improving专题

论文《Autoencoders for improving quality of process event logs》翻译
论文《Autoencoders for improving quality of process event logs》翻译 《Autoencoders for improving quality of process event logs》翻译


HDU 4968 Improving the GPA
Problem Description Xueba: Using the 4-Point Scale, my GPA is 4.0. In fact, the AVERAGE SCORE of Xueba is calculated by the following formula: AVERAGE SCORE = ∑(Wi * SCOREi) / ∑(Wi) 1<=i<=N

Datacamp 笔记代码 Machine Learning with the Experts: School Budgets 第三章 Improving your model
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 22 (3) Exercise Instantiate pipeline In order to mak

论文阅读:《Improving Content-based and Hybrid Music Recommendation using Deep Learning》
https://blog.csdn.net/u011239443/article/details/79984751 论文地址: https://www.smcnus.org/wp-content/uploads/2013/09/deep_mr.pdf 摘要 现有的基于内容的音乐推荐系统通常采用两阶段的方法。他们首先提取传统的音频内容特征,如 Mel-frequency cepstral系
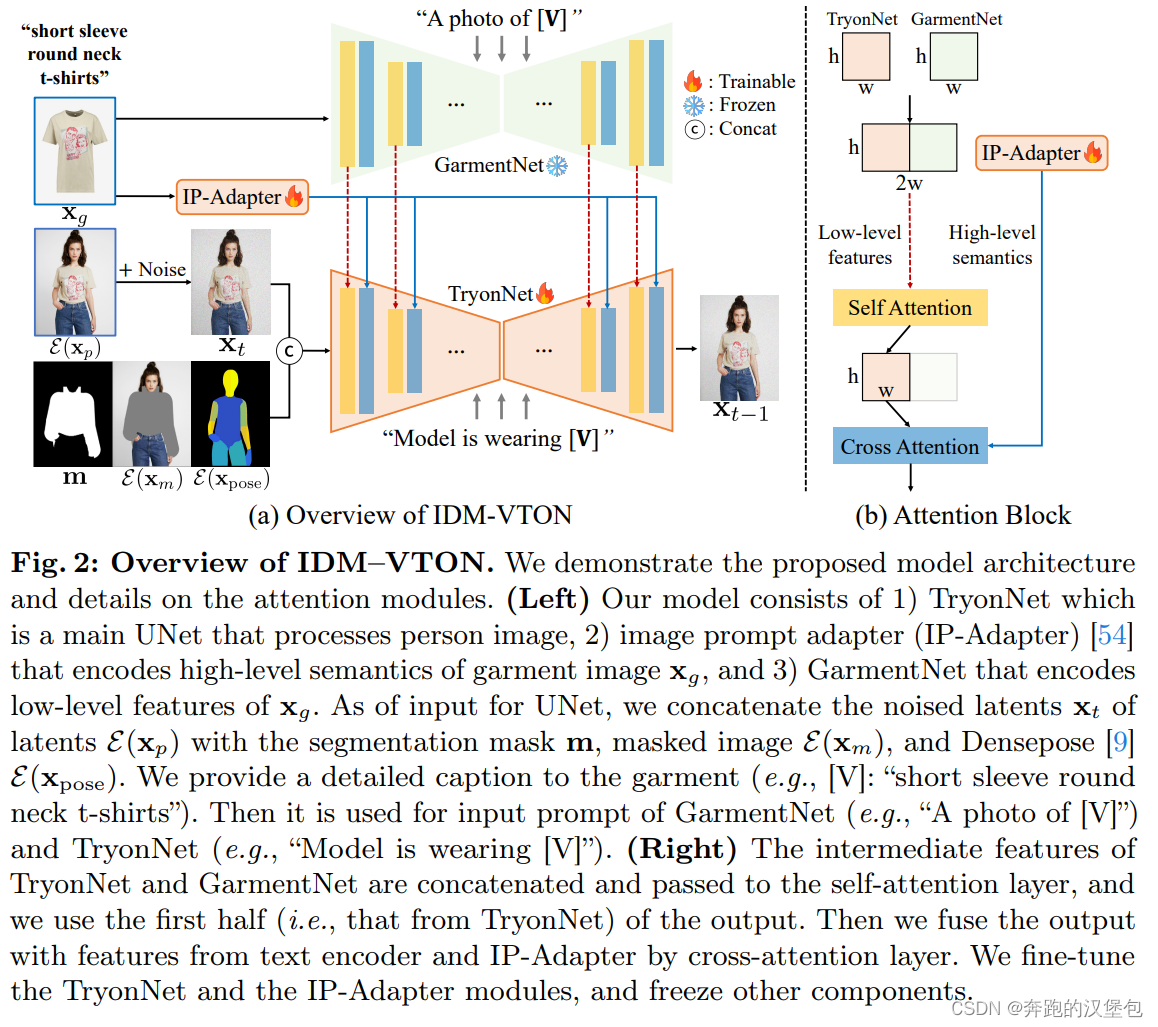
Improving Diffusion Models for AuthenticVirtual Try-on in the Wild # 论文阅读
URL https://arxiv.org/pdf/2403.05139 主页:https://arxiv.org/pdf/2403.05139 TL;DR 24 年 3 月韩国的一篇文章,用 reference net 做换装 Model & Method ppl 如下图,和之前认知的 reference net 的区别是,本文训练的是 denoising unet 而不是 refe
【论文速读】GPT-1:Improving Language Understanding by Generative Pre-Training
摘要 自然语言理解包括广泛的不同的任务,如文本隐含、问题回答、语义相似性评估和文档分类。虽然大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据非常稀缺,这使得经过区别训练的模型要充分执行任务具有挑战性。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调,可以实现这些任务上的巨大收益。 构架 我们的训练过程包括两个阶段。第一阶段是

