clip专题

ACL22--基于CLIP的非代表性新闻图像的多模态检测
摘要 这项研究调查了假新闻如何使用新闻文章的缩略图,重点关注新闻文章的缩略图是否正确代表了新闻内容。在社交媒体环境中,如果一篇新闻文章与一个不相关的缩略图一起分享,可能会误导读者对问题产生错误的印象,尤其是用户不太可能点击链接并消费整个内容的情况下。我们提议使用预训练的CLIP(Contrastive Language-Image Pretraining)表示来捕捉多模态关系中语义不一致的程度。

利用clip模型实现text2draw
参考论文 实践 有数据增强的代码 import mathimport collectionsimport CLIP_.clip as clipimport torchimport torch.nn as nnfrom torchvision import models, transformsimport numpy as npimport webpfrom PIL impor
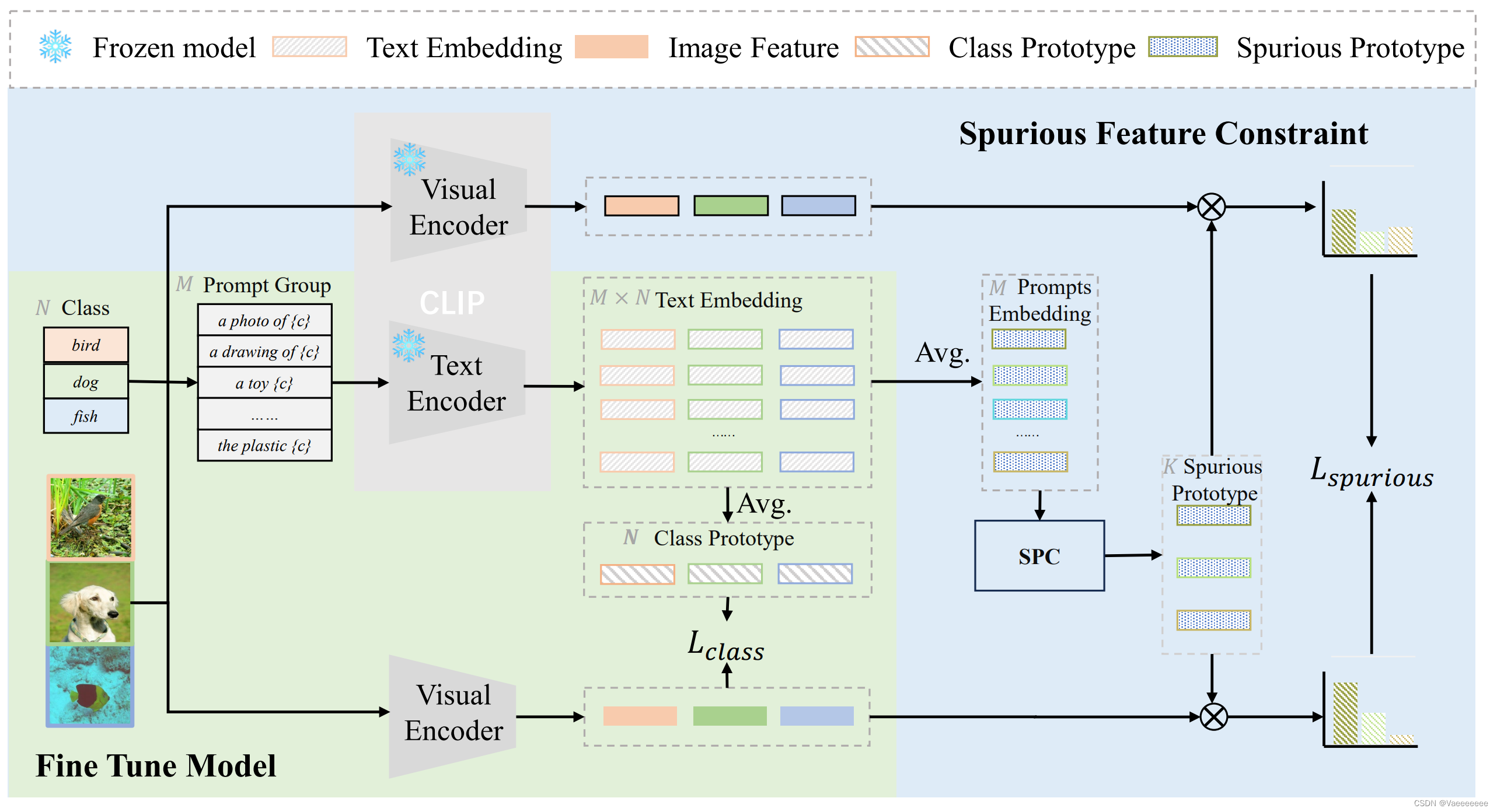
CLIP微调方法总结
文章目录 前言1️⃣ Tip-Adapter论文和源码原理介绍 2️⃣Cross-modal Adaptation(跨模态适应)论文和源码原理介绍 3️⃣ FD-Align(Feature Discrimination Alignment,特征判别对齐)论文和源码原理介绍 总结 前言 本文主要介绍和总结了三种不错的 C L I P CLIP CLIP微调方法,包括原理和思
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇 前情提要源码阅读导包逐行讲解 dataclass部分整体含义逐行解读 模型微调整体含义逐行解读 MultiModal类整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架构中的语言模型部分

