本文主要是介绍ViT:2 理解CLIP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
语言-图像对比的预训练模型(CLIP)是由OpenAI开发的多模态学习架构。它从自然语言监督中学习视觉概念。它通过在包含图像及其相应文本描述的大规模数据集上联合训练模型来弥合文本和视觉之间的差距。

对比学习
对比学习是机器学习中经常使用的技术,特别是在无监督学习领域。对比学习教 AI模型识别大量数据的异同。
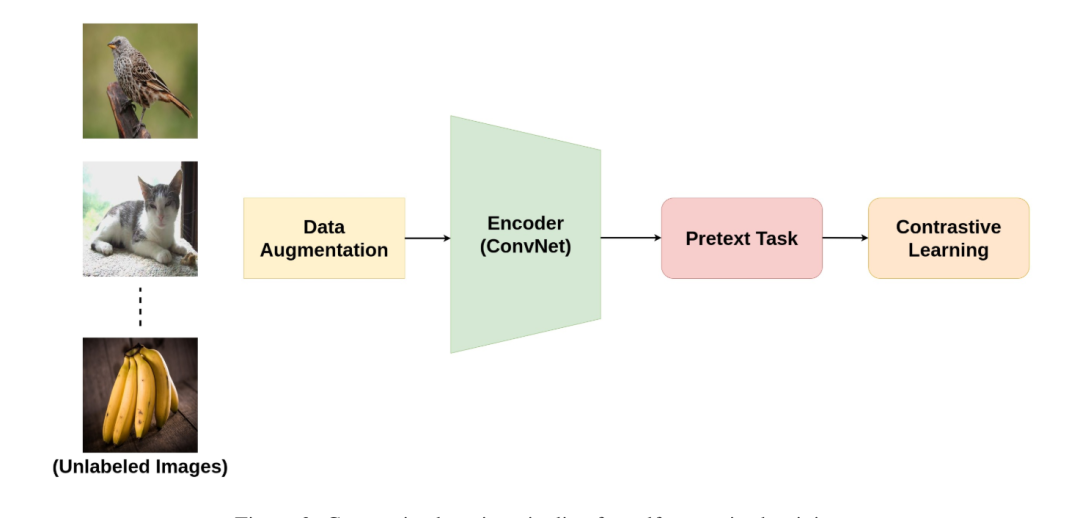
上图为对比学习的pipeline管道。
假设存在一个主体、一个相似的主体(正样本)和一个不同的主体(负样本)。对比学习的目标是让模型理解主体和相似主体的关联性,同时将主题和负样本最大程度的推开。其实也很好理解,假如识别苹果,可以给模型一堆的不同角度的苹果照片(正样本),让模型能够从多角度的认识很识别苹果。而其余品类的照片都是负样本。
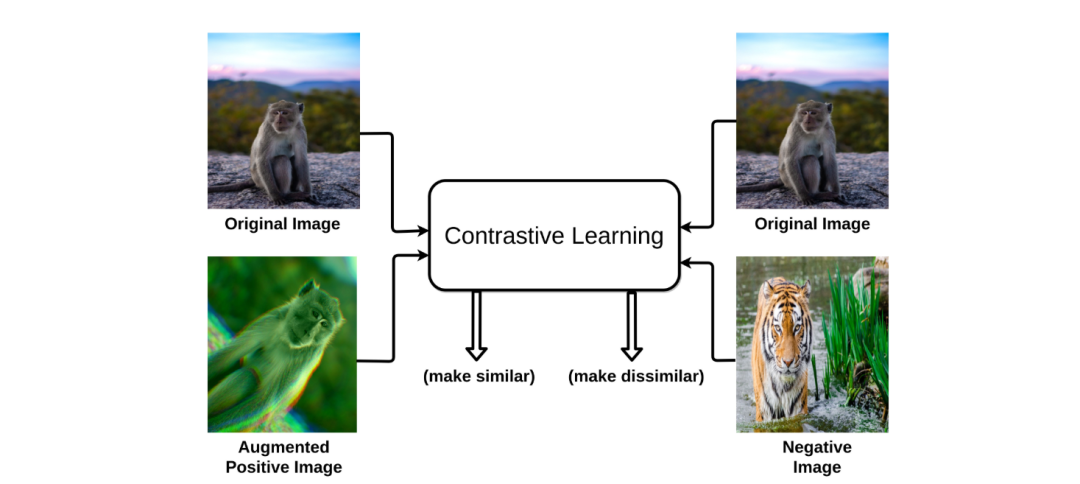

