本文主要是介绍论文精读:Improving CLIP Training with Language Rewrites,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Status: Finished
Author: Dilip Krishnan, Dina Katabi, Lijie Fan, Phillip Isola, Yonglong Tian
Institution: Google Research, MIT CSAIL
Publisher: NeurIPS
Publishing/Release Date: October 28, 2023
Summary: CLIP模型通过对比损失进行训练,这通常依赖于数据增强来防止过拟合,但是在CLIP的训练过程中,只对图像进行了数据增强,并没有对文本进行数据增强。基于此,这篇文章提出了文本增强CLIP(Language augmented CLIP, LaCLIP),利用大语言模型的ICL能力,对每张图片的文本描述进行重写。重写的文本保持原意不变,在句子结构和文本表达上具有多样性。在模型训练的时候,随机选择采用原始文本还是重写的文本。作者在CC3M、CC12M、RedCaps和LAION-400M等数据集上进行了实验,证明LaCLIP在不增加算力和内存消耗的情况下,由更好的性能。
Score /5: ⭐️⭐️
Type: Paper
论文链接: https://arxiv.org/abs/2305.20088
代码是否开源: 开源
代码链接: https://github.com/LijieFan/LaCLIP
数据集是否开源: 开源
数据集链接: https://paperswithcode.com/paper/improving-clip-training-with-language-1
读前先问
- 大方向的任务是什么?Task
CLIP的主要任务是为了连接文本和图像。
- 这个方向有什么问题?是什么类型的问题?Type
在对比学习中,对图像做了数据增强,但是没有对文本标签做数据增强。
- 为什么会有这个问题?Why
文本数据增强方法不是很多,
- 作者是怎么解决这个问题的?How
提出了一种新的文本增强方法,利用了大型语言模型(如ChatGPT和Bard)的能力,通过重写文本来增加数据的多样性。
- 怎么验证解决方案是否有效?
跟之前的对比一下。
- 实验结果怎么样?What(重点关注有没有解决问题,而不是效果有多好)
相比不对文本做数据增强确实好一点。
论文精读
引言
以CLIP为代表的预训练的视觉-语言多模态编码器,在从成对的图像和文本数据中学习可迁移特征方面非常有用。这种能力主要来源于两个方面:数据和计算。首先,在数据方面,大量的图像-文本对数据可以更高效的训练大模型。其次,在计算方面,对比学习对图像和文本的共同损失使其具有良好的可伸缩性。
CLIP模型通过对比损失进行训练,这通常依赖于数据增强来防止过拟合,但是在CLIP的训练过程中,只对图像进行了数据增强,并没有对文本进行数据增强,这种输入的不对称性可能会导致同一文本对应不同的图像。这会带来两个问题:① 图像编码器从语言方面接受的监督信号较少,② 文本编码器在每一轮训练中会遇到相同的文本,增加了过拟合的风险,还会影响zero-shot迁移能力。
因此,如何对文本输入进行增强也非常关键。现有的文本增强方法大多还停留在单词层面,例如替换或者掩码,这对丰富文本结构来说提升有限,而且相比于对图像的增强来说也太弱了。然而,如ChatGPT、Bard等LLMs的发展迅速,在一些自然语言任务上的能力已经超过了人类,基于此,作者探索了如何利用LLMs(LLaMA)的ICL来更有效的对文本进行增强。