适应CLIP作为图像去雾的聚合指导
Adapt CLIP as Aggregation Instructor for Image Dehazing 2408.12317 (arxiv.org) 大多数去雾方法都存在感受野有限的问题,并且没有探索视觉-语言模型中蕴含的丰富语义先验,这些模型已在下游任务中被证明是有效的。 本文介绍了CLIPHaze,这是一个开创性的混合框架,它通过结合Mamba的高效全局建模能力与CLIP
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)](/front/images/it_default.gif)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)
多模态大模型源码阅读 - 语言模型篇(1) 吐槽今日心得MQwen.py 吐槽 想要做一个以Qwen-7B-Insturct为language decoder, 以CLIP-VIT-14为vision encoder的image captioning模型,找了很多文章和库的源码,但是无奈都不怎么看得懂,刚开始打算直接给language decoder加上cross attent

clip-path实现图片边角的裁剪
img {clip-path: polygon(0 7px,7px 0,calc(100% - 20px) 0,100% 20px,100% 100%,16px 100%,0 calc(100% - 16px));} 每一个逗号隔开的就是路径坐标 左上角的两个点 0 7px ,7px 0 右上角 calc(100% - 20px) 0,100% 20px 相当于通过这些点练成的线的圈起来的部分
![[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5](/front/images/it_default.jpg)
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5 前情提要源码解读(visualModel类)init函数整体含义逐行解读 get_image_features函数(重构)整体含义逐行解读 main函数整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架
CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 吐槽 今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~ 学习心得 前情提要 详情请看多模态学习笔记 - 2 上次我们讲到利用view()函数对token_type_ids、position_ids进行重新塑形,确保这些张量的最后

使用AGG里面的clip_box函数裁剪画布, 绘制裁剪后的图形
// 矩形裁剪图片, 透明void agg_testImageClipbox_rgba32(unsigned char* buffer, unsigned int width, unsigned int height){// ========= 创建渲染缓冲区 =========agg::rendering_buffer rbuf;// BMP是上下倒置的,为了和GDI习惯相同,最后一个参数是