Hands-On Microsoft Access : A Practical Guide to Improving Your Access Skills
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Hands-On Microsoft Access presents solutions for the challenges you're most likely to encounter, includin
Continuous Integration: Improving Software Quality and Reducing Risk
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp For any software developer who has spent days in integration hell, cobbling together myriad software co

【论文精读】DALLE3:Improving Image Generation with Better Captions 通过更好的文本标注改进图像生成
文章目录 一、文章概览二、数据重标注(一)现在训练数据的文本标注主要存在的问题(二)创建图像标注器(三)微调图像标注器 三、评估重新标注的数据集(一)混合合成标注和真实标注(二)评估方法(三)问题一:评估在不同类型的标注上训练的模型之间的性能差异(四)评估合成标注与真实标注的最佳混合比例(五)实际应用 四、对比DALLE3与其他模型的效果(一)自动评估(二)人工评估 DALL

科研训练第六周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的复现——
时间确实比较紧张,进度稍微有点停滞,课设结束啦,我得赶一下科研的进度~~ 服务器的内存不够用是我没想到的,大概是有别人也在跑叭 数据处理感觉还是得本地跑一下然后save,云端报错如下: 看回答说是request请求太多被拒绝了🙄 ————————————10.18———————————————————— 本周的计划: 完成数据预处理阶段的事情(大概是一直到词向量生成阶段叭)data
论文阅读:SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL Improving Latent Diffusion Models for High-Resolution Image Synthesis 论文链接 代码链接 介绍 背景:Stable Diffusion在合成高分辨率图片方面表现出色,但是仍然需要提高本文提出了SD XL,使用了更大的UNet网络,以及增加了一个Refinement Model,以进一步提高图片质量。 提高SD的

《Improving Calibration for Long-Tailed Recognition》阅读笔记
论文标题 《Improving Calibration for Long-Tailed Recognition》 改进长尾识别的校准工作 作者 Zhisheng Zhong、 Jiequan Cui、Shu Liu 和 Jiaya Jia 香港中文大学和 SmartMore 初读 摘要 深度神经网络在训练数据集类别极度不平衡时可能会表现不佳。最近,两阶段方法将表示学习和分类器学习解

【论文笔记】Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training 文章目录 Improving Language Understanding by Generative Pre-TrainingAbstract1 Introduction2 Related WorkSemi-supervised learning for NLPUnsu