CLIP 架构

CLIP使用双编码器架构将图像和文本映射到共享的潜在空间中。它通过联合训练两个编码器来工作。一个用于图像的编码器(Vision Transformer)和一个用于文本的编码器(基于Transformer的语言模型)。
图像编码器从视觉输入中提取显著特征。该编码器将“图像作为输入”并生成高维矢量表示。它通常使用卷积神经网络 (CNN) 架构(如 ResNet)来提取图像特征。文本编码器:文本编码器对相应文本描述的语义含义进行编码。它采用“文本标题/标签作为输入”并生成另一个高维向量表示。它通常使用基于 Transformer 的架构(如 Transformer 或 BERT)来处理文本序列。共享嵌入空间:两个编码器在共享矢量空间中生成嵌入。这些共享嵌入空间允许 CLIP 比较文本和图像表示并了解它们的基本关系。
CLIP 在从互联网上收集的 4 亿对(图像、文本)的大规模数据集,并在这些数据集上面进行预训练。在预训练期间,模型会被喂给有图像和文本标题配对组成的样本。其中有些是正匹配(标题准确地描述了图像),而另一些则是负匹配。CLIP对每幅图像都会创造多个文本,有些是正,有些是负。将这些创建的正样本(匹配)和负样本(不匹配)对的混合。
预训练阶段对比损失函数起到关键的作用。模型会根据学习的结果进行对应的奖惩,进而鼓励模型学习到视觉和文本信息的相似性。经过训练的文本编码器被用作zero-shot的分类器。CLIP计算所有图像和文本描述对的嵌入之间的余弦相似度,进而优化了编码器的参数,以便于提升正确对的相似性。因此CLIP学习到一个多模态嵌入空间,其中语义相关的图像和文本彼此靠近。

运用场景
即然CLIP已经将图像和文本映射到共享空间中,那么就可以集成NLP和图像处理任务。

-
这允许CLIP生成图像的文本描述,通过查询具有图像的嵌入表示,从训练数据中检索相关的文本描述,高效的为图像生成标题。
-
同时CLIP可以根据文本描述对图像进行分类。直接将文本描述与潜在空间中看不见的图像进行比较。无需为特定类添加标记训练数据即可执行零样本图像分类。
-
基于这个基础模型还可以根据文本的提示“编辑”图像。用户可以操纵文本输入并将其反馈到CLIP中,为创新的文本到图像生成和“编辑”工具奠定了基础。
|
|
|


传统的视觉模型擅长于物体检测和图像分类等任务。然而,往往难以掌握图像中更深层次的含义和背景。CLIP 可以理解图像中描绘的物体、活动和情感之间的关系。给定一对情侣在公园互相打闹的图像,CLIP可以识别情侣的存在,还可以它们的情绪。而且CLIP可以从更少的图像-文本对中学习,使得它更加节省资源,并适用于数据有限的专业领域。
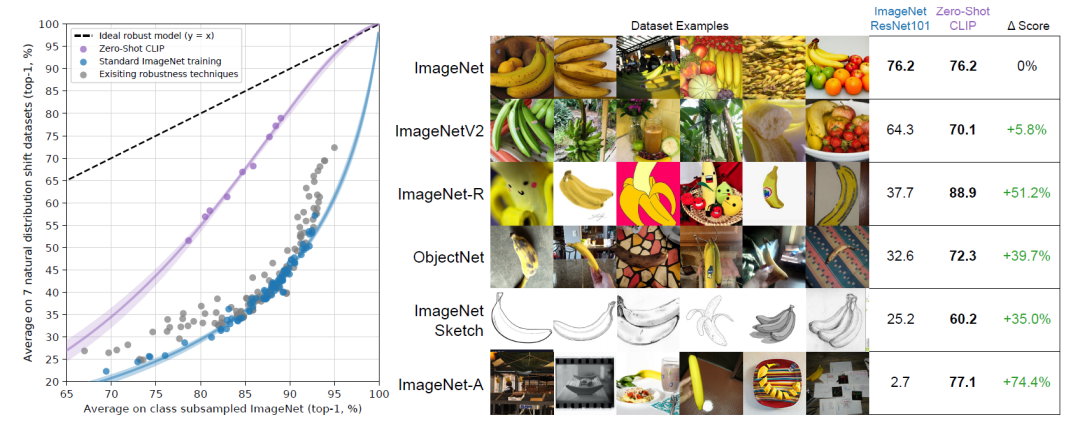
CLIP 最令人印象深刻的功能之一是它能够执行zero-shot的图像分类。这意味着 CLIP 可以仅使用自然语言描述对以前从未见过的图像进行分类,下图展示其强大的效果。
CLIP的另一个应用是将其用作多模态学习系统的组件。这些可以组合不同类型的数据,例如文本和图像。例如,它可以与 DALL-E 等生成模型配对。它从文本输入创建图像,以产生逼真和多样化的结果。它也可以根据文本命令编辑现有图像,例如更改对象的颜色、形状或样式。这使用户能够傻瓜式的创造性地创建和操作图像。
聪明的读者可以会想到其实在审核场景下,CLIP也是可以大展拳脚的。它可以帮助审核来自在线平台的不当或有害内容,例如包含暴力、裸露或仇恨言论的图片。CLIP 可以通过根据自然语言标准检测和标记此类内容来协助内容审核过程。例如,它可以识别违反平台服务条款或社区准则图像,或者对某些群体或个人具有攻击性或敏感性的图像。更加智能的地方在于它可以通过突出显示触发审核的图像或文本的相关部分来证明决策的合理性。
CLIP在图像识别、NLP、医疗诊断、辅助技术、先进机器人等领域取得突破,它为更直观的人机交互铺平了道路,因为机器可以跨不同模式掌握上下文理解。但是它对人际关系的理解,尤其是情感和抽象概念,仍然受到限制。它可能会误解复杂或细微的视觉线索。因此也会影响它在需要更深入地了解人类的任务表现。
这篇关于ViT:2 理解CLIP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