QML 圆角矩形 radius clip 对子组件无效的问题解决方法(转载)
原文链接:https://blog.csdn.net/Likianta/article/details/110703819 本文实现前后效果对比: 正文 根据官方的描述, 考虑到性能表现, 父组件的 radius, clip 对子组件是无效的, 也就是说如果外部矩形设置圆角矩形, 对内部矩形的裁剪是无效的, 如下图所示: 下面介绍一种最简单的方案, 使用 layer 属性来实现圆角区
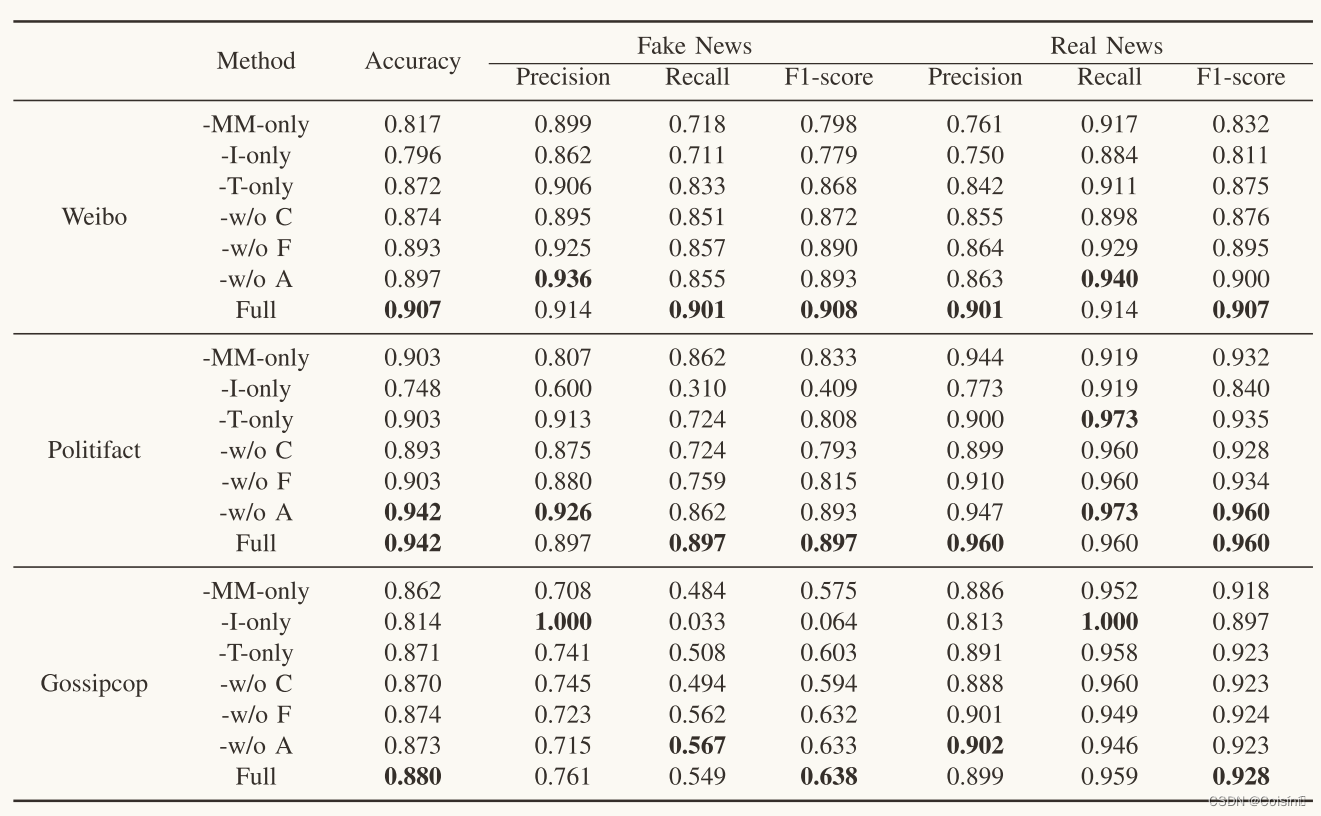
(一篇Blog证明还在地球)论文精读:基于CLIP引导学习的多模态虚假新闻检测
摘要 假新闻检测在社会取证领域引起了广泛的研究兴趣。许多现有的方法引入了定制的注意机制来融合单峰特征。然而,它们忽略了模式之间的跨模式相似性的影响。同时,预训练的多模式特征学习模型在FND中的潜力还没有得到很好的开发。这篇论文提出了一种FND-CLIP框架,即基于对比语言图像预训练(CLIP)的多模式假新闻检测网络。FND-CLIP使用两个单峰编码器和两个成对的CLIP编码器一起从新闻中提取深层