DALL·E 3:Improving Image Generation with Better Captions
论文链接:https://cdn.openai.com/papers/dall-e-3.pdf DALLE3 API:https://github.com/Agora-X/Dalle3 官网链接:添加链接描述 DALLE3讲解视频:B站视频 推荐DALLE2的讲解视频:B站:跟李沐学AI 之前精讲的DALLE2论文 北理&上海AI Lab&清华提出 Mini DALL·E 3:h
NLP论文阅读记录-ACL 2023 | Improving the Robustness of Summarization Systems with Dual Augmentation
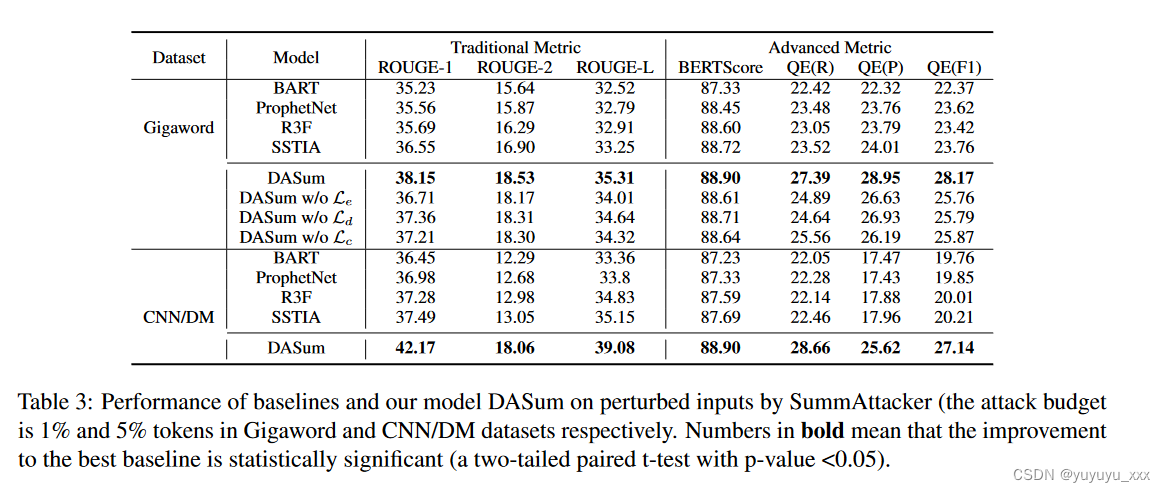
文章目录 前言一、论文摘要二、论文动机2.1目标问题2.2相关工作 三.本文工作3.1 摘要攻击器受攻击的词选择器使用 LM 和梯度进行攻击 3.2 双重增强漏洞分析增强设计输入空间增强潜在语义空间增强 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果SummAttacker EvaluationRobustness Evaluation噪声数据集的鲁

Unity类银河恶魔城学习记录7-5 p71 Improving sword throwing state源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Sword_Skill.cs using System.Collections;using System.Collections.Generic;using UnityEn

Leveraging Knowledge Bases in LSTMs for Improving Machine Reading
《Leveraging Knowledge Bases in LSTMs for Improving Machine Reading》 这篇文章是发表在2017年ACL上的,主要是聚焦于外部知识改善LSTM,运用在实体抽取和事件抽取任务。在ACE2005的数据集上得到了SOTA效果。 首先介绍这篇文章的两个知识库,一个是WordNet一个是NELL。 Word net是人工创造的一个词典,里

论文精读:Improving CLIP Training with Language Rewrites
Status: Finished Author: Dilip Krishnan, Dina Katabi, Lijie Fan, Phillip Isola, Yonglong Tian Institution: Google Research, MIT CSAIL Publisher: NeurIPS Publishing/Release Date: October 28, 2023 Summa
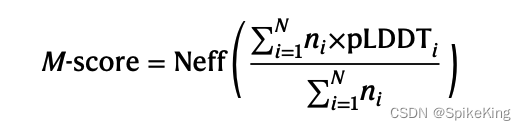
Paper - DeepMSA2: Improving deep learning protein monomer and complex structure prediction
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/135520805 DeepMSA2 是用于构建高质量的蛋白质单体和复合体多序列比对(MSA)的流程,利用了迭代的序列搜索和隐马尔可夫模型算法,从多个基因组和元基因组数据库中提取了大量的同源序列。DeepMSA2

