用一个标准的语言建模目标来最大化以下可能性:

k 上下文窗口大小,条件概率 P 采用参数为Θ的神经网络进行建模。这些参数采用随机梯度下降法进行训练。
架构使用multi-layer Transformer decoder的语言模型。该模型对输入上下文令牌进行多头自注意操作,然后进行位置级前馈层,以产生在目标令牌上的输出分布:

U = ( u − k , . . . , u − 1 ) U = (u−k, . . . , u−1) U=(u−k,...,u−1)为令牌的上下文向量,n为层数, W e W_e We为令牌嵌入矩阵, W p W_p Wp为位置嵌入矩阵。
有监督微调
在等式中对模型进行目标训练后,我们将参数适应于有监督的目标任务。我们假设有一个带有标记的数据集C,其中每个实例都包含一个输入标记序列, x 1 , … , x m , x1,…,xm, x1,…,xm,以及一个标签y。输入通过我们预先训练的模型获得最终transformer block的激活 h l m h^m_l hlm,然后将其输入一个附加的线性输出层,参数 W y W_y Wy来预测y:

这给了我们以下可以最大化的目标:
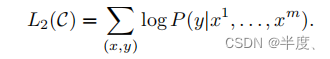
此外,我们还发现,将语言建模作为微调的辅助目标有助于
(a)学习,改进监督模型的泛化,以及
(b)加速收敛。
具体来说,我们优化了以下目标(weight为λ):
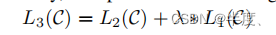
特定的输入转换
所有的转换都包括添加随机初始化的开始标记和结束标记(<s>, <e>),中间有一个分隔符标记($)
这篇关于【论文速读】GPT-1:Improving Language Understanding by Generative Pre-Training的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