探索CSS clip-path: polygon():塑造元素的无限可能
在CSS的世界里,clip-path 属性赋予了开发者前所未有的能力,让他们能够以非传统的方式裁剪页面元素,创造出独特的视觉效果。其中,polygon() 函数尤其强大,它允许你使用多边形来定义裁剪区域的形状,从而实现各种自定义的图形效果。本文将深入探讨clip-path: polygon()的工作原理、应用场景,并通过实战代码示例带你领略其魅力。 什么是clip-path: polygon()
clip_en的使用学习
代码分析 import torchimport cn_clip.clip as clipfrom PIL import Imagefrom cn_clip.clip import load_from_name, available_modelsprint("Torch version:", torch.__version__)device = "cuda" if torch.cuda.i

Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
标题:用GPT-4增强CLIP:利用视觉描述作为提示 源文链接:Maniparambil_Enhancing_CLIP_with_GPT-4_Harnessing_Visual_Descriptions_as_Prompts_ICCVW_2023_paper.pdf (thecvf.com)https://openaccess.thecvf.com/content/ICCV2023W/MMF
【CSS】background-clip属性的作用是什么,怎么使用?
CSS中的background-clip属性主要用于控制背景的渲染区域,即指定元素背景所在的区域。具体来说,它决定了背景图像或颜色应该在哪些区域被裁剪或显示。 background-clip属性的使用方法: 属性值: border-box:默认值。背景从border区域向外裁剪,即边框以内的区域(包括border)将显示背景,超出部分将被裁剪掉。padding-box:背景从padding区
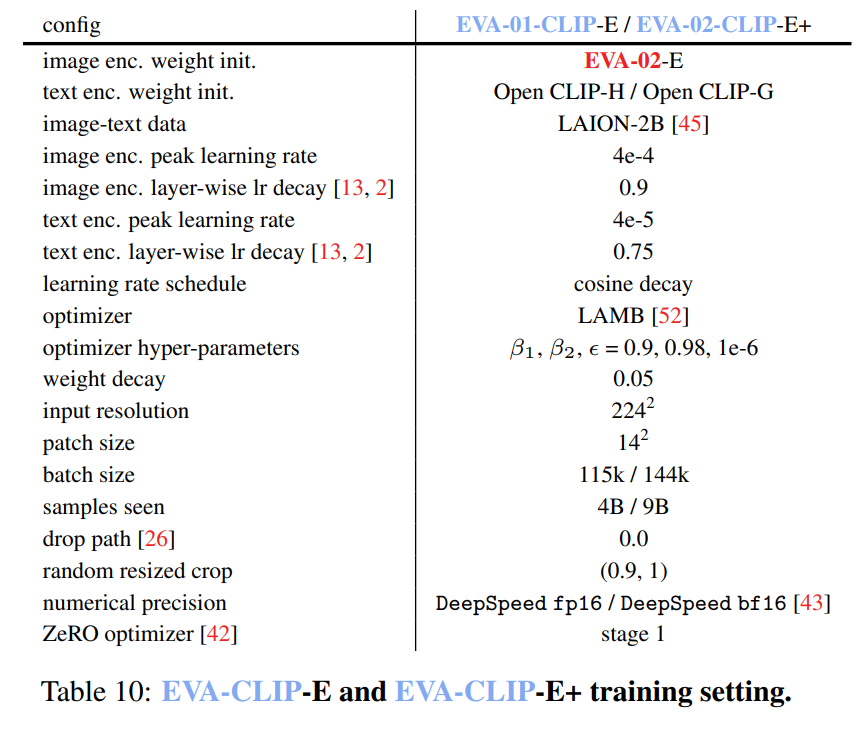
EVA-CLIP:在规模上改进CLIP的训练技术
摘要 对比性语言-图像预训练,简称CLIP,因其在各种场景中的潜力而备受关注。在本文中,我们提出了EVA-CLIP,一系列模型,这些模型显著提高了CLIP训练的效率和有效性。我们的方法结合了新的表示学习、优化和增强技术,使得EVA-CLIP在参数数量相同的情况下,与之前的CLIP模型相比,取得了更优的性能,但训练成本却显著降低。值得注意的是,我们最大的50亿参数的EVA-02-CLIP-E/14