《Learn Windows PowerShell in a Month of Lunches Third Edition》读书笔记—CHAPTER 22 Improving your script
22.1 Starting point 此段脚本和之前的区别是将 Format-Table 改成了 Select-Object 。因为我们认为如果一个脚本输出的结果的格式是预定义好的,这样会不太好。假设有个人想要将结果输出到csv文件中,脚本输出的却是格式化的表格,这样就不太好了。所以我们应该给用户权限来自定义输出的格式。如上脚本可以这样: PS C:\> .\Get-DiskInvento
《Learn Windows PowerShell in a Month of Lunches Third Edition》读书笔记—CHAPTER 22 Improving your script
22.1 Starting point 此段脚本和之前的区别是将 Format-Table 改成了 Select-Object 。因为我们认为如果一个脚本输出的结果的格式是预定义好的,这样会不太好。假设有个人想要将结果输出到csv文件中,脚本输出的却是格式化的表格,这样就不太好了。所以我们应该给用户权限来自定义输出的格式。如上脚本可以这样: PS C:\> .\Get-DiskInvento
![[论文翻译] Improving Knowledge Tracing via Pre-training Question Embeddings](https://img-blog.csdnimg.cn/9459c2c857ef406e9802f66451fe4cf6.png)
[论文翻译] Improving Knowledge Tracing via Pre-training Question Embeddings
摘要 知识追踪 (KT) 定义了根据学生的历史反应预测他们是否能正确回答问题的任务。尽管许多研究致力于利用问题信息,但问题和技能中的大量高级信息尚未被很好地提取,这使得以前的工作难以充分执行。在本文中,我们证明了通过在丰富的边信息上为每个问题预训练嵌入,然后在获得的嵌入上训练深度 KT 模型,可以实现 KT 的巨大收益。具体而言,边信息包括问题难度和问题与技能二分图中包含的三种关系。为了预训练问
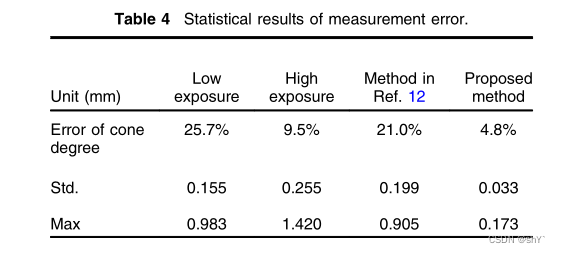
《Improving the quality of stripes in structured-light three-dimensional profile measurement》论文解读
Abstract 用编码结构光测量高动态范围(HDR)反射率的物体,捕获的条纹通常会受到反射率的严重扭曲,导致测量结果不准确。针对这一问题,提出了一种条纹增强方法。该方法基于条纹相位和强度之间的对应关系。首先,利用相移算法和多重曝光法提取条纹图像的相位图,消除条纹图像的饱和和低对比度;然后对条纹调制进行归一化处理,消除反射率的影响;最后,通过调制和相位图的组合得到增强条带。实验结果表明,该方法对
![[论文阅读] CLRerNet: Improving Confidence of Lane Detection with LaneIoU](https://img-blog.csdnimg.cn/914be7db17eb404491ad773e49a61a6f.png)
[论文阅读] CLRerNet: Improving Confidence of Lane Detection with LaneIoU
Abstract 车道标记检测是自动驾驶和驾驶辅助系统的重要组成部分。采用基于行的车道表示的现代深度车道检测方法在车道检测基准测试中表现出色。通过初步的Oracle实验,我们首先拆分了车道表示组件,以确定我们方法的方向。我们的研究表明,现有的基于行的检测器已经能预测出正确的车道位置,而准确表示与地面实况相交-不相交(IoU)的置信度分数是最有利的。基于这一发现,我们提出了 LaneIoU,通过考

Hybrid TLB Coalescing:Improving TLB Translation Coverage under Diverse Fragmented Memory Allocations
Hybrid TLB Coalescing: Improving TLB Translation Coverage under Diverse Fragmented Memory Allocations 摘要: 背景: 在大的存储类应用程序中,会出现很多TLB缺失,因此出现了一些技术(大页,变长段variable length segments,硬件合并TLB表项)用来增加有限硬件资源的TLB