为了更好地利用ICL提示词,作者设计了多种策略来生成一组小的元输入-输出文本对,包括利用ChatBots、人工重写或使用已有的图像标题数据集,将这些元输入-输出文本对作为提示词输入LLaMA。这种对文本进行数据增强的方式不仅可以保留文本结构,而且重写的内容更加丰富,更具有多样性。
方法
CLIP
L I = − ∑ i = 1 N log exp ( sim ( f I ( aug I ( x I i ) ) , f T ( x T i ) ) / τ ) ∑ k = 1 N exp ( sim ( f I ( aug I ( x I i ) ) , f T ( x T k ) ) / τ ) L_{I}=-\sum_{i=1}^{N} \log \frac{\exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(x_{T}^{i}\right)\right) / \tau\right)}{\sum_{k=1}^{N} \exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(x_{T}^{k}\right)\right) / \tau\right)} LI=−i=1∑Nlog∑k=1Nexp(sim(fI(augI(xIi)),fT(xTk))/τ)exp(sim(fI(augI(xIi)),fT(xTi))/τ)
文本重写增强
提出了一个文本增强函数 aug T \text{aug}_{T} augT,用 aug T ( x T ) \text{aug}_{T}(x_T) augT(xT)作为 f T f_{T} fT的输入。