css 剪切属性clip-path
实现效果如下: <!DOCTYPE html><html><head><style>.clipped {width: 200px;height: 200px;background-color: #3498db;clip-path: polygon(0% 0%, 100% 0%, 100% 100%, 30% 100%);}</style></head><body><div class="cl
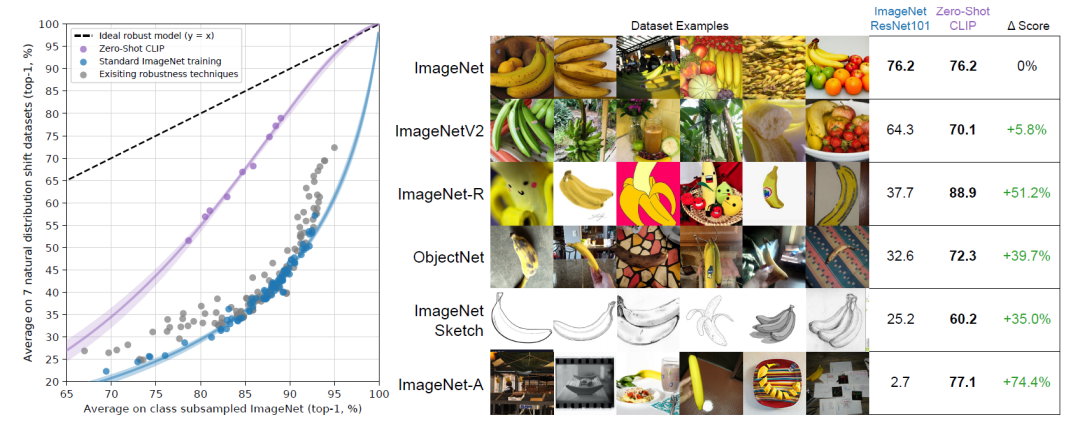
ViT:2 理解CLIP
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 语言-图像对比的预训练模型(CLIP)是由OpenAI开发的多模态学习架构
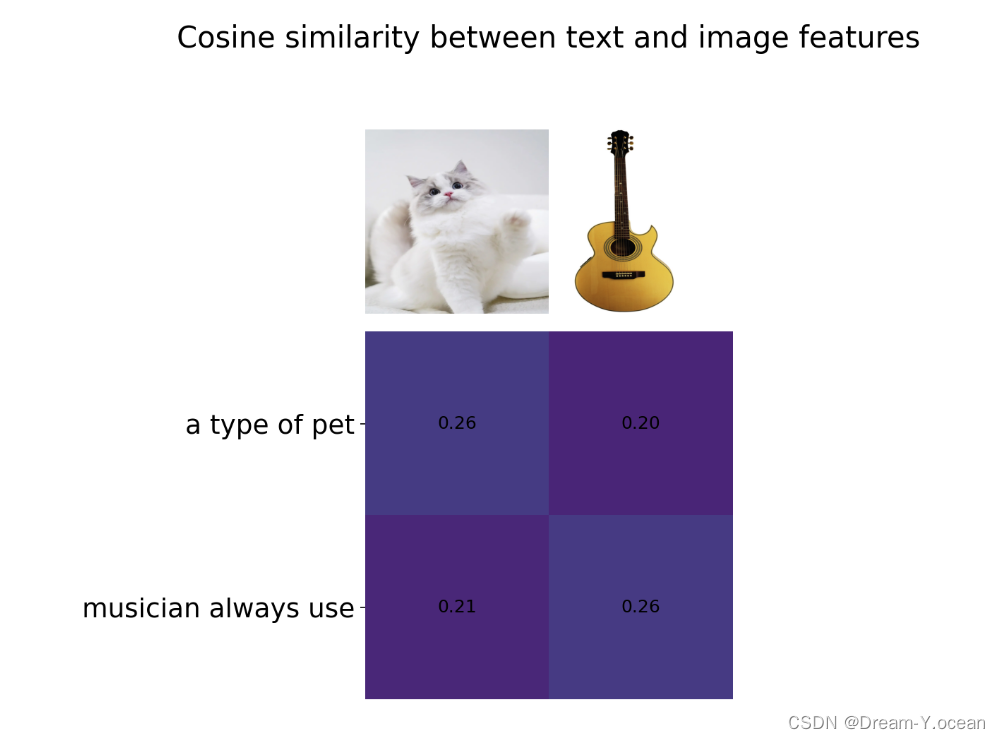
⌈ 传知代码 ⌋ 【CLIP】文本也能和图像配对
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!! 以下内容干货满满,跟上步伐吧~ 📌导航小助手📌 💡本章重点🍞一. 概述🍞二. 算法介绍🍞三. 演示效果🍞四. 核心逻辑🫓总结
[CLIP] Learning Transferable Visual Models From Natural Language Supervision
通过在4亿图像/文本对上训练文字和图片的匹配关系来预训练网络,可以学习到SOTA的图像特征。预训练模型可以用于下游任务的零样本学习 1、网络结构 1)simplified version of ConVIRT 2)linear projectio