aug T \text{aug}_{T} augT主要利用了LLMs的ICL能力,它可以通过给定的几个例子来学会一个新的任务,因此需要先生成几个例子,作者在这里提出了3中方法:
- ChatBots:利用ChatGPT和Bard进行修改,提示词:“Rewrite this caption of an image vividly, and keep it less than thirty words:”
- MS-COCO采样:这个数据集中每张图片有5个不同的描述
- 人工重写:随机采样了一部分图像-文本对进行人工标注
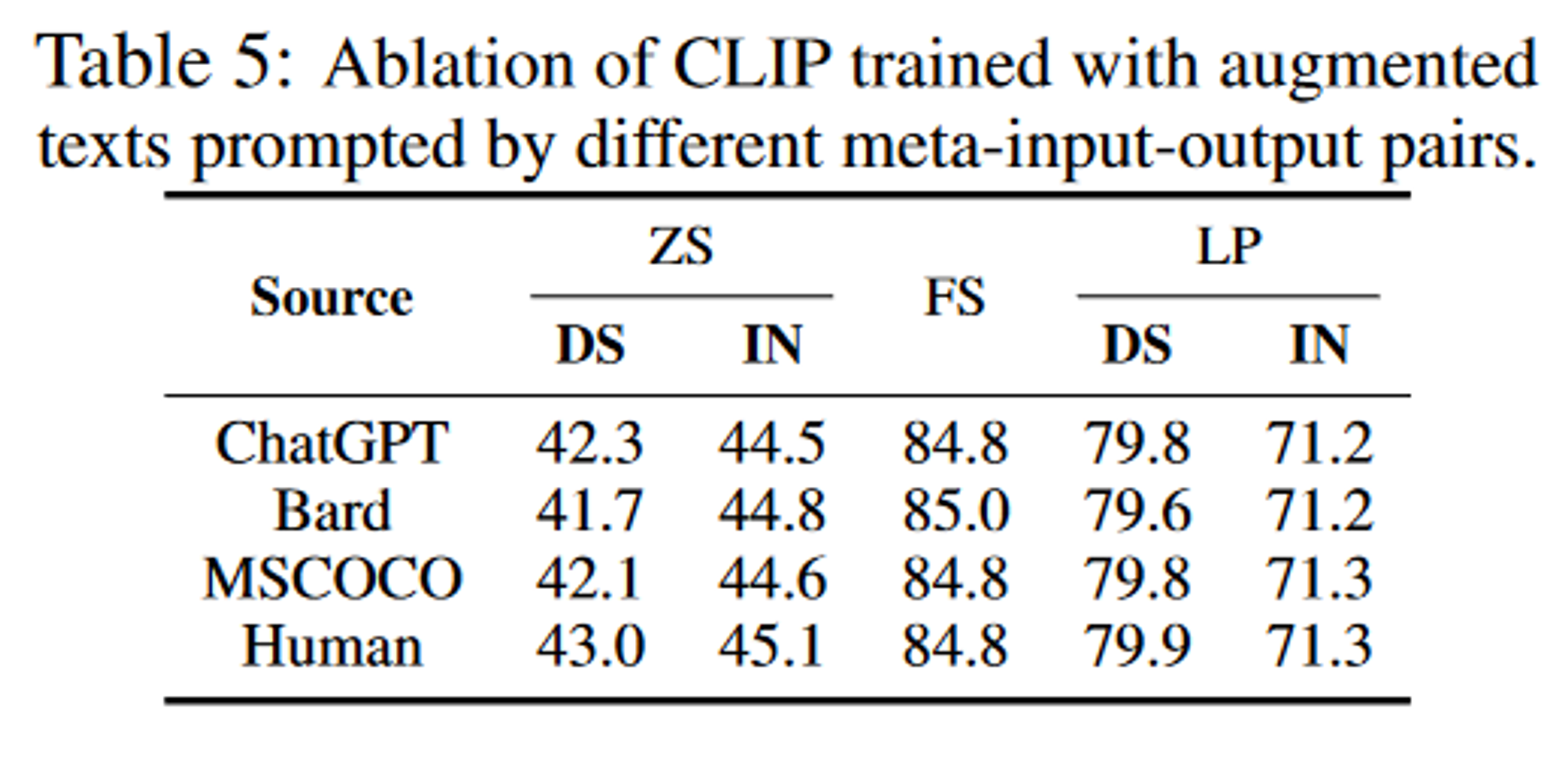
针对四种重写策略(ChatGPT、Bard、COCO和Human),每种策略从图像-文本对数据集中采样16个样本,然后生成新的标题,因此一共有16个元输入-输出文本对。
然后本地部署了一个LLaMA模型来对所有的图像-文本数据集的文本标签进行重写。
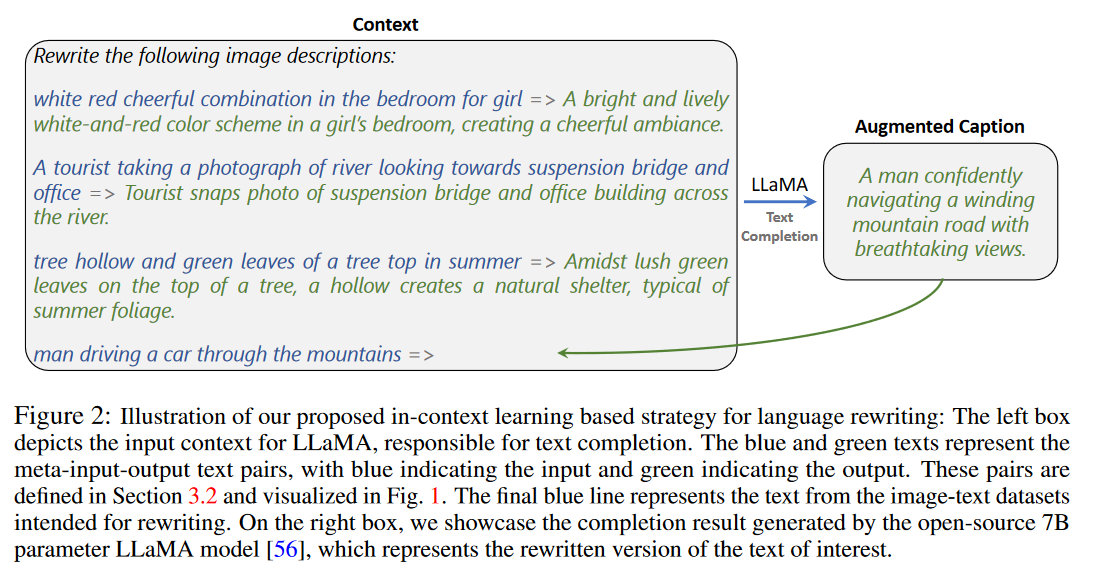
LaCLIP
L I = − ∑ i = 1 N log exp ( sim ( f I ( aug I ( x I i ) ) , f T ( aug T ( x T i ) ) ) / τ ) ∑ k = 1 N exp ( sim ( f I ( aug I ( x I i ) ) , f T ( aug T ( x T k ) ) ) / τ ) L_{I}=-\sum_{i=1}^{N} \log \frac{\exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(\operatorname{aug}_{T}\left(x_{T}^{i}\right)\right)\right) / \tau\right)}{\sum_{k=1}^{N} \exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(\operatorname{aug}_{T}\left(x_{T}^{k}\right)\right)\right) / \tau\right)} LI=−i=1∑Nlog∑k=1Nexp(sim(fI(augI(xIi)),fT(augT(xTk)))/τ)exp(sim(fI(augI(xIi)),fT(augT(xTi)))/τ)
aug T ( x T ) ∼ Uniform ( [ x T 0 , x T 1 … , x T M ] ) \operatorname{aug}_{T}\left(x_{T}\right) \sim \operatorname{Uniform}\left(\left[x_{T 0}, x_{T 1} \ldots, x_{T M}\right]\right) augT(xT)∼Uniform([xT0,xT1…,xTM])
LaCLIP-MT(Multi-Text)
每张图像不仅有原始文本还有重写后的文本,也就是有多个正样本对。损失函数如下,唯一的不同就是现在遍历所有的文本对。
L I ∗ = − 1 M ∑ i = 1 N ∑ j = 0 M log exp ( sim ( f I ( aug I ( x I i ) ) , f T ( x T j i ) ) / τ ) ∑ k = 1 N exp ( sim ( f I ( aug I ( x I i ) ) , f T ( x T j k ) ) / τ ) L_{I *}=-\frac{1}{M} \sum_{i=1}^{N} \sum_{j=0}^{M} \log \frac{\exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(x_{T j}^{i}\right)\right) / \tau\right)}{\sum_{k=1}^{N} \exp \left(\operatorname{sim}\left(f_{I}\left(\operatorname{aug}_{I}\left(x_{I}^{i}\right)\right), f_{T}\left(x_{T j}^{k}\right)\right) / \tau\right)} LI∗=−M1i=1∑Nj=0∑Mlog∑k=1Nexp(sim(fI(augI(xIi)),fT(xTjk))/τ)exp(sim(fI(augI(xIi)),fT(xTji))/τ)
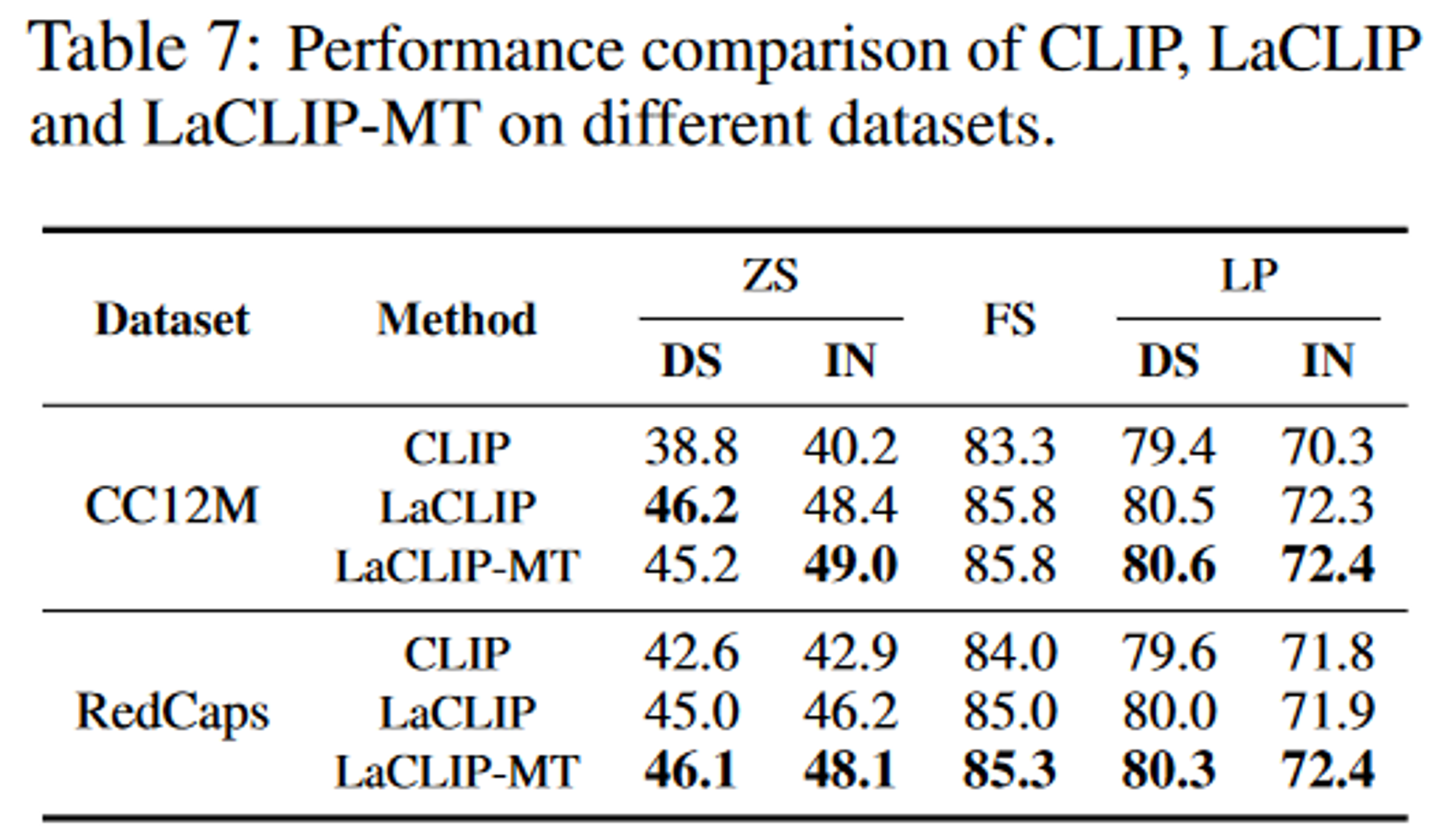
实验
数据集
- 预训练数据集:CC3M、CC12M、RedCaps和LAION-400M
- 下游任务数据集

训练参数
CC3M、CC12M、RedCaps:ViT-B/16架构,batch size 8192,AdamW优化器
LAION-400M:ViT-B/32跟ViT-B/16架构,batch size 32769
评估设定
Zero-Shot分类准确率、Few-Shot分类准确率和Linear Probing准确率。

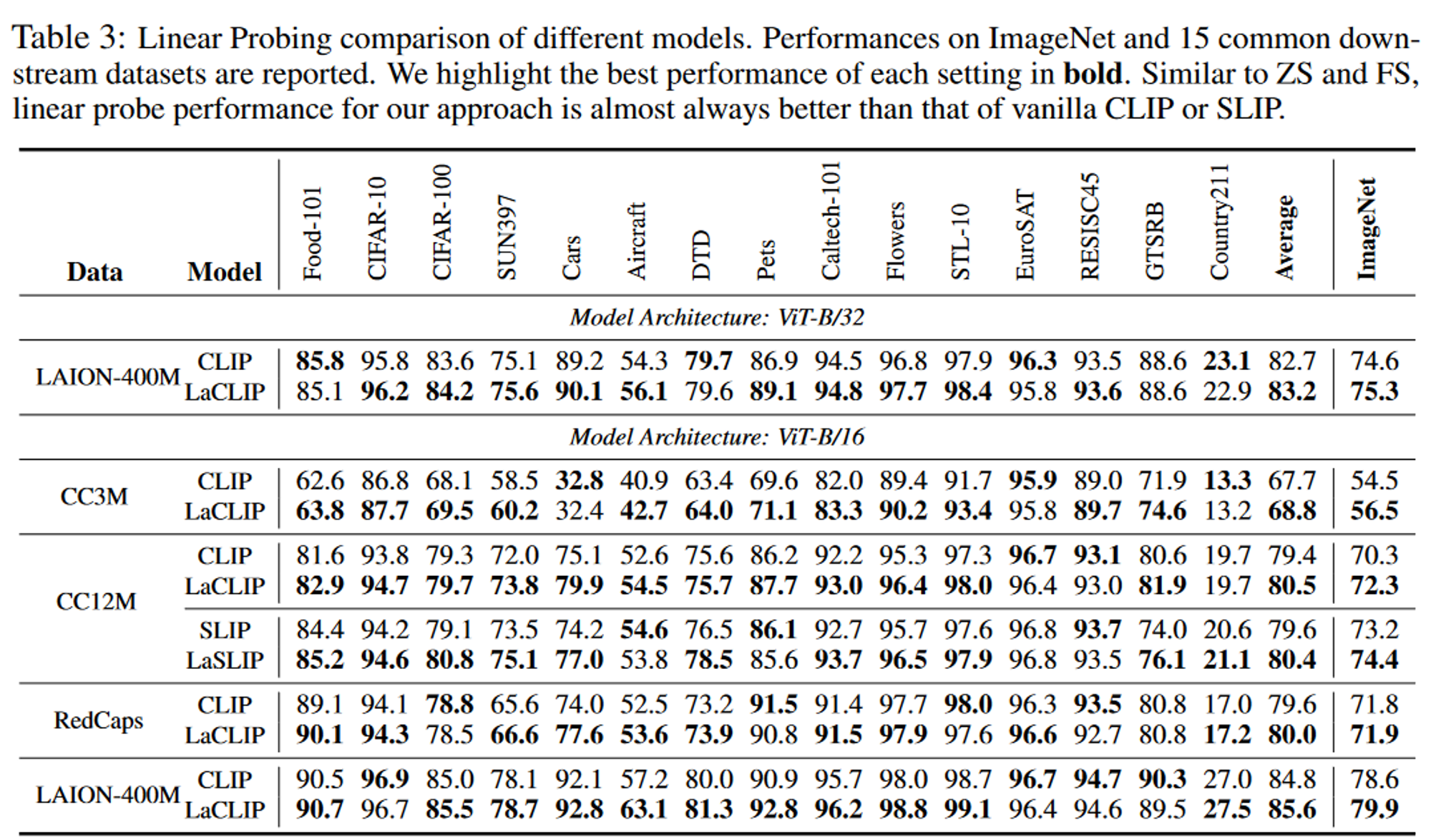
消融实验
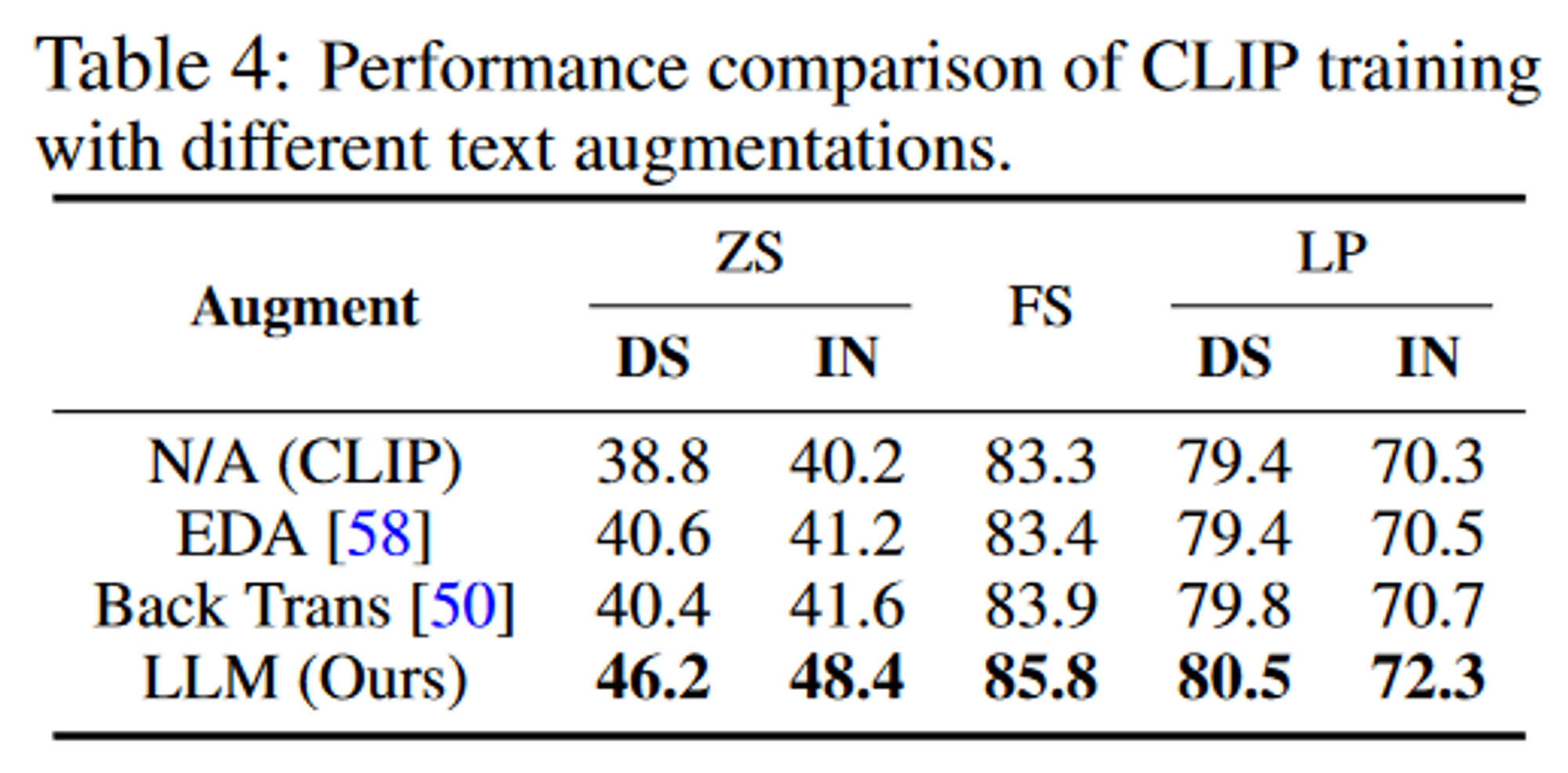
- 不同的增强策略:对比了基于LLM的文本数据增强策略跟其它的文本数据增强策略对准确率的影响
- 增强文本的数量:每个样本增强的文本数量对准确率的影响
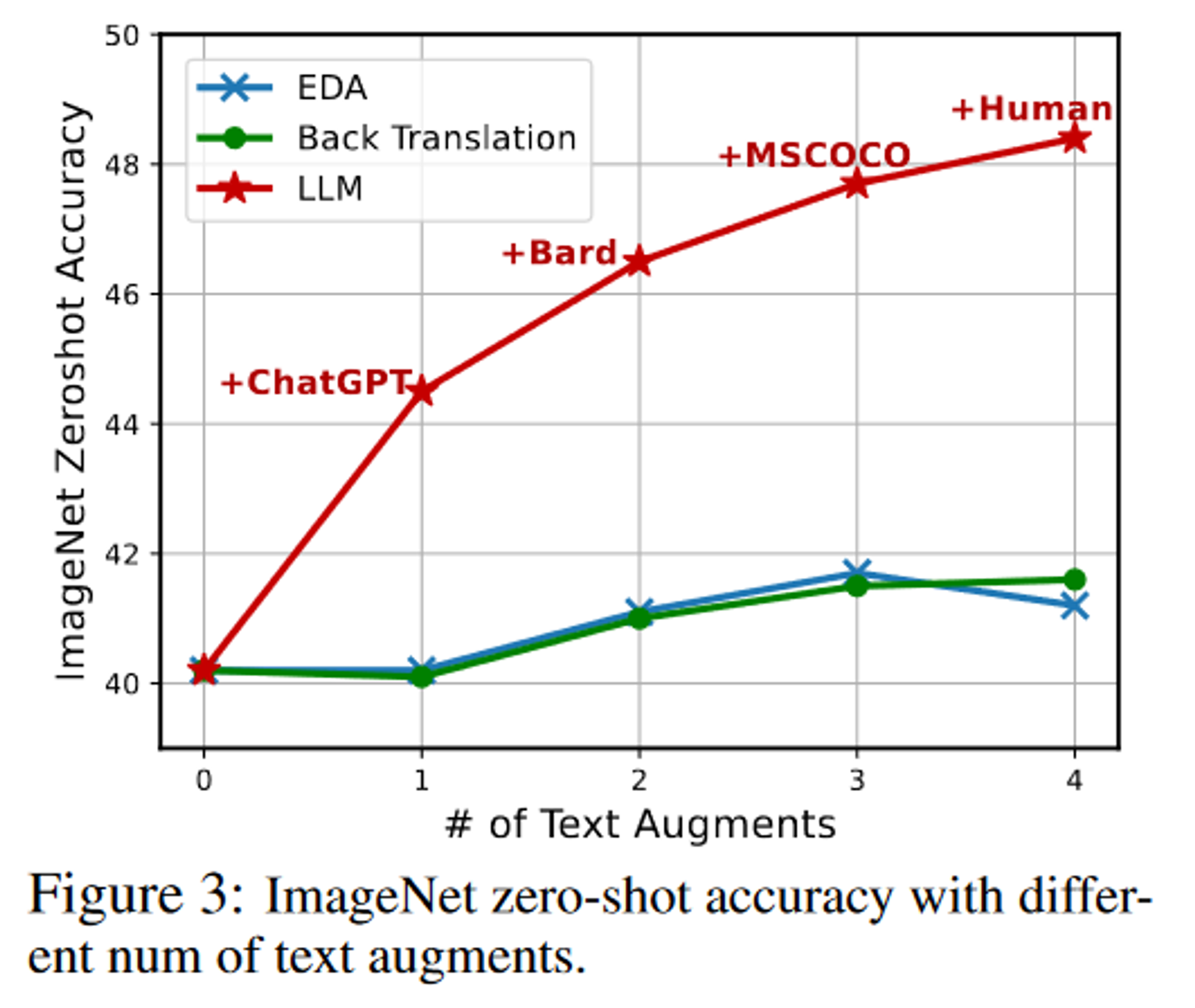
- 不同的ICL元输入输出文本对:LLaMA ICL例子的类型对准确率的影响
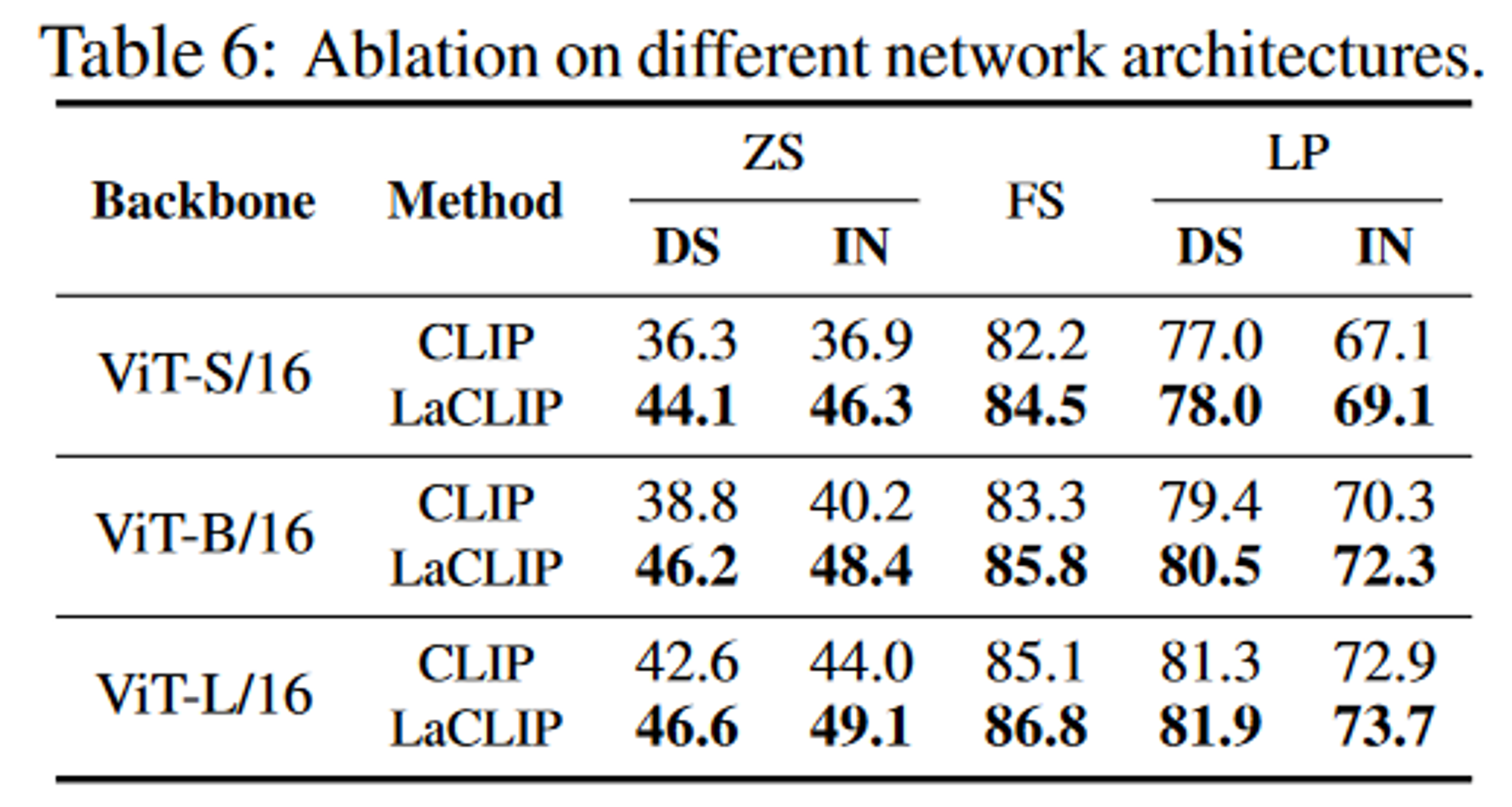
- Backbone架构
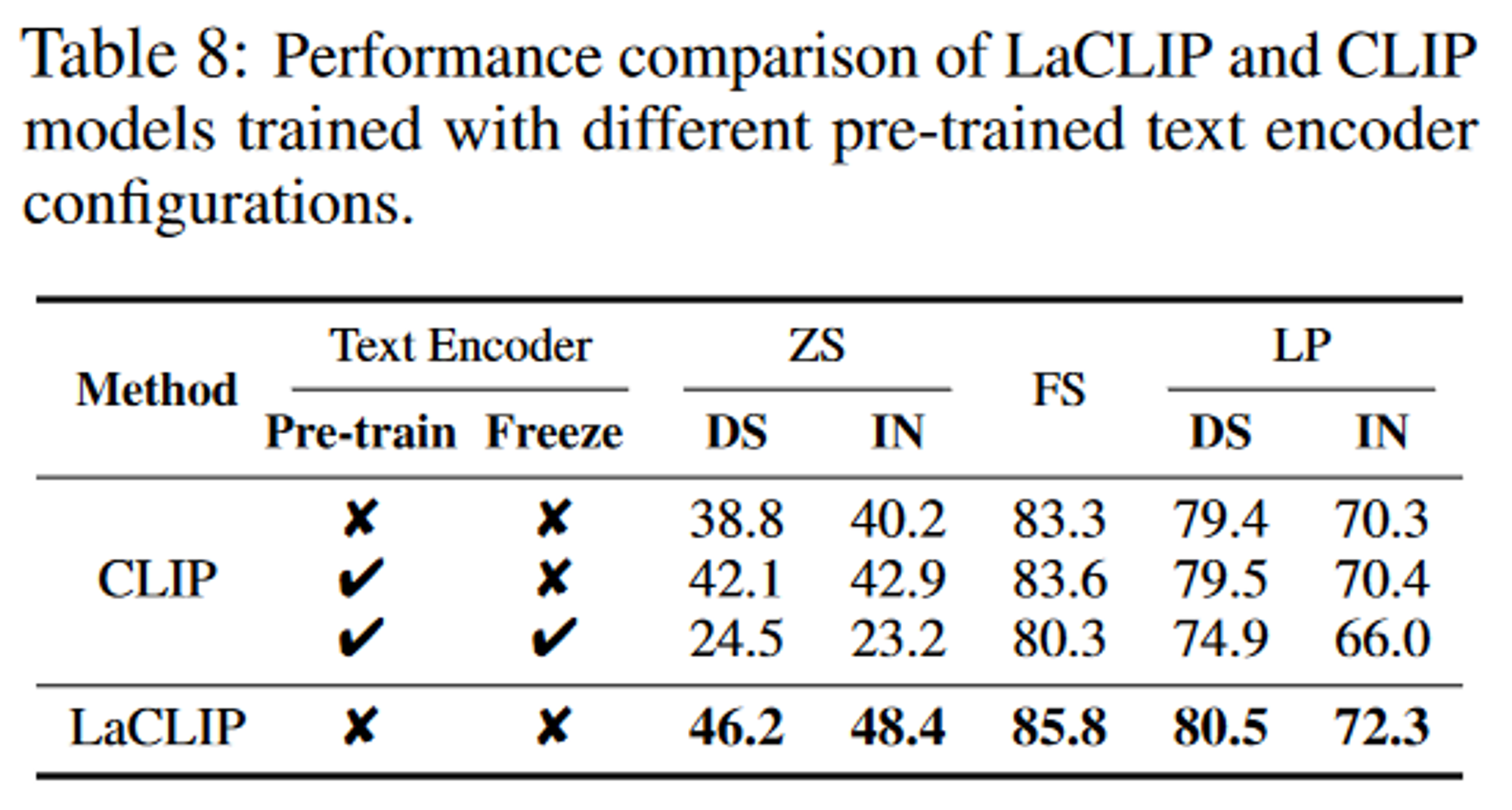
- 预训练文本编码器
结论
贡献:通过文本重写数据增强提高了CLIP的训练效率,另外还提出了一种新的多文本损失的对比学习方法。
限制:本地部署LLM用于文本重写需要大量的GPU资源。
速览笔记
Motivation
CLIP在训练时存在一个问题:对图像使用了数据增强技术,文本部分却没有相应的增强措施。这导致了输入数据的不对称性,可能限制了模型性能。
为了解决这一问题,作者提出了一种新的文本增强方法,利用了大型语言模型(如ChatGPT和Bard)的能力,通过重写文本来增加数据的多样性。这种方法不仅保留了原始文本的结构,而且使得文本内容更加丰富和多样化。此外,论文还引入了一种新型的多文本对比学习方法(LaCLIP-MT),它允许每个图像对应多个文本描述,从而更全面地捕捉图像和文本间的关联,进一步提升模型性能。
Novelty
- 创建点在哪里?为什么要提出来这个?要解决什么问题?
创新点包括:① 利用LLM进行文本数据增强的方法;② 多文本损失对比学习方法。
- 怎么才能想出来这个创新点?想问题的思路是什么?
推测作者的想法