CSS3 clip-path:打造独特创意设计效果的秘密武器
100编程书屋_孔夫子旧书网 一部由CSS技术实现的作品。它将再一次证明CSS的强大力量。 欣赏 这是一部由阿姆斯特丹设计师Bryan James通过30张CSS碎片拼图展现30种濒临灭绝动物的网站。 有生活在夏威夷岛林地中的夏威夷乌鸦。 有栖息于墨西哥西部加利福尼亚湾中的小头鼠海豚。 原产于巴西大西洋沿岸地区的金狮面狨。 印度中部繁殖生活的林斑小鸮

【CSS】clip-path 属性详解
目录 基本语法值几何形状SVG 引用URL 引用 示例结合动画 clip-path 属性用于在 SVG 和 HTML 中创建复杂的裁剪区域(即剪切路径),从而只显示元素的一部分。 基本语法 selector {clip-path: value;} 值 clip-path 属性接受以下类型的值: 几何形状 circle(): 定义一个圆形。 clip-path:

(Arxiv,2023)CLIP激活的蒸馏学习:面向开放词汇的航空目标检测技术
文章目录 相关资料摘要引言方法问题描述开放词汇对象探测器架构概述类不可知框回归头语义分类器头 定位教师指数移动平均一致性训练与熵最小化边界框选择策略 动态伪标签队列生成伪标签维护队列 混合训练未标记数据流队列数据流 实验 相关资料 论文:Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Stud

如何设置让背景颜色不包括 padding 部分,顺带全面学习 background-clip 属性(可以实现文字渐变)
先解决需求 实现背景颜色不包括 padding 部分,直接给容器添加 css 属性:background-clip:content-box; 示例代码: .content-box-example {background-color: lightblue;padding: 20px;border: 1px solid black;background-clip: content-box;}