注意到现有的CLIP模型在处理图像和文本时存在不对称性,即只对图像进行数据增强而没有对文本进行类似处理。
这种不平衡可能导致图像编码器从语言方面接受的监督信号较少,而文本编码器由于在每轮训练中遇到相同的文本,增加了过拟合的风险,并可能影响zero-shot迁移能力。
- 怎么就能发这个会议或者这个期刊的?
站在审稿人的角度看论文
感觉创新点不是很多,这种利用LLM对文本进行重写数据增强的方法,应该也不是本文提出的,本文应该只是利用这种方法而已,我不理解为什么能通过。
Methods
对照代码,整理模型整体结构,分析每个模块的作用以及对性能的提升贡献(重点,呼应实验),找到核心模块(提点最多),以及判断跟创新点是否匹配
Experiments
训练集和测试集
用的哪个数据集,规模多少,评价指标是什么
- 预训练数据集:CC3M、CC12M、RedCaps和LAION-400M
- 下游任务数据集

性能如何,好不好复现,是否有Code/Blog/知乎讨论
每个实验证明了什么
有没有哪些实验没有做
跨语言有效性、域外泛化性。
Downsides
哪些提出的模块是有问题的
人工重写的标准是什么?是否跟ChatBots重写限制只能修改3个词对齐?还是完全由人重新想一个。
哪些提出的点对性能提升存疑
有没有能改进的地方
对文本的数据增强方式跟对图片做的数据增强联动,这样就不需要借助LLM来进行数据增强了。
Thinking
能否迁移应用?(业务应用方向、模型改进、数据生产组织等方面)
在数据处理方面,也可以通过LLM来对文本标签进行数据增强。
这篇关于论文精读:Improving CLIP Training with Language Rewrites的